
AI-CAMP四期作业贴:【AI培训第四期课后作业内容帖】
【AI-CAMP四期】第七组作业
史晓鹏-AI_CAMP第四期-作业
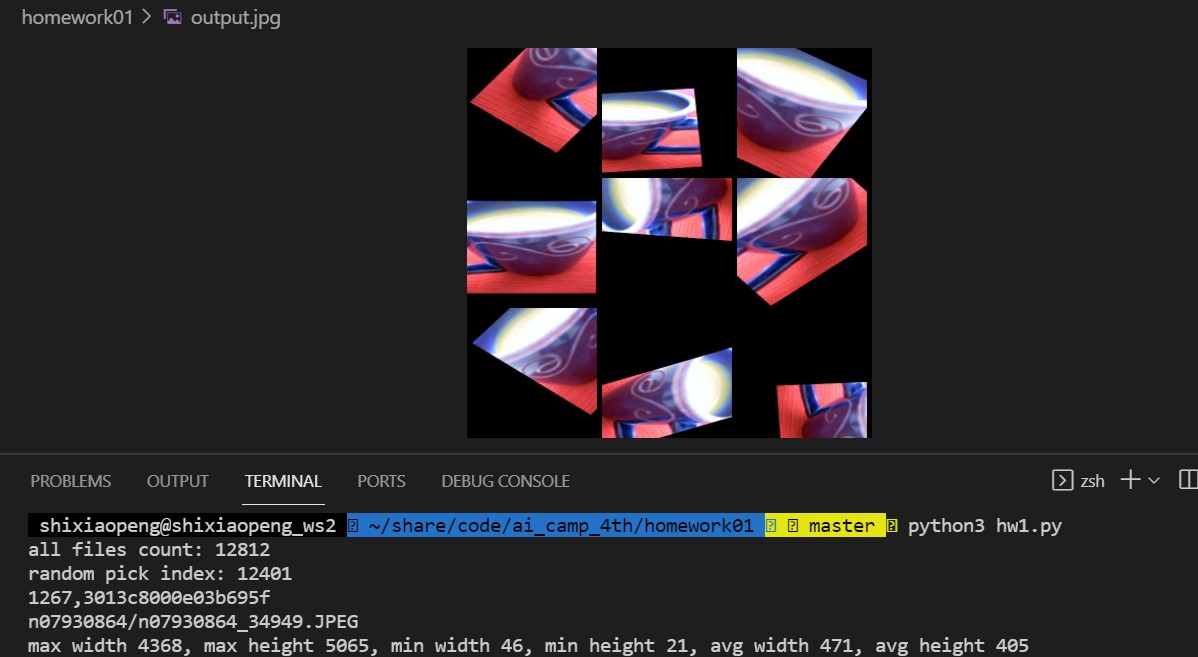


周怡东-AI_TRAIN第四期-作业
Week 1
Code
# -*- coding: UTF-8 -*-
import boto3
import boto3
import cv2
import nori2 as nori
import numpy as np
from imgaug import augmenters as iaa
from meghair.utils import io
from meghair.utils.imgproc import imdecode
from refile import smart_open
s3_client = boto3.client('s3', endpoint_url="http://oss.i.brainpp.cn")
bucket = "ai-cultivate"
key = "1percent_ImageNet.txt"
# 读取
def read_img(bucket, key):
resp = s3_client.get_object(Bucket=bucket, Key=key)
res = resp['Body'].read().decode("utf8")
data = res.split('\n')
nori_ids = list(map(lambda x: x.split('\t')[0], data))[-10::2]
fetcher = nori.Fetcher()
img_list = list(map(lambda x: imdecode(fetcher.get(x)), nori_ids))
print(type(img_list[0]))
return img_list
# 统计
def get_img_statistics(img_list):
img_size_list = []
for i, img in enumerate(img_list):
img_size_list.append({"img_num": "img_{}".format(i), "height": img.shape[0], "width": img.shape[1]})
height_list = [img_size["height"] for img_size in img_size_list]
width_list = [img_size['width'] for img_size in img_size_list]
avg_height = np.mean(height_list)
max_height = max(height_list)
min_height = min(height_list)
avg_width = np.mean(width_list)
max_width = max(width_list)
min_width = min(width_list)
img_info = {'avg_height': avg_height, 'max_height': max_height, 'min_height': min_height,
'avg_width': avg_width, 'max_width': max_width, 'min_width': min_width,
'img_size': img_size_list}
print("图片信息统计结果: {}".format(img_info))
return img_info
# 增强
def enhance_img(img_list):
H, W = 128, 128
NUM = 6
seq = iaa.Sequential([
iaa.Fliplr(0.5), # 以50%概率水平翻转
iaa.Crop(percent=(0, 0.05)), # 四边以0 - 0.05之间的比例像素剪裁
iaa.Affine(
scale={"x": (0.8, 1.2), "y": (0.8, 1.2)}, # 图像缩放
translate_px={"x": (-16, 16), "y": (-16, 16)}, # 随机平移
