
【AI-CAMP四期】第八组作业
杜磊的作业
第一周作业
统计

图片

代码
#coding:utf-8
import boto3
import cv2
import nori2 as nori
import numpy as np
from imgaug import augmenters as iaa
from meghair.utils.imgproc import imdecode
s3_client = boto3.client('s3', endpoint_url="http://oss.i.brainpp.cn")
bucket = "ai-cultivate"
key="1percent_ImageNet.txt"
# 从 s3 读取文件,并将其转换成 mat 矩阵: numpy.ndarray
def read_img(bucket, key):
resp = s3_client.get_object(Bucket=bucket, Key=key)
#print(resp)
res = resp['Body'].read().decode('utf8')
data = res.split('\n')
nori_ids = list(map(lambda x: x.split('\t')[0], data))[-20::2] # 从倒数第20个开始,步长为2,取到最后一个
print(nori_ids)
fetcher = nori.Fetcher()
img_list = list(map(lambda x: imdecode(fetcher.get(x)), nori_ids)) # imdecode 将文件转成 mat 矩阵格式
return img_list
# 统计图片的大小 ,平均高度、最大高度、最小高度、平均宽度、最大宽度、最小宽度
def get_img_statistics(img_list):
img_size_list = []
for i, img in enumerate(img_list):
img_size_list.append({"img_num": "img_{}".format(i), "height": img.shape[0], "width": img.shape[1]})
height_list = [img_size['height'] for img_size in img_size_list]
width_list = [img_size['width'] for img_size in img_size_list]
# 求高度的平均值
avg_height = np.mean(height_list)
max_height = max(height_list)
min_height = min(height_list)
avg_width = np.mean(width_list)
max_width = max(width_list)
min_width = min(width_list)
img_info = {
'avg_height': avg_height,
'max_height': max_height,
'min_height': min_height,
'avg_width': avg_width,
'max_width': max_width,
'min_width': min_width,
'img_size': img_size_list
}
print("image statistic result: {}".format(img_info))
# 图片增强
def enhance_img(img_list):
H, W = 128, 128
NUM = 6 # 每张图要变换的张数
seq = iaa.Sequential([
iaa.Fliplr(0.5), # 对50%的图像进行翻转
iaa.Affine(
scale = {"x": (0.8, 1.2), "y": (0.8, 1.2)},
translate_px = {"x": (-16, 16), "y": (-16,16)},
rotate = (-45, 45)
),
iaa.GaussianBlur(sigma=(0, 2.0)),
iaa.Resize({"height": H, "width": W})
], random_order=True)
