课后作业帖:【AI培训第四期课后作业内容帖】
第一周作业:https://studio.brainpp.com/project/9958?name=AI培训课后作业(3_1)_sunyuting_作业
第二周作业:https://studio.brainpp.com/project/10505?name=sunyuting_第二次课作业
【AI-CAMP四期】第六组作业
第一周作业
import numpy as np
import cv2
import boto3
import nori2 as nori
from meghair.utils.imgproc import imdecode
host = "http://oss.i.brainpp.cn/"
bucket = "ai-cultivate"
key = "1percent_ImageNet.txt"
s3_client = boto3.client('s3', endpoint_url=host)
def read_img():
image_res = s3_client.get_object(Bucket=bucket, Key=key)
image_data = image_res['Body'].read().decode("utf8")
images = image_data.split('\n')
nori_ids = list(map(lambda x: x.split('\t')[0], images))[-7:-1:1]
fetcher = nori.Fetcher()
imgs = list(map(lambda x: imdecode(fetcher.get(x)), nori_ids))
return imgs
def calcu_shape(imgs):
height_list = []
width_list = []
for i,img in enumerate(imgs):
height_list.append(img.shape[0])
width_list.append(img.shape[1])
max_height = max(height_list)
max_width = max(width_list)
min_height = min(height_list)
min_width = min(width_list)
avg_height = np.mean(height_list)
avg_width = np.mean(width_list)
shape_info = {'max_height':max_height,'max_width':max_width,'min_height':min_height,'min_width':min_width,'avg_height':avg_height,'avg_width':avg_width}
print(shape_info)
def img_process(imgs):
H, W = 128, 128
NUM = 6
from imgaug import augmenters as iaa
seq = iaa.Sequential([
iaa.Crop(px=(0, 50)),
iaa.Fliplr(0.5),
iaa.Affine(
rotate=(-45, 45)
),
iaa.Resize({"height": H, "width": W})
], random_order=True)
res = np.zeros(shape=((H + 10) * len(imgs), (W + 10) * NUM, 3), dtype=np.uint8)
for i, img in enumerate(imgs):
img_array = np.array([img] * NUM, dtype=np.uint8)
#write_img = np.zeros(shape=(H, (W + 10) * NUM, 3), dtype=np.uint8)
images_after_aug = seq.augment_images(images=img_array)