rotate=(-45, 45) # 随机旋转
),
iaa.GaussianBlur(sigma=(0, 2.0)), # 高斯模糊
iaa.Resize({"height": H, "width": W})
], random_order=True)
res = np.zeros(shape=((H + 10) * len(images), (W + 10) * NUM, 3), dtype=np.uint8)
for i, img in enumerate(img_list):
img_array = np.array([img] * NUM, dtype=np.uint8)
write_img = np.zeros(shape=(H, (W + 10) * NUM, 3), dtype=np.uint8)
images_aug = seq.augment_images(images=img_array)
for j, item in enumerate(images_aug):
write_img[:, j * (W + 10): j * (W + 10) + W, :] = item
# Merge
res[i * (H + 10): i * (H +10) + H, :, :] = write_img
cv2.imwrite("/data/result.jpg", res)
if __name__ == "__main__":
images = read_img(bucket, key)
get_img_statistics(images)
enhance_img(images)
统计结果


Week 2
https://git-core.megvii-inc.com/ai_train/ai_train_zhouyidong/-/tree/master/Week2
Critical Section
#mge线性回归
def linear_model(x):
return F.mul(w,x)+b
gm = GradManager().attach([w,b])
optimizer = optim.SGD([w,b],lr=lr)
for epoch in range(epochs):
with gm:
pred = linear_model(data)
loss = F.loss.square_loss(pred,label)
gm.backward(loss)
optimizer.step().clear_grad()
print("epochs : {}, w: {:.3f}, b: {:.3f}, loss: {:.3f}".format(epoch, w.item(), b.item(), loss.item()))
#基于mge的MNIST训练
#训练
class Net(M.Module):
def __init__(self):
super().__init__()
self.conv0 = M.Conv2d(1, 20, kernel_size=5, bias=False)
self.bn0 = M.BatchNorm2d(20)
self.relu0 = M.ReLU()
self.pool0 = M.MaxPool2d(2)
self.conv1 = M.Conv2d(20, 20, kernel_size=5, bias=False)
self.bn1 = M.BatchNorm2d(20)
self.relu1 = M.ReLU()
self.pool1 = M.MaxPool2d(2)
self.fc0 = M.Linear(500, 64, bias=True)
self.relu2 = M.ReLU()
self.fc1 = M.Linear(64, 10, bias=True)
def forward(self, x):
x = self.conv0(x)
x = self.bn0(x)
x = self.relu0(x)
x = self.pool0(x)
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.pool1(x)
x = F.flatten(x, 1)