res = np.zeros(shape=((H + 10)* len(img_list), (W + 10)*NUM, 3),dtype = np.uint8)
for i, img in enumerate(img_list):
img_array = np.array([img] * NUM, dtype = np.uint8)
write_img = np.zeros(shape=(H, (W + 10)*NUM, 3), dtype=np.uint8)
images_aug = seq.augment_images(images=img_array)
for j, item in enumerate(images_aug):
write_img[:, j * (W+10): j * (W+10) + W, :] = item
res[i * (H+10): i*(H+10) + H, :, :] = write_img
# 将结果写到一张图中
#cv2.imshow("result", res)
cv2.imwrite('result.jpg', res)
if __name__ == '__main__':
img_list = read_img(bucket, key)
get_img_statistics(img_list)
enhance_img(img_list)






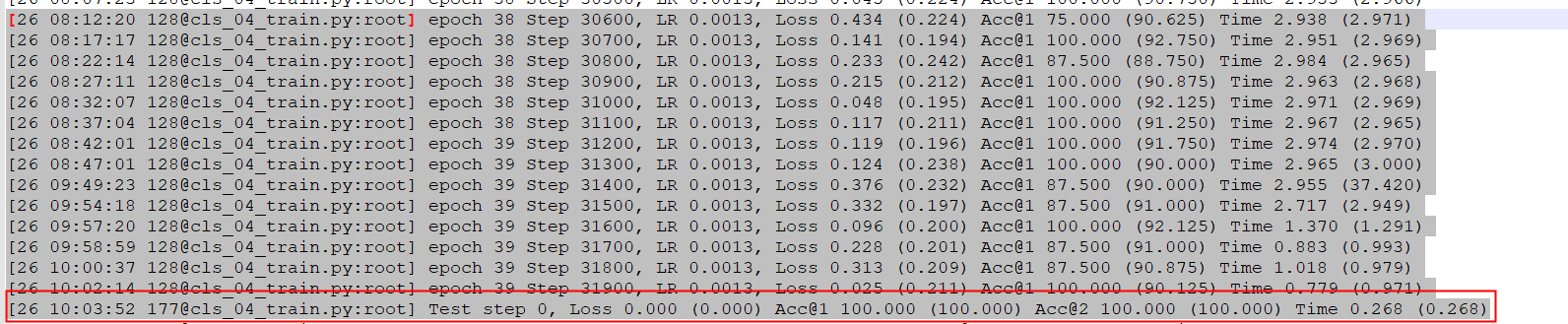


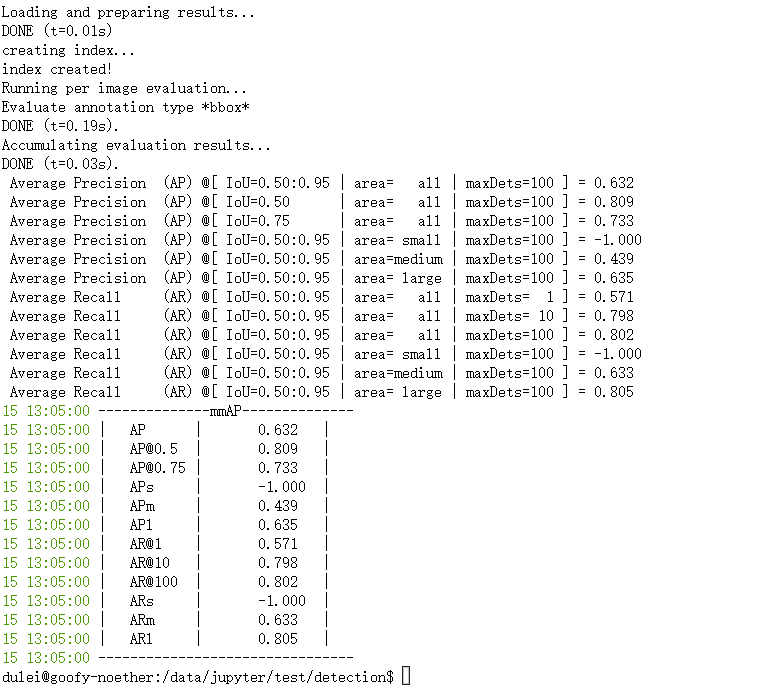

实践作业
参加智慧交通开源比赛
https://studio.brainpp.com/competition/4?name=旷视AI智慧交通开源赛道
李祯的作业
第一周作业
代码
import boto3
import nori2 as nori
import cv2
import numpy as np
import imgaug as ia
import imgaug.augmenters as iaa
from meghair.utils.imgproc import imdecode
fetcher = nori.Fetcher()
def import_data(bucket, key):
host = "http://oss.i.brainpp.cn"
s3_client = boto3.client('s3', endpoint_url=host)
obj = s3_client.get_object(Bucket=bucket, Key=key)
body = obj["Body"].read().decode("utf-8")
body_list = body.split("\n")
return body_list
def getImageMessage(datas):
n = []
imgs = []
widths = []
heigths = []
for line in datas:
nid = str(line.split("\t")[0]).split("'")[0]
img = imdecode(fetcher.get(nid))[..., :3]
n.append(nid)
imgs.append(img)
widths.append(img.shape[0])
heigths.append(img.shape[1])
if len(n) > 10:
break
print("max_height={}, min_height={}, avg_height={}, max_width={},min_width={}, avg_width={}"
.format(np.max(heigths), np.min(heigths), np.mean(heigths), np.max(widths), np.min(widths), np.mean(widths)))
def enhanceImage(datas):
num, width, height = 4, 256, 256
sqrt = int(num ** 0.5)
seq = iaa.Sequential([
iaa.Fliplr(0.2),
iaa.Crop(px=(0, 16)),
iaa.Affine(