for j, item in enumerate(images_after_aug):
res[i * (H + 10): i * (H + 10) + H, j * (W + 10): j * (W + 10) + W, :] = item
#write_img[:, j * (W + 10): j * (W + 10) + W, :] = item
#res[i * (H + 10): i * (H + 10) + H, :, :] = write_img
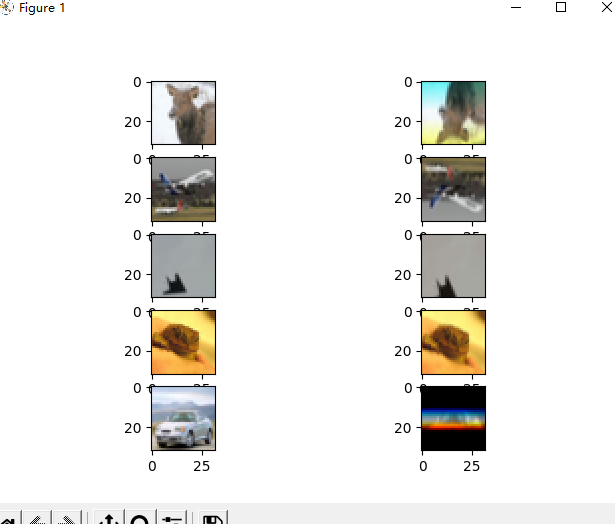
cv2.imwrite("augmenters.jpg", res)
if __name__ == '__main__':
imgs = read_img()
calcu_shape(imgs)
img_process(imgs)
#{'avg_width': 476.5, 'min_width': 330, 'avg_height': 408.0, 'min_height': 330, 'max_height': 500, 'max_width': 654}

第一周作业
第二周作业
- 个人作业
- 代码
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
def generate_random_examples(n=100, noise=5):
w = np.random.randint(10,20)
b = np.random.randint(-20,20)
data = np.zeros((n,))
label = np.zeros((n,))
for i in range(n):
data[i] = np.random.uniform(-10,10)
label[i] = w * data[i] + b + np.random.uniform(-noise, noise)
return data, label
original_data, original_label = generate_random_examples()
import megengine as mge
import megengine.functional as F
from megengine.autodiff import GradManager
import megengine.optimizer as optim
epochs = 100
lr = 0.02
data = mge.tensor(original_data)
label = mge.tensor(original_label)
w = mge.Parameter([0.0])
b = mge.Parameter([0.0])
def linear_model(x):
return F.mul(w, x) + b
gm = GradManager().attach([w, b])
optimizer = optim.SGD([w, b], lr=lr)
for epoch in range(epochs):
with gm:
pred = linear_model(data)
loss = F.loss.square_loss(pred, label)
gm.backward(loss)
optimizer.step().clear_grad()
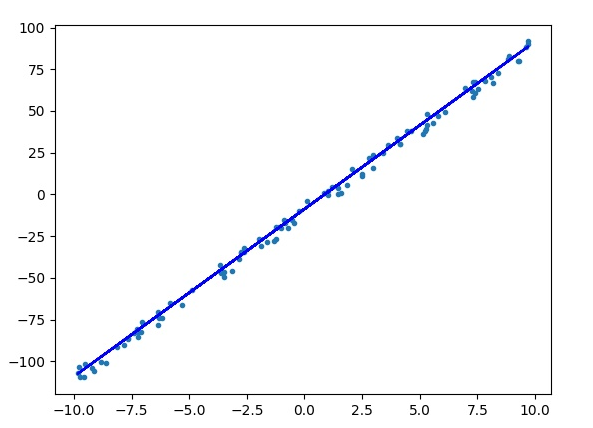
print("epoch = {}, w = {:.3f}, b = {:.3f}, loss = {:.3f}".format(epoch, w.item(), b.item(), loss.item()))
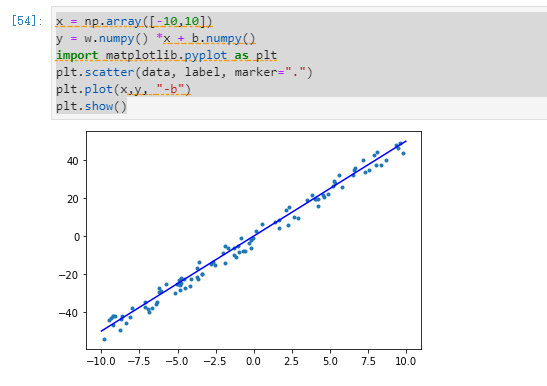
x = np.array([-10,10])
y = w.numpy() * x + b.numpy()
plt.scatter(data, label, marker=".")