x = self.fc0(x)
x = self.relu2(x)
x = self.fc1(x)
return x
#测试
correct = 0
total = 0
for idx, (batch_data, batch_label) in enumerate(dataloader_test):
batch_label = batch_label.astype(np.int32)
pred, loss = eval_func(mge.tensor(batch_data), mge.tensor(batch_label), net=net)
predicted = pred.numpy().argmax(axis=1)
correct += (predicted == batch_label).sum().item()
total += batch_label.shape[0]
print("correct: {}, total: {}, accuracy: {}".format(correct, total, float(correct) / total))
Week 3
Week 4
Week 5
Week 6
第二周作业
- 基础作业
%matplotlib inline
import numpy as np
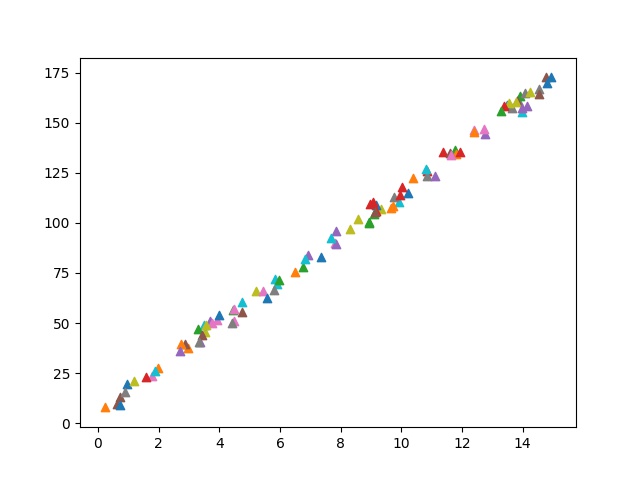
import matplotlib.pyplot as pltdef generate_random_examples(n = 100, noise = 6):
w = np.random.randint(5, 10)
b = np.random.randint(-10, 10)
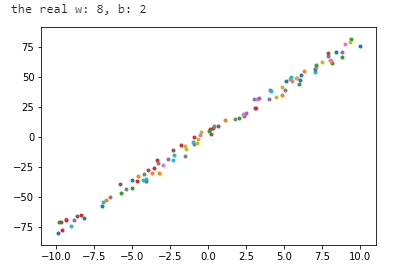
print(“the real w: {}, b: {}”.format(w, b))#初始化 data 和 label data = np.zeros((n, )) label = np.zeros((n, )) #生成 你个随机样本数据,并添加一定的噪声干扰 for i in range(n): data[i] = np.random.uniform(-10, 10) label[i] = w * data[i] + b + np.random.uniform(-noise, noise) plt.scatter(data[i], label[i], marker = ".") # 将样本回执在坐标图上 #展示样本数据 plt.plot() plt.show() return data, labeloriginal_data, original_label = generate_random_examples()
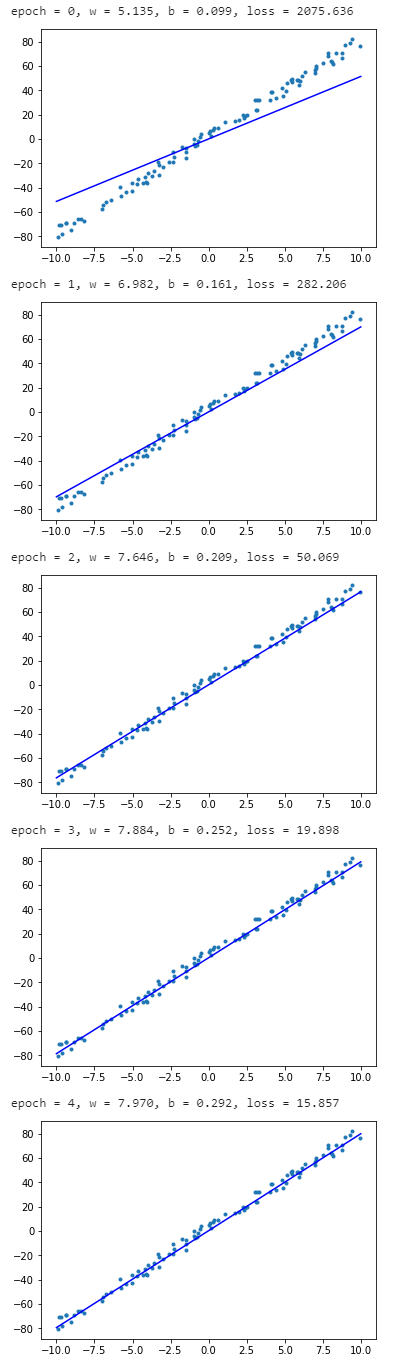
import megengine as meg
import megengine.functional as F
from megengine.autodiff import GradManager
import megengine.optimizer as optim#设置超参数
epochs = 5
lr = 0.01#获取数据
data = meg.tensor(original_data)
label = meg.tensor(original_label)#初始化参数
w = meg.Parameter([0.0])
b = meg.Parameter([0.0])#定义模型
def linear_model(x):
return F.mul(w, x) + b#定义求导函数和优化器
gm = GradManager().attach([w, b])
optimizer = optim.SGD([w, b], lr = lr)#模型训练
for epoch in range(epochs):
with gm:
pred = linear_model(data)
loss = F.loss.square_loss(pred, label)
gm.backward(loss)
optimizer.step().clear_grad()