scale={"x": (0.8, 1.2), "y": (0.8, 1.2)},
translate_percent={"x": (-0.2, 0.2), "y": (-0.2, 0.2)},
rotate=(-45, 45)
),
iaa.Resize({"height": height, "width": width})
])
img = imdecode(fetcher.get(str(datas[50].split("\t")[0]).split("'")[0]))[..., :3]
images = np.array([img] * num, dtype=np.uint8)
images_aug = seq(images=images)
write_img = np.zeros((height * sqrt, (width + 10) * sqrt, 3), dtype=np.uint8)
j = -1
for i, img in enumerate(images_aug):
offset = i % sqrt
if offset == 0:
j += 1
write_img[j*height:(j*height) + height, offset * (width + 10):(offset * (width + 10)) + width, :] = img
cv2.imwrite("output.jpeg", write_img)
if __name__ == '__main__':
datas = import_data('ai-cultivate', '1percent_ImageNet.txt')
getImageMessage(datas)
enhanceImage(datas)
结果

第二周作业
(1)个人作业
核心代码:
# 随机生成数据
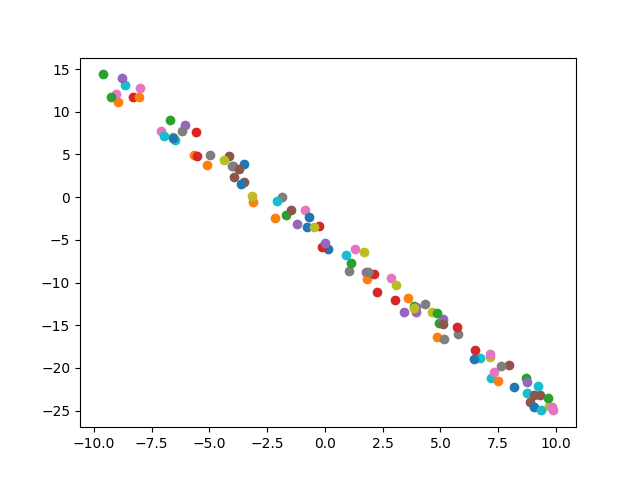
def generate_random_examples(n=100, noise=5):
w = np.random.randint(5, 10)
b = np.random.randint(-10, 10)
data = np.zeros((n, ))
label = np.zeros((n, ))
for i in range(n):
data[i] = np.random.uniform(-10, 10)
label[i] = w * data[i] + b + np.random.uniform(-noise, noise)
plt.scatter(data[i], label[i], marker=".")
return data, label
# 参数、模型、优化器
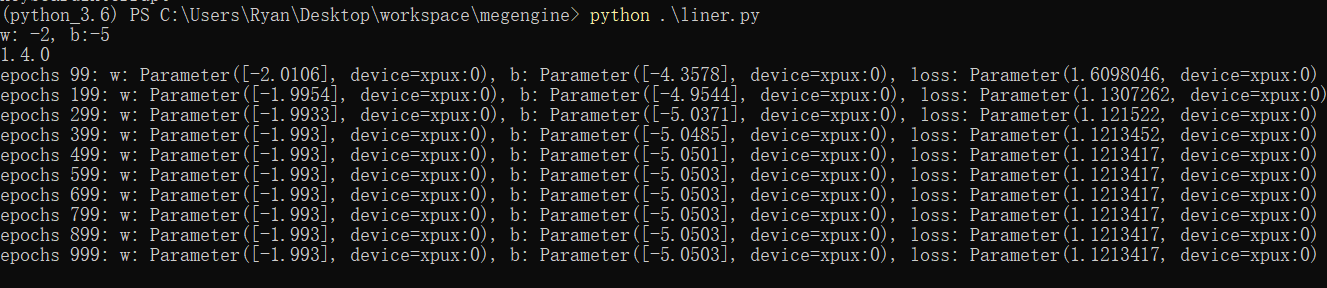
epochs = 100
lr = 0.01
w = mge.Parameter([0.0])
b = mge.Parameter([0.0])
def linear_model(x):
return F.mul(w, x) + b
gm = GradManager().attach([w, b])
optimizer = optim.SGD([w, b], lr=lr)
# 训练
for epoch in range(epochs):
with gm:
pred = linear_model(data)
loss = F.loss.square_loss(pred, label)
gm.backward(loss)
optimizer.step().clear_grad()
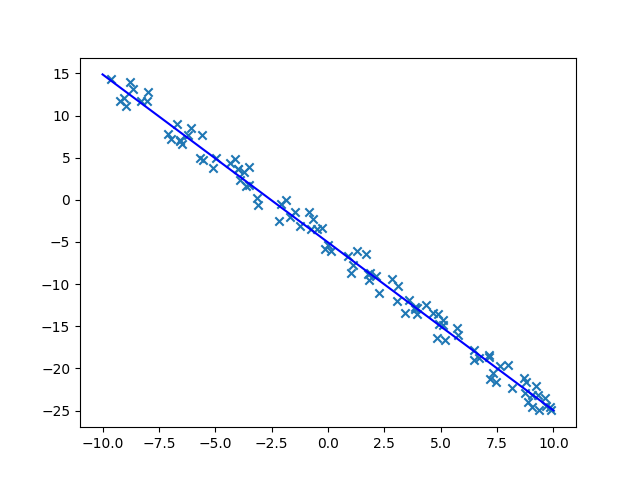
x = np.array([-10, 10])
y = w.numpy() * x + b.numpy()
结果

(2)小组作业
训练代码:
from megengine.data.dataset import MNIST
import megengine.module as M
import megengine.functional as F
from megengine.jit import trace
import time
import numpy as np
import megengine as mge
from megengine.optimizer import SGD