plt.plot(x, y, "-b")
plt.show()
- 截图
- 小组作业
- 代码
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from megengine.data.dataset import MNIST
# ------------------- 步骤1:获取训练和测试数据 ---------------------------------------
# MNIST数据集地址,请根据环境修改
MNIST_DATA_PATH = "src/python/ai_training/dataset/MNIST/"
# 获取训练数据集,如果本地没有数据集,请将 download 参数设置为 True
train_dataset = MNIST(root=MNIST_DATA_PATH, train=True, download=False)
# 打印训练数据集信息
# print(type(train_dataset[0][0]), type(train_dataset[0][1]))
print(len(train_dataset[0]), train_dataset[0][0].shape, train_dataset[2][1].shape)
# 数据集meta data
num_features = train_dataset[0][0].size
num_classes = 10
# 获取测试数据集
test_dataset = MNIST(root=MNIST_DATA_PATH, train=False, download=False)
# ------------------- 步骤2:线性分类训练 ---------------------------------------
import numpy as np
import megengine as mge
import megengine.functional as F
from megengine.data.dataset import MNIST
from megengine.data import SequentialSampler, RandomSampler, DataLoader
from megengine.autodiff import GradManager
import megengine.optimizer as optim
# 设置超参数
bs = 64 # batch-size
lr = 1e-6 # learning rate
epochs = 5 # 迭代次数,实际测试,在线性分类算法下,增加迭代次数不会提升精度
# 训练数据加载与预处理
train_sampler = SequentialSampler(dataset=train_dataset, batch_size=bs)
train_dataloader = DataLoader(dataset=train_dataset, sampler=train_sampler)
# 初始化参数
W = mge.Parameter(np.zeros((num_features, num_classes)))
# print("W shape is:", W.shape)
b = mge.Parameter(np.zeros((num_classes,)))
# 定义模型:y = W*X + b
def linear_cls(X):
return F.matmul(X, W) + b
# 定义求导器和优化器
gm = GradManager().attach([W, b])
optimizer = optim.SGD([W, b], lr=lr)
# 模型训练
for epoch in range(epochs):
total_loss = 0
for batch_data, batch_label in train_dataloader:
batch_data = F.flatten(mge.tensor(batch_data), 1).astype("float32")
batch_label = mge.tensor(batch_label)
with gm:
pred = linear_cls(batch_data)
loss = F.loss.cross_entropy(pred, batch_label)
gm.backward(loss)
optimizer.step().clear_grad()
total_loss += loss.item()
print("epoch = {}, loss = {:.6f}".format(epoch+1, total_loss / len(train_dataset)))
# ------------------- 步骤3:线性分类测试 ---------------------------------------
test_sampler = RandomSampler(dataset=test_dataset, batch_size=bs)
test_dataloader = DataLoader(dataset=test_dataset, sampler=test_sampler)
nums_correct = 0
for batch_data, batch_label in test_dataloader:
batch_data = F.flatten(mge.tensor(batch_data), 1).astype("float32")
batch_label = mge.tensor(batch_label)
