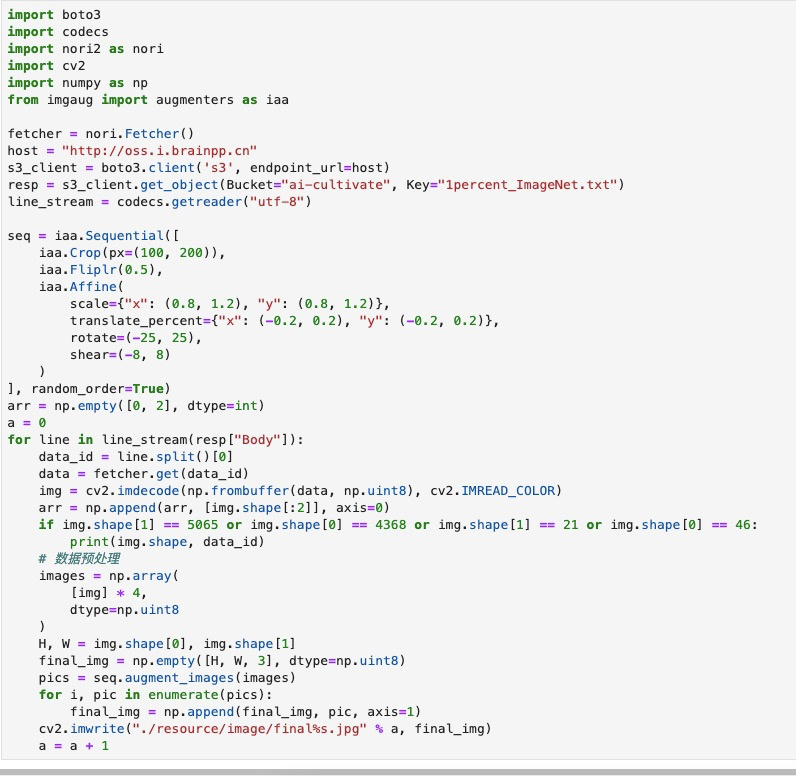
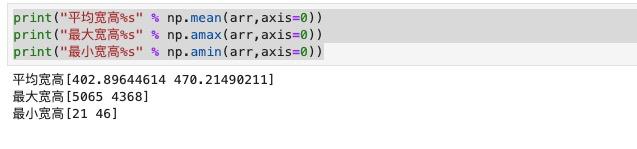
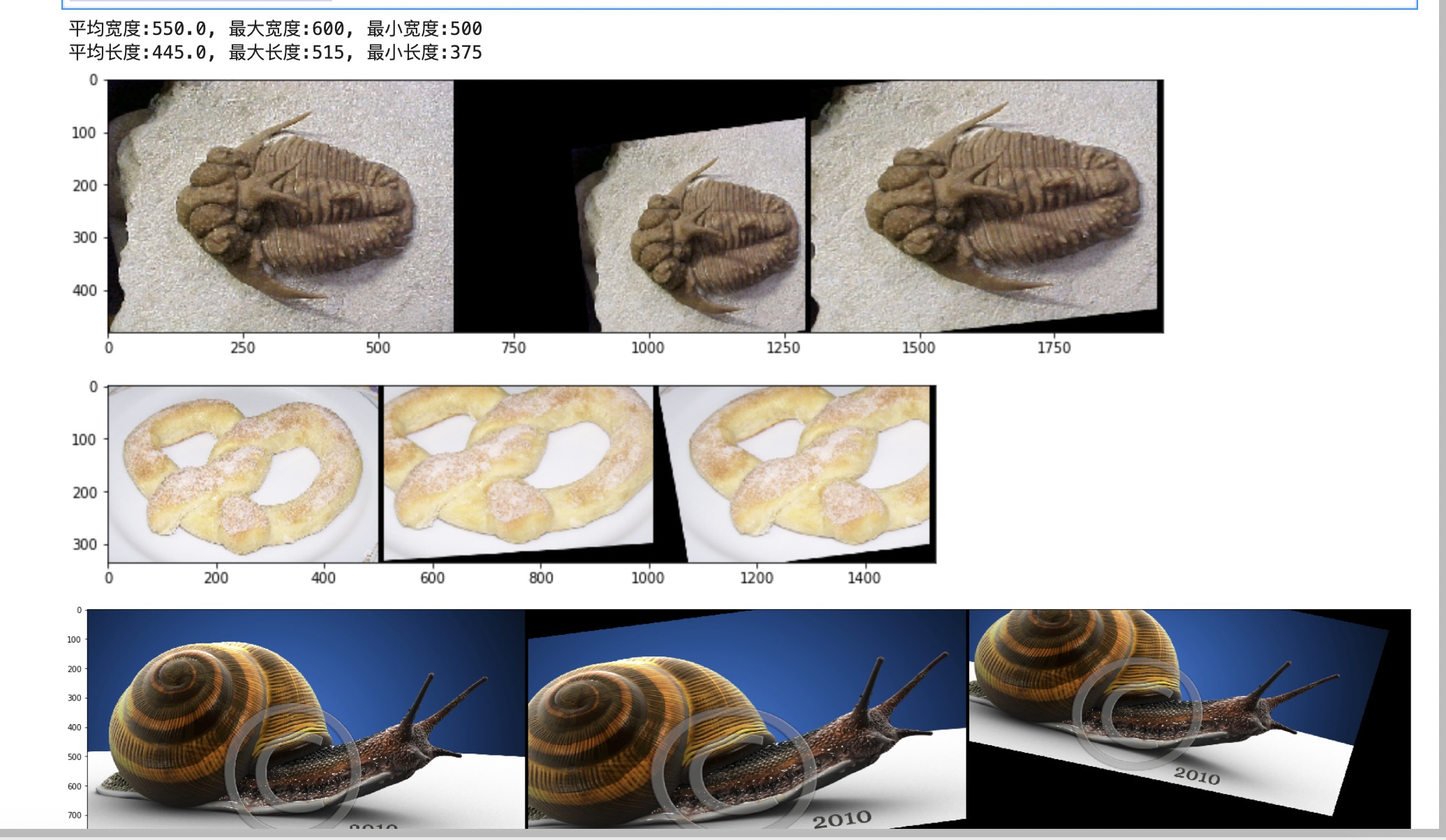
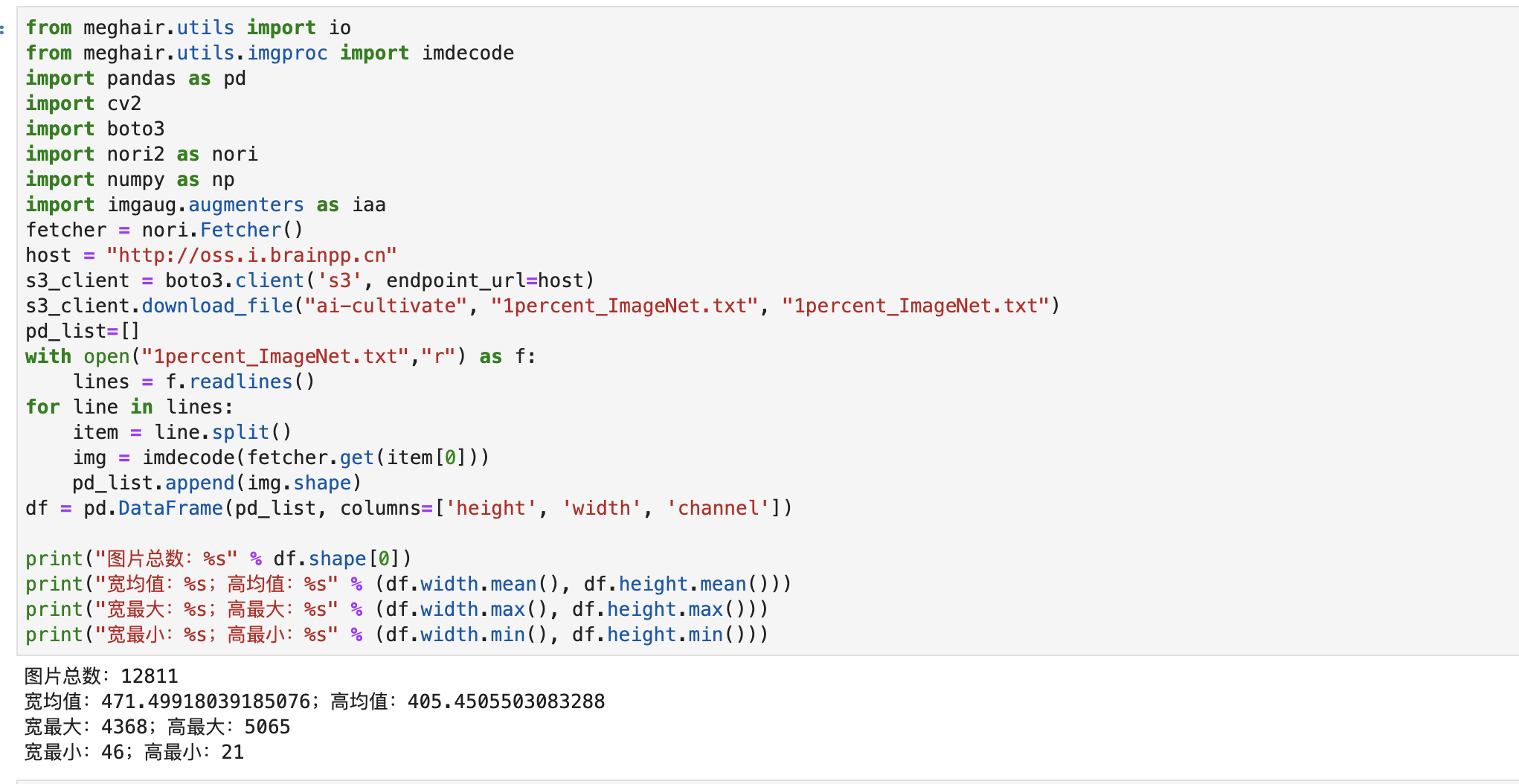
刘旭:


第三周作业
import re
import requests
from urllib.parse import quote
KEYWORD = "充气拱门 图片"
def get_images(keyword, num):
print(f"Start downloading images for {keyword}")
keyword_encode = quote(keyword)
# Baidu的图片接口
url_pattern = 'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&' \
'queryWord={keyword_encode}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=&' \
'copyright=&word={keyword_encode}&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&' \
'expermode=&force=&cg=star&pn={page_num}&rn={info_num}&gsm=1e&1598868283333= '
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_1) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/89.0.4389.90 Safari/537.36',
'Referer': 'https://image.baidu.com'
}
page_num = 1
info_num = 30
image_pattern = re.compile('thumbURL.*?\.jpg')
img_set = set()
n = 1
while True:
resp = requests.get(url_pattern.format(keyword_encode=keyword_encode,
page_num=page_num,
info_num=info_num), headers=header)
image_url_list = image_pattern.findall(resp.text)
image_url_list = map(lambda x: x.replace('thumbURL":"', ''), image_url_list)
for img_url in image_url_list:
if n > num:
print(f"Finished: Totally download {n-1} images.")