from megengine.autodiff import GradManager
from megengine.data import DataLoader
from megengine.data.transform import ToMode, Pad, Normalize, Compose
from megengine.data.sampler import RandomSampler
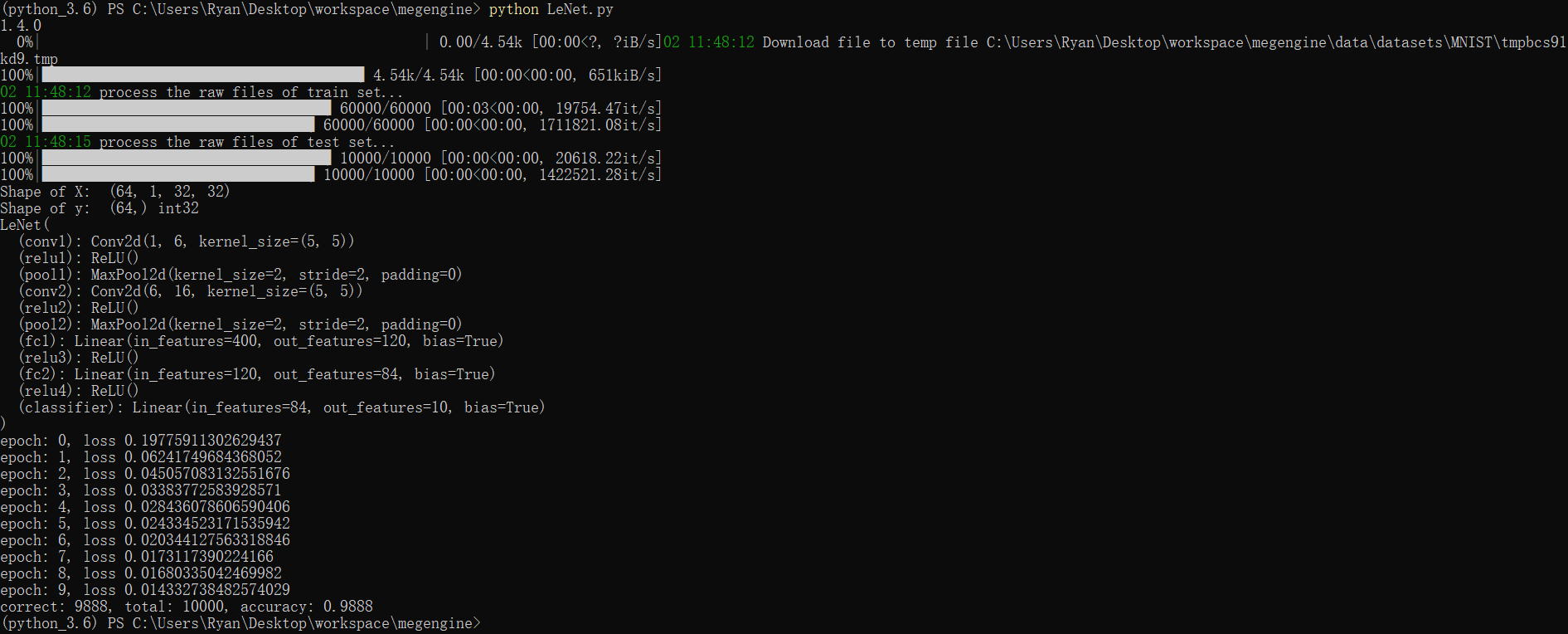
class Net(M.Module):
def __init__(self):
super().__init__()
self.conv0 = M.Conv2d(1, 20, kernel_size=5, bias=False)
self.bn0 = M.BatchNorm2d(20)
self.relu0 = M.ReLU()
self.pool0 = M.MaxPool2d(2)
self.conv1 = M.Conv2d(20, 20, kernel_size=5, bias=False)
self.bn1 = M.BatchNorm2d(20)
self.relu1 = M.ReLU()
self.pool1 = M.MaxPool2d(2)
self.fc0 = M.Linear(500, 64, bias=True)
self.relu2 = M.ReLU()
self.fc1 = M.Linear(64, 10, bias=True)
def forward(self, x):
x = self.conv0(x)
x = self.bn0(x)
x = self.relu0(x)
x = self.pool0(x)
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.pool1(x)
x = F.flatten(x, 1)
x = self.fc0(x)
x = self.relu2(x)
x = self.fc1(x)
return x
@trace(symbolic=True)
def train_func(data, label, *, gm, net):
net.train()
with gm:
pred = net(data)
loss = F.loss.cross_entropy(pred, label)
gm.backward(loss)
return pred, loss
@trace(symbolic=True)
def eval_func(data, label, *, net):
net.eval()
pred = net(data)
loss = F.loss.cross_entropy(pred, label)
return pred, loss
train_dataset = MNIST(root="./dataset/MNIST", train=True, download=True)
test_dataset = MNIST(root="./dataset/MNIST", train=False, download=False)
# 读取训练数据并进行预处理
dataloader = DataLoader(
train_dataset,
transform=Compose([
Normalize(mean=0.1307*255, std=0.3081*255),
Pad(2),
ToMode('CHW'),
]),
sampler=RandomSampler(dataset=train_dataset, batch_size=64),
)
# 实例化网络
net = Net()
# SGD优化方法,学习率lr=0.01,动量momentum=0.9
optimizer = SGD(net.parameters(), lr=0.01, momentum=0.9, weight_decay=5e-4)
gm = GradManager().attach(net.parameters())
total_epochs = 10
for epoch in range(total_epochs):
total_loss = 0
for step, (batch_data, batch_label) in enumerate(dataloader):