logits = linear_cls(batch_data)
pred = F.argmax(logits, axis=1)
nums_correct += (pred == batch_label).sum().item()
print("Accuracy = {:.3f}".format(nums_correct / len(test_dataset)))
# ------------------- 步骤4:神经网络训练 ---------------------------------------
from megengine.data import SequentialSampler, RandomSampler, DataLoader
from megengine.autodiff import GradManager
import megengine.optimizer as optim
# 设置超参数
bs = 64
lr = 0.75
epochs = 5
num_hidden_1 = 256 # 第一个隐藏层单元数
num_hidden_2 = 128 # 第二个隐藏层单元数
# 初始化参数,没有使用零初始化,而是用 NumPy 随机生成服从正态分布的数据,而且加入了缩放因子 Scale
W1 = mge.Parameter(np.random.normal(size=(num_features, num_hidden_1), scale=0.01))
b1 = mge.Parameter(np.random.normal(size=(num_hidden_1,), scale=0.01))
W2 = mge.Parameter(np.random.normal(size=(num_hidden_1, num_hidden_2), scale=0.01))
b2 = mge.Parameter(np.random.normal(size=(num_hidden_2,), scale=0.01))
W3 = mge.Parameter(np.random.normal(size=(num_hidden_2, num_classes), scale=0.01))
b3 = mge.Parameter(np.random.normal(size=(num_classes,), scale=0.01))
# 定义模型:网络模型,两个隐藏层,采用ReLU作为激活函数,最后通过一个线性模型产生输出
def feedforward_neural_network(X):
z1 = F.relu(F.matmul(X, W1) + b1)
z2 = F.relu(F.matmul(z1, W2) + b2)
z3 = F.matmul(z2, W3) + b3
return z3
# 定义求导器和优化器
gm = GradManager().attach([W1, b1, W2, b2, W3, b3])
optimizer = optim.SGD([W1, b1, W2, b2, W3, b3], lr=lr)
# 模型训练
for epoch in range(epochs):
total_loss = 0
for batch_data, batch_label in train_dataloader:
batch_data = F.flatten(mge.tensor(batch_data/255), 1).astype("float32") # 注意这里进行了归一化
batch_label = mge.tensor(batch_label)
with gm:
pred = feedforward_neural_network(batch_data)
loss = F.loss.cross_entropy(pred, batch_label)
gm.backward(loss)
optimizer.step().clear_grad()
total_loss += loss.item()
print("epoch = {}, loss = {:.6f}".format(epoch+1, total_loss / len(train_dataset)))
# ------------------- 步骤5:神经网络测试 ---------------------------------------
test_sampler = RandomSampler(dataset=test_dataset, batch_size=100)
test_dataloader = DataLoader(dataset=test_dataset, sampler=test_sampler)
nums_correct = 0
for batch_data, batch_label in test_dataloader:
batch_data = F.flatten(mge.tensor(batch_data/255), 1).astype("float32") # 注意这里进行了归一化
batch_label = mge.tensor(batch_label)
logits = feedforward_neural_network(batch_data)
pred = F.argmax(logits, axis=1)
nums_correct += (pred == batch_label).sum().item()
print("Accuracy = {:.3f}".format(nums_correct / len(test_dataset)))
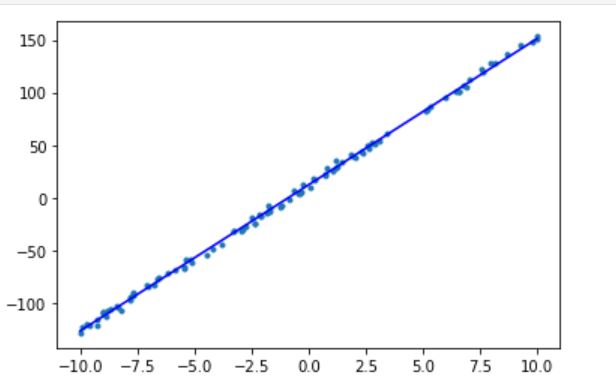