return
# img_url去重
if img_url in img_set:
continue
else:
img_set.update((img_url,))
download_img(img_url, n)
n += 1
page_num += 1
def download_img(img_url, num):
print(f"Downloading image {num}: {img_url}")
img = requests.get(img_url)
with open('data/image_{}.jpg'.format(num), 'wb') as f:
f.write(img.content)
if __name__ == "__main__":
get_images(KEYWORD, 1000)
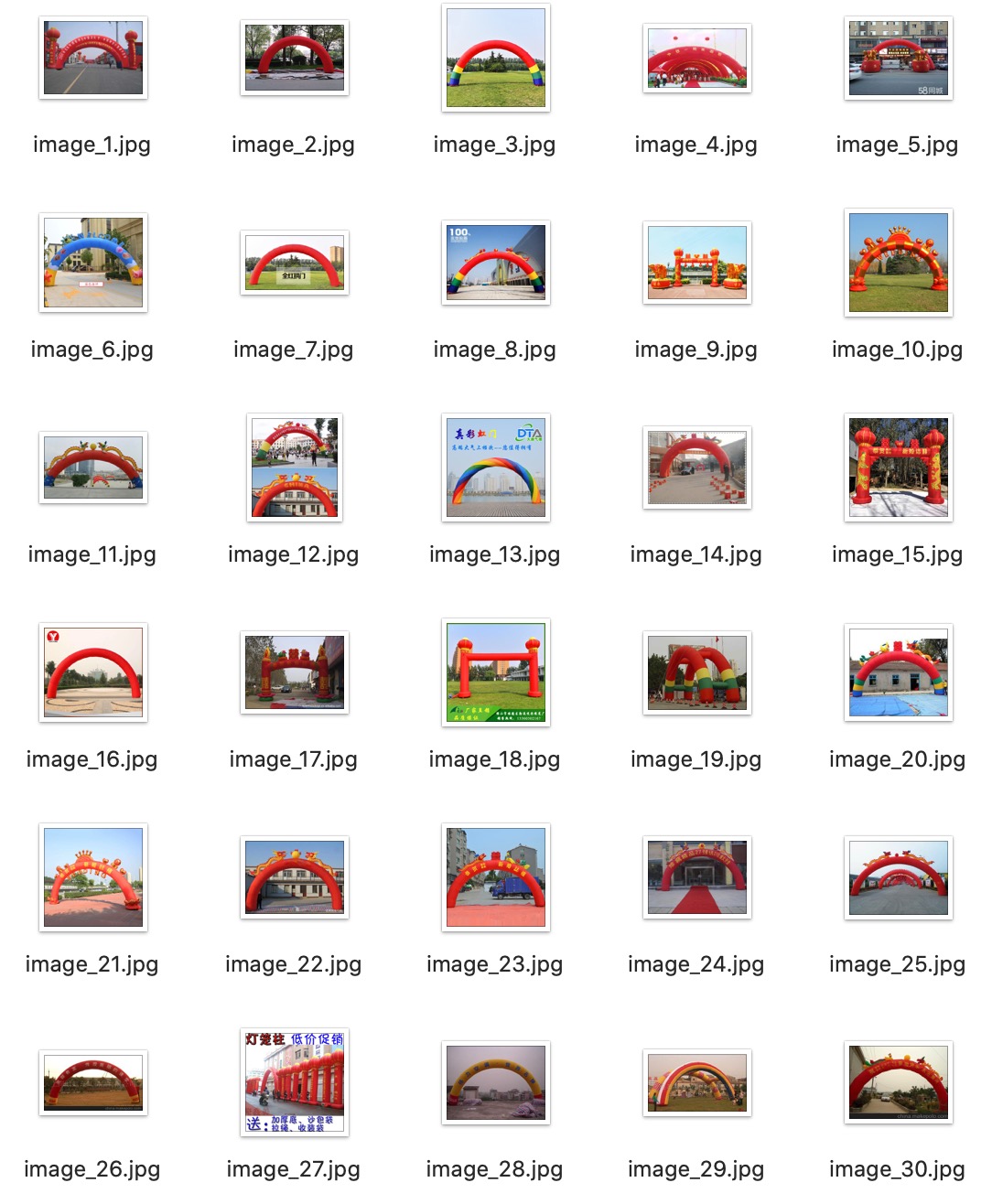
第三周大组作业
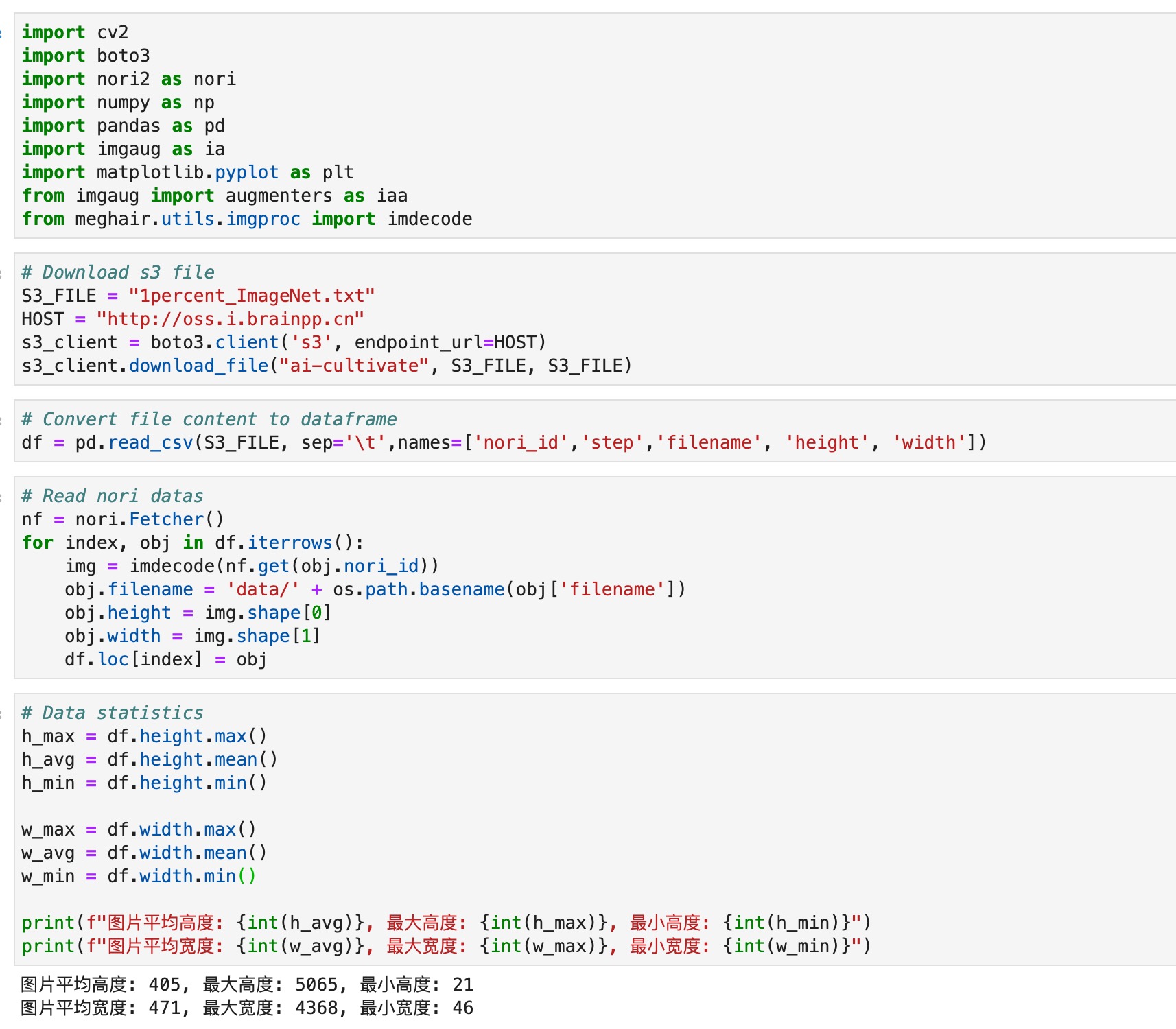
已在越影平台创建需求,数据上传100%,标注完成,BMK中,需求id:66, 数据量: 2564