batch_label = batch_label.astype(np.int32)
optimizer.clear_grad() # 将参数的梯度置零
pred, loss = train_func(mge.tensor(batch_data), mge.tensor(batch_label), gm=gm, net=net)
optimizer.step() # 根据梯度更新参数值
total_loss += loss.numpy().item()
print("epoch: {}, loss {}".format(epoch, total_loss/len(dataloader)))
mge.save(net.state_dict(), 'mnist_net.mge')
net = Net()
state_dict = mge.load('mnist_net.mge')
net.load_state_dict(state_dict)
测试代码:
from megengine.data.sampler import SequentialSampler
# 测试数据
test_sampler = SequentialSampler(test_dataset, batch_size=500)
dataloader_test = DataLoader(
test_dataset,
sampler=test_sampler,
transform=Compose([
Normalize(mean=0.1307*255, std=0.3081*255),
Pad(2),
ToMode('CHW'),
]),
)
correct = 0
total = 0
for idx, (batch_data, batch_label) in enumerate(dataloader_test):
batch_label = batch_label.astype(np.int32)
pred, loss = eval_func(mge.tensor(batch_data), mge.tensor(batch_label), net=net)
predicted = pred.numpy().argmax(axis=1)
correct += (predicted == batch_label).sum().item()
total += batch_label.shape[0]
print("correct: {}, total: {}, accuracy: {}".format(correct, total, float(correct) / total))
结果:

![]()

刘泽民的作业
第一周作业
- 备注:
- ws2一直没有申请到资源,使用megstudio完成作业,但在megstudio中cv2.imshow方法图片显示不出来,而plt.imshow方法显示图片会将前面图片覆盖,故结果中只有一张图片,另外CIFAR10中图片都是32*32的,使用数据增强参数调的大时,图片变化有点大
- 代码:
- from megengine.data.dataset import CIFAR10
from megengine.data import DataLoader
from megengine.data.sampler import SequentialSampler
import numpy as np
import cv2
import matplotlib.pyplot as plt # 显示图片(cv2在这不能显示图片)
from imgaug import augmenters as iaace_dataset = CIFAR10(root="./test_batch", train=True, download=True) # 读取CIFAR10中测试数据集作为数据来源
ce_sampler = SequentialSampler(ce_dataset, batch_size=1)
dataloader_ce = DataLoader(
ce_dataset,
sampler=ce_sampler
)def image_statistics():