- 线性分类训练结果

- 线性分类测试结果
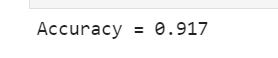
- 神经网络训练结果

- 神经网络测试结果
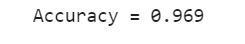
第一周课后作业:
https://studio.brainpp.com/project/10089?name=AI培训课后作业(3_1)_haoxue_作业
第二周课后作业:
https://studio.brainpp.com/project/10478?name=AI培训课后作业(3_2)_haoxue_作业
[details=“第一周作业”]
#coding:utf-8
import boto3
import cv2
import nori2 as nori
import numpy as np
from imgaug import augmenters as iaa
from meghair.utils.imgproc import imdecode
host = "http://oss.i.brainpp.cn/"
bucket = "ai-cultivate"
key = "1percent_ImageNet.txt"
gap = 16
s3_client = boto3.client('s3', endpoint_url=host)
def read_img():
resp = s3_client.get_object(Bucket=bucket, Key=key)
datas = resp['Body'].read().decode('utf8')
data_list = datas.split('\n')
nori_ids = list(map(lambda x: x.split('\t')[0], data_list))[210:220]
fetcher = nori.Fetcher()
img_list = list(map(lambda x: imdecode(fetcher.get(x)), nori_ids))
return img_list
def stat(img_list):
h_list = []
w_list = []
for i, img in enumerate(img_list):
h_list.append(img.shape[0])
w_list.append(img.shape[1])
average_h = np.mean(h_list)
max_h = max(h_list)
min_h = min(h_list)
average_w = np.mean(w_list)
max_w = max(w_list)
min_w = min(w_list)
img_info = {
'average_h': average_h,
'max_h': max_h,
'min_h': min_h,
'average_w': average_w,
'max_w': max_w,
'min_w': min_w,
}
print("image statistic result: {}".format(img_info))
def enhance_img(img_list):
H, W = 100, 60
NUM = 9
seq = iaa.Sequential([
iaa.Fliplr(0.4),
iaa.Crop(px=(0, 50)),
iaa.Affine(
scale = {"x": (0.8, 1.2), "y": (0.8, 1.2)},
translate_px = {"x": (-16, 16), "y": (-16,16)},
rotate = (-75, 75)
),
iaa.GaussianBlur(sigma=(0, 2.0)),
iaa.Resize({"height": H, "width": W})
], random_order=True)
res = np.zeros(shape=((H + gap)* len(img_list), (W + gap)*NUM, 3),dtype = np.uint8)
for i, img in enumerate(img_list):
img_array = np.array([img] * NUM, dtype = np.uint8)
write_img = np.zeros(shape=(H, (W + gap)*NUM, 3), dtype=np.uint8)
images_aug = seq.augment_images(images=img_array)
for j, item in enumerate(images_aug):
write_img[:, j * (W+gap): j * (W+gap) + W, :] = item
res[i * (H+10): i*(H+10) + H, :, :] = write_img
cv2.imwrite('result.jpg', res)
if __name__ == '__main__':
img_list = read_img()
stat(img_list)
enhance_img(img_list)
image statistic result: {‘avg_height’: 419.5, ‘max_height’: 500, ‘min_height’: 331, ‘avg_width’: 430.3, ‘max_width’: 500, ‘min_width’: 281}


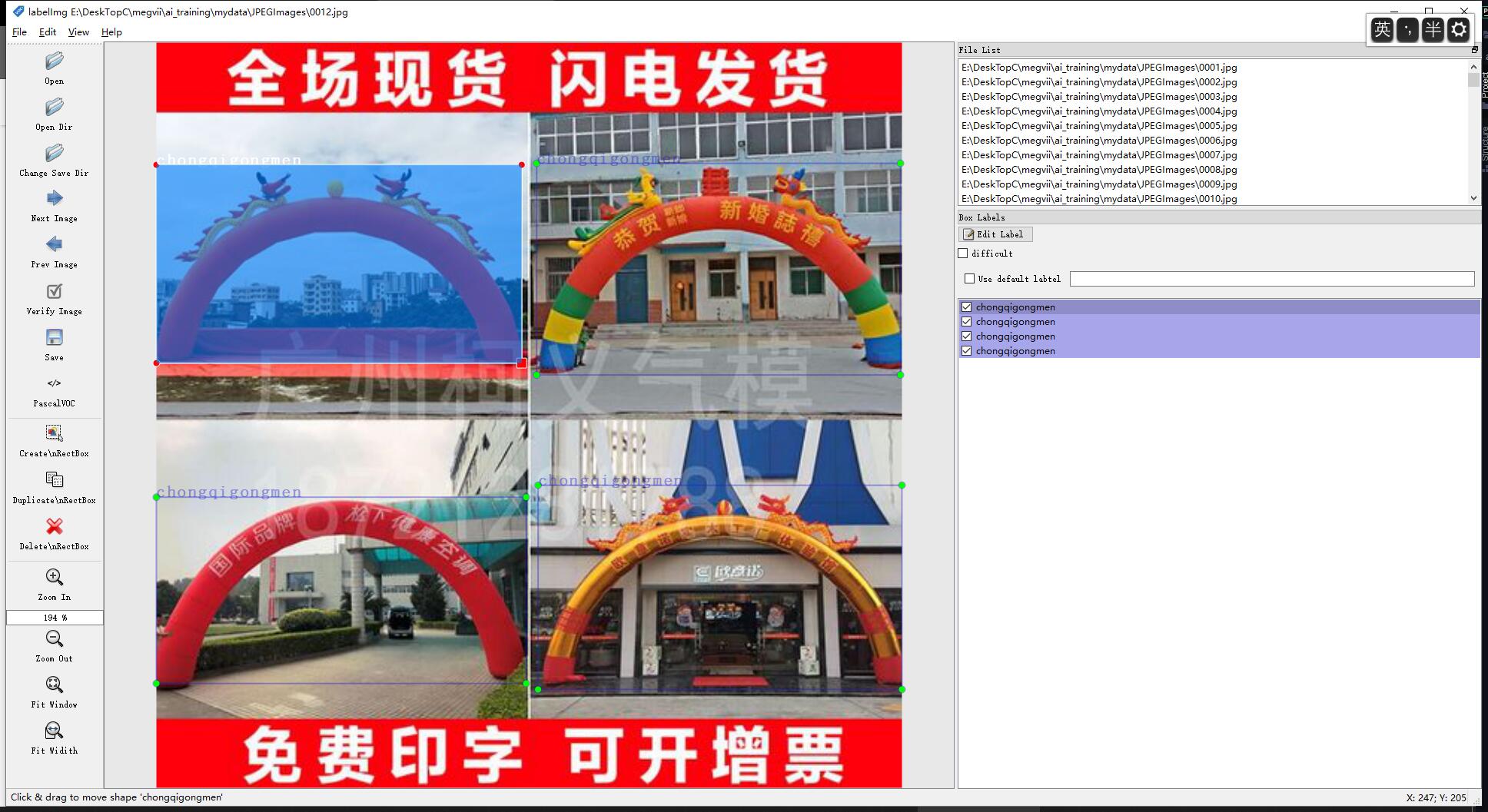
第三周作业