print(“epoch = {}, w = {:.3f}, b = {:.3f}, loss = {:.3f}”
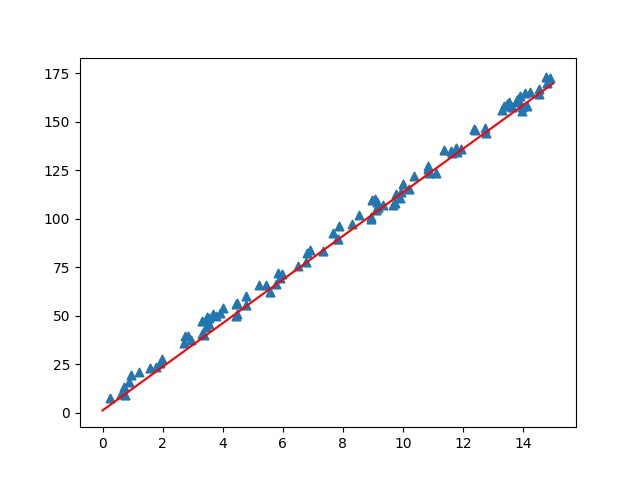
.format(epoch, w.item(), b.item(), loss.item()))x = np.array([-10, 10]) y = w.numpy() * x +b.numpy() plt.scatter(data, label, marker=".") plt.plot(x, y, "-b") plt.show()
- 小组作业
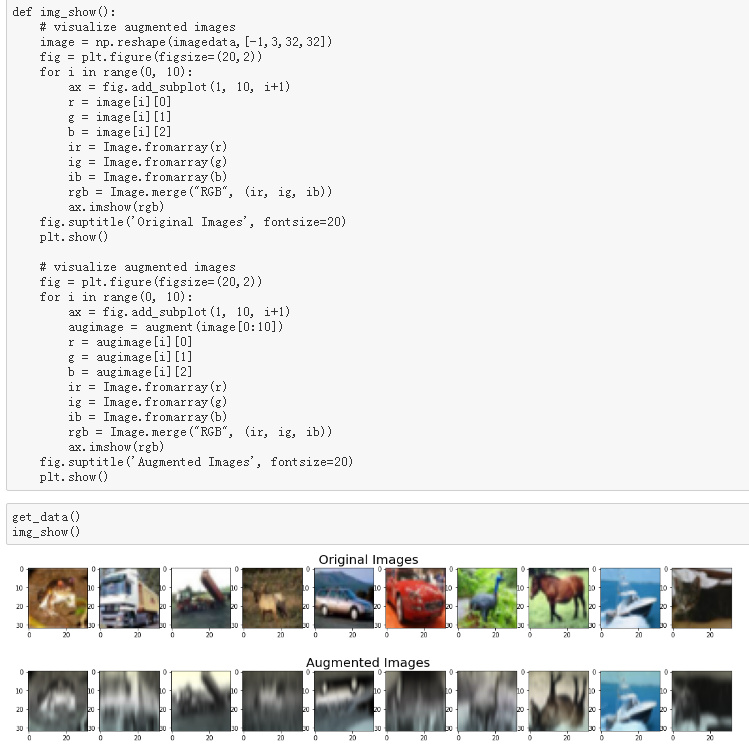
from megengine.data.dataset import MNIST
train_dataset = MNIST(root="./dataset/MNIST", train=True, download=True)
test_dataset = MNIST(root="./dataset/MNIST", train=False, download=False)

import megengine.module as M
import megengine.functional as Fclass Net(M.Module):
def init(self):
super().init()
self.conv0 = M.Conv2d(1, 20, kernel_size=5, bias=False)
self.bn0 = M.BatchNorm2d(20)
self.relu0 = M.ReLU()
self.pool0 = M.MaxPool2d(2)
self.conv1 = M.Conv2d(20, 20, kernel_size=5, bias=False)
self.bn1 = M.BatchNorm2d(20)
self.relu1 = M.ReLU()
self.pool1 = M.MaxPool2d(2)
self.fc0 = M.Linear(500, 64, bias=True)
self.relu2 = M.ReLU()
self.fc1 = M.Linear(64, 10, bias=True)def forward(self, x): x = self.conv0(x) x = self.bn0(x) x = self.relu0(x) x = self.pool0(x) x = self.conv1(x) x = self.bn1(x) x = self.relu1(x) x = self.pool1(x) x = F.flatten(x, 1) x = self.fc0(x) x = self.relu2(x) x = self.fc1(x) return x
from megengine.jit import trace
@trace(symbolic=True)
def train_func(data, label, *, gm, net):
net.train()
with gm:
pred = net(data)
loss = F.loss.cross_entropy(pred, label)
gm.backward(loss)
return pred, loss@trace(symbolic=True)
def eval_func(data, label, *, net):
net.eval()
pred = net(data)
loss = F.loss.cross_entropy(pred, label)
return pred, loss
import time
import numpy as npimport megengine as mge
from megengine.optimizer import SGD
from megengine.autodiff import GradManager
from megengine.data import DataLoader
from megengine.data.transform import ToMode, Pad, Normalize, Compose
from megengine.data.sampler import RandomSampler读取训练数据并进行预处理
dataloader = DataLoader(
train_dataset,
transform=Compose([
Normalize(mean=0.1307255, std=0.3081255),
Pad(2),
ToMode(‘CHW’),
]),
sampler=RandomSampler(dataset=train_dataset, batch_size=64), # 训练时一般使用RandomSampler来打乱数据顺序
)实例化网络
net = Net()
SGD优化方法,学习率lr=0.01,动量momentum=0.9
optimizer = SGD(net.parameters(), lr=0.01, momentum=0.9, weight_decay=5e-4)
gm = GradManager().attach(net.parameters())total_epochs = 10 # 共运行10个epoch
for epoch in range(total_epochs):
total_loss = 0
for step, (batch_data, batch_label) in enumerate(dataloader):
batch_label = batch_label.astype(np.int32)
optimizer.clear_grad() # 将参数的梯度置零
pred, loss = train_func(mge.tensor(batch_data), mge.tensor(batch_label), gm=gm, net=net)
optimizer.step() # 根据梯度更新参数值
total_loss += loss.numpy().item()
print(“epoch: {}, loss {}”.format(epoch, total_loss/len(dataloader)))
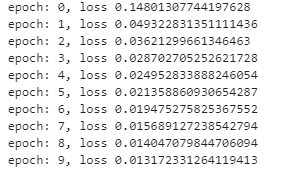
mge.save(net.state_dict(), ‘mnist_net.mge’)
net = Net()
state_dict = mge.load(‘mnist_net.mge’)
net.load_state_dict(state_dict)
from megengine.data.sampler import SequentialSampler
测试数据
test_sampler = SequentialSampler(test_dataset, batch_size=500)
dataloader_test = DataLoader(
test_dataset,
sampler=test_sampler,
transform=Compose([
Normalize(mean=0.1307255, std=0.3081255),
Pad(2),
ToMode(‘CHW’),
]),
)correct = 0
total = 0
for idx, (batch_data, batch_label) in enumerate(dataloader_test):
batch_label = batch_label.astype(np.int32)
pred, loss = eval_func(mge.tensor(batch_data), mge.tensor(batch_label), net=net)
predicted = pred.numpy().argmax(axis=1)
correct += (predicted == batch_label).sum().item()
total += batch_label.shape[0]
print(“correct: {}, total: {}, accuracy: {}”.format(correct, total, float(correct) / total))
![]()
小组作业https://studio.brainpp.com/project/10506?name=MegEngine%20%E7%9A%84%20MNIST%20%E8%AE%AD%E7%BB%83-GuoChunxue&tab=content