image_count = 0 # 图片个数统计 avg_w = 0 # 平均宽度 avg_h = 0 # 平均高度 max_w = 0 # 最大宽度 max_h = 0 # 最大高度 min_w = 1000000 # 最小宽度 min_h = 1000000 # 最小高度 # batch设置为1 for idx, (batch_data, batch_label) in enumerate(dataloader_ce): img_w = batch_data.shape[1] img_h = batch_data.shape[1] avg_w += img_w avg_h += img_h if img_w > max_w: max_w = img_w if img_h > max_h: max_h = img_h if img_w < min_w: min_w = img_w if img_h < min_h: min_h = img_h image_count += 1 avg_w = avg_w / image_count avg_h = avg_h / image_count print('statistics result: count: {0}, avg_w:{1}, avg_h:{2}, max_w: {3}, max_h: {4}, min_w: {5}, min_h: {6}'.format(image_count, avg_w, avg_h, max_w, max_h, min_w, min_h))def image_preprocessing():
count = 0; # 临时变量 进行计数 # 对10张图片进行预处理 以演示功能 for idx, (batch_data, batch_label) in enumerate(dataloader_ce): img_original = batch_data[0] plt.imshow(img_original) # cv2.imshow("original", img_original) # cv2.imwrite("./original_1.jpg", img_original) # 图片增强公式 seq = iaa.Sequential([ iaa.Crop(px=(0, 2)), iaa.Fliplr(0.5), ]) img_aug = seq.augment_images(img_original) plt.imshow(img_aug) # cv2.imshow("aug", img_aug) count += 1 if count > 10: breakif name == “main”:
image_statistics() # 图片数据基本统计 image_preprocessing() # 图片数据预处理</dd> - 结果: 
第二周作业
-
import math
import numpy as np
import matplotlib.pyplot as plt
import megengine as mge
import megengine.functional as F
from megengine.autodiff import GradManager
import megengine.optimizer as optim
epochs = 100 # 迭代次数
lr = 0.02 # 学习速率
初始化模型参数
w = mge.Parameter([0.0])
b = mge.Parameter([0.0])
求导器
gm = GradManager().attach([w, b])
优化器
opt = optim.SGD([w, b], lr=lr)
生成样本数据
def Generate_ExamplesData(dataSize, noise):
w_examp = np.random.randint(1, 5)
b_examp = np.random.randint(-10, 10)
data = np.zeros((dataSize,))
label = np.zeros((dataSize,))
for i in range(dataSize):
data[i] = np.random.uniform(-10, 10)
label[i] = w_examp * math.sin(data[i]) + b_examp + np.random.uniform(-noise, noise)
# plt.scatter(data[i], label[i], marker=".")
return data, label
线性模型
def Line_Model(x):
# x1 = math.sin(x)
x1 = F.sin(x)
y = F.mul(w, x1) + b
return y
模型训练
def Model_Train(data, label):
for epoch in range(epochs):
with gm:
pred = Line_Model(data)
loss = F.loss.square_loss(pred, label)
gm.backward(loss)
opt.step().clear_grad()
print("epoch:{}, w:{:.3f}, b:{:.3f}, loss:{:.3f}".format(epoch, w.item(), b.item(), loss.item()))
测试训练完的模型
def Model_Test():
x_test = np.random.uniform(-10, 10, 100)
tensor_x = mge.tensor(x_test)
tensor_y = Line_Model(tensor_x)
return tensor_x, tensor_y
if name == “main”:
# 生成训练数据
data,label = Generate_ExamplesData(400, 0.5)
# 数据类型转换
tensor_data = mge.tensor(data)
tensor_label = mge.tensor(label)
# 进行模型训练
Model_Train(tensor_data, tensor_label)
# 验证模型训练结果
text_x, result_y = Model_Test()
plt.scatter(data, label, 3, "red")
plt.scatter(text_x, result_y, 3, "green")
plt.plot()
plt.show()
第二周作业结果:
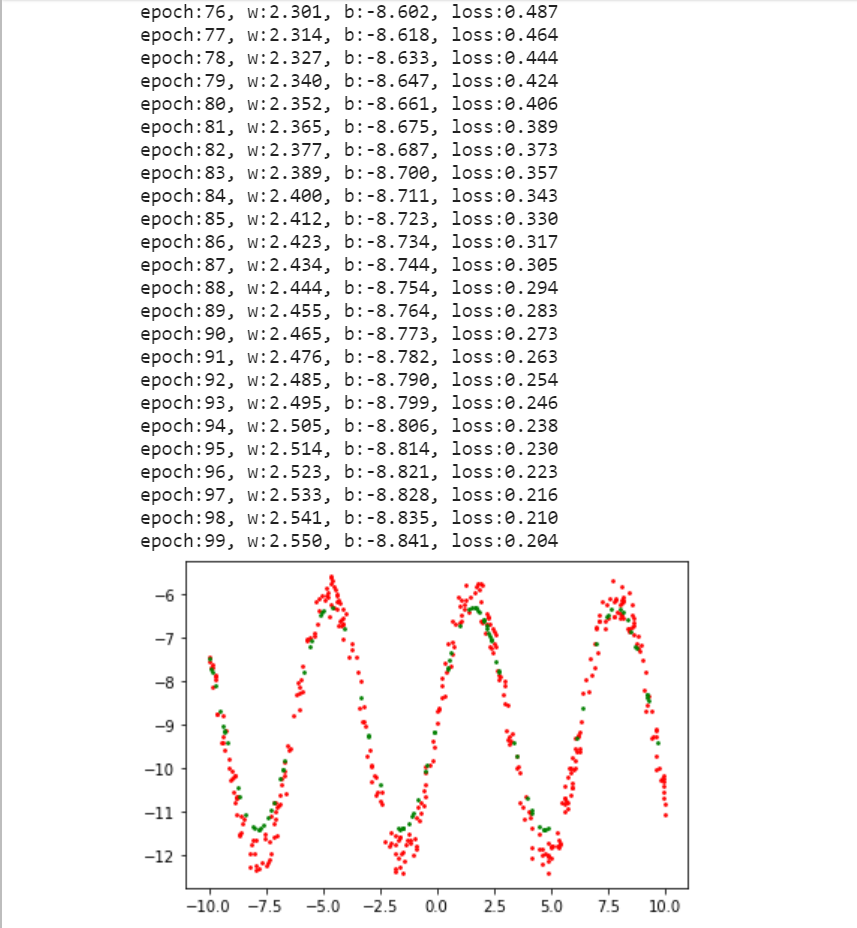
第三周作业
个人作业
爬充气拱门数据代码
import requests
import json
import urllib
def getBaiduImag(pn, rn, path):
m = pn
str_url = 'https://pic.sogou.com/napi/pc/searchList?mode=1&start='+ str(pn) +'&xml_len='+ str(rn) +'&query=%E5%85%85%E6%B0%94%E6%8B%B1%E9%97%A8'
imgs = requests.get(str_url)
jd = json.loads(imgs.text)
jd = jd['data']
jd = jd['items']
imgs_url = []
for j in jd:
imgs_url.append(j['oriPicUrl'])
for img_url in imgs_url:
print('***** '+str(m)+'.jpg *****'+' Downloading...')
try:
urllib.request.urlretrieve(img_url,path+str(m)+'.jpg')
except:
pass
m = m + 1
batch = 10
batch_size = 30
for i in range(batch):
getBaiduImag(i * batch_size, batch_size, './images/')
print(‘Download complete!’)
数据截图:
数据标注需求文档截图:


袁文涛的作业
通过 megstudio 提交作业
- 第一周作业
import matplotlib.pyplot as plt
import numpy as np
from imgaug import augmenters as iaa
def img_aug(imgs):
seq = iaa.Sequential(
[
iaa.Crop(px=(0,16)),
iaa.Affine(
rotate=(-45, 45),
)
],
random_order=True
)
return seq.augment_images(imgs)
def unpickle(file):
import pickle
with open(file, ‘rb’) as fo:
dict = pickle.load(fo, encoding=‘bytes’)
return dict
def GetPhoto(pixel):
assert len(pixel) == 3072
# 对list进行切片操作,然后reshape
r = pixel[0:1024]; r = np.reshape(r, [32, 32, 1])
g = pixel[1024:2048]; g = np.reshape(g, [32, 32, 1])
b = pixel[2048:3072]; b = np.reshape(b, [32, 32, 1])
photo = np.concatenate([r, g, b], -1)
return photo
随机选择图片,每个batch选择3个,共15张
images =
for i in range(1, 1+5):
tmp = unpickle("./dataset/cifar-10-batches-py/data_batch_%d"%i)[b’data’]
a = np.random.choice(a=1000, size=3, replace=False, p=None)
for i in tmp[a]:
img = GetPhoto(i)
images.append(img)
auged_imgs = img_aug(images)
for i in range(len(auged_imgs)):
xx = np.concatenate((images[i], auged_imgs[i]), axis=1)
plt.imshow(xx)
plt.show()
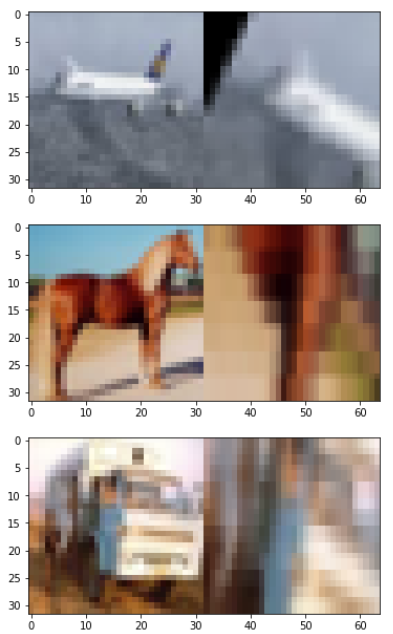




2 .第二周作业
megstudio 提交
项目详情 | MegStudio (brainpp.com)
刘阳的作业
第一周作业
代码
import numpy as np
import imgaug as ia
from imgaug import augmenters as iaa
import matplotlib.pyplot as plt
from megengine.data.dataset import CIFAR10
from megengine.data import SequentialSampler, RandomSampler, DataLoader
CIFAR10_DATA_PATH = ‘dataset/’
train_dataset = CIFAR10(root=CIFAR10_DATA_PATH, train=True, download=False)
train_sampler = SequentialSampler(dataset=train_dataset, batch_size=bs)
train_dataloader = DataLoader(dataset=train_dataset, sampler=train_sampler)
def img_state(img_list):
np_array =
np_array.append(list(img_list.shape))
arr = np.array(np_array)
avg_h = np.mean(arr[:,0])
avg_w = np.mean(arr[:,1])
max_h = np.max(arr[:,0])
max_w = np.max(arr[:,1])
min_h = np.min(arr[:,0])
min_w = np.min(arr[:,1])
img_info = {
‘avg_h’:avg_h,
‘avg_w’:avg_w,
‘max_h’:max_h,
‘max_w’:max_w,
‘min_h’:min_h,
‘min_w’:min_w,
}
print(“image statistic result: {}”.format(img_info))
H=256
W=256
num=8
data aug
aug_func = iaa.Sequential([
iaa.Affine(
scale={“x”: (1.3, 0.7), “y”: (0.7, 1.3)},
translate_percent = {“x”: (-0.3, 0.3), “y”: (-0.2, 0.2)},
rotate=(-45, 45),
shear=(-32, 32),
order=[0,1]),
iaa.Resize({“height”: H, “width”: W}),
iaa.Fliplr(0.79),
iaa.Flipud(0.21),
iaa.Crop(px = (0, 100)),
], random_order=True)
for batch_data, batch_label in train_dataloader:
for data in batch_data[65:68]:
# avg/max/min height, width
img_state(data)
images = np.array([data] * num,dtype = np.uint8)
images_aug = aug_func(images = images)
write_img = np.zeros((H, (W+10)*num, 3), dtype = np.uint8)
for i, img in enumerate(images_aug):
write_img[:, i*(W+10): i*(W+10)+W, :] = img
plt.imshow(write_img, cmap="gray")
plt.show()
break
结果

第二周作业
提交到 MegStudio:https://studio.brainpp.com/project/10440?name=AI培训课后作业(4_2)_liuyang_作业