网络选择
mobile-ssd
数据处理
须将数据转换为voc格式数据,编写转换代码如下:
import json
import os
import xml.etree.ElementTree as ET
def cvt_rect_json(p, w, h):
return [
max(int(p[0][0] * w), 0),
max(int(p[0][1] * h), 0),
min(int((p[1][0] - p[0][0]) * w), int(w)),
min(int((p[2][1] - p[1][1]) * h), int(h))
]
def read_data_json(in_path):
with open(in_path, 'r', encoding='utf8') as f:
raw_data = json.load(f)
def filter_data(obj):
data = {}
w = obj['resources'][0]['size']['width']
h = obj['resources'][0]['size']['height']
data['w'] = w
data['h'] = h
data['name'] = obj['resources'][0]['s'].split('/')[-1]
data['rects'] = []
if not obj['results']:
return data
rects = obj['results']['rects']
for rect in rects:
data['rects'].append(cvt_rect_json(rect['rect'], w, h))
return data
return map(filter_data, raw_data['items'])
def write_xml_data(out_path, items):
if not os.path.exists(out_path):
os.makedirs(out_path)
for item in items:
tree = ET.Element('annotation')
folder = ET.SubElement(tree, 'folder')
folder.text = 'xxx'
filename = ET.SubElement(tree, 'filename')
filename.text = item['name']
path = ET.SubElement(tree, 'path')
path.text = 'xxx'
source = ET.SubElement(tree, 'source')
source_database = ET.SubElement(source, 'database')
source_database.text = 'xxx'
size = ET.SubElement(tree, 'size')
width = ET.SubElement(size, 'width')
width.text = str(item['w'])
height = ET.SubElement(size, 'height')
height.text = str(item['h'])
depth = ET.SubElement(size, 'depth')
depth.text = '3'
segmented = ET.SubElement(tree, 'segmented')
segmented.text = '0'
if item['rects']:
for rect in item['rects']:
_object = ET.SubElement(tree, 'object')
name = ET.SubElement(_object, 'name')
name.text = 'chongqigongmen'
pose = ET.SubElement(_object, 'pose')
pose.text = 'Unspecified'
truncated = ET.SubElement(_object, 'truncated')
truncated.text = '0'
difficult = ET.SubElement(_object, 'difficult')
difficult.text = '0'
bndbox = ET.SubElement(_object, 'bndbox')
xmin = ET.SubElement(bndbox, 'xmin')
xmin.text = str(rect[0])
ymin = ET.SubElement(bndbox, 'ymin')
ymin.text = str(rect[1])
xmax = ET.SubElement(bndbox, 'xmax')
xmax.text = str(rect[2] + rect[0])
ymax = ET.SubElement(bndbox, 'ymax')
ymax.text = str(rect[3] + rect[1])
tree = ET.ElementTree(tree)
tree.write(os.path.join(out_path, item['name'].split('.')[0] + '.xml'))
print(item['name'])
if __name__ == '__main__':
write_xml_data('output', read_data_json('chongqigongmen_pic+label/chongqigongmen.json'))
经labelimg验证,转换格式正确: