开帖占坑 
作业跳转: 【AI培训第四期课后作业内容帖】

针对cifar10的数据,进行基本数据统计(统计框/图片的平均,最大,最小宽高),数据预处理(对数据做旋转强,randomcrop),并做可视化分析对比数据处理前后的变化。
import numpy as np
from PIL import Image
import pickle
import imgaug.augmenters as iaa
from matplotlib import pyplot as plt
CHENNEL = 3
HEIGHT = 32
WIDTH = 32
file_name = "cifar-10-batches-py/data_batch_{}"
data = []
labels = []
def get_all_data():
global data
global labels
for i in range(5):
with open(file_name.format(i + 1), "rb") as f:
dict = pickle.load(f, encoding="bytes")
data += list(dict[b'data'])
labels += list(dict[b'labels'])
def get_test_10_imgs():
imgs = np.reshape(data, [-1, CHENNEL, WIDTH, HEIGHT])
img_10 = imgs[-20::2]
return img_10
def print_sizes():
width_list = []
height_list = []
width_sum = 0
height_sum = 0
width_max = 0
width_min =0
height_max = 0
height_min =0
img_10 = get_test_10_imgs()
for img in img_10:
width_sum += img.shape[1]
height_sum += img.shape[2]
if width_min == 0:
width_min = img.shape[1]
if width_max <= img.shape[1]:
width_max = img.shape[1]
if width_min > img.shape[1]:
width_min = img.shape[1]
if height_min == 0:
height_min = img.shape[2]
if height_max <= img.shape[2]:
height_max = img.shape[2]
if height_min > img.shape[2]:
height_min = img.shape[2]
print("avg_width is {}, avg_height is {}".format(width_sum/len(img_10), height_sum/len(img_10)))
print("width_max is {}, width_min is {}".format(width_max, width_min))
print("height_max is {}, height_min is {}".format(height_max, height_min))
def enhance():
img_10 = get_test_10_imgs()
H, W = 32, 32
sometimes = lambda aug: iaa.Sometimes(0.5, aug)
seq = iaa.Sequential([
iaa.Fliplr(0.5),
iaa.Flipud(0.2),
sometimes(iaa.Affine(
scale={"x": (0.8, 1.2), "y": (0.8, 1.2)}, # 图像缩放
rotate=(-45, 45), # 图像旋转
shear=(-16, 16), #剪切变换
)),
iaa.Crop(percent=(0, 0.1)),
# iaa.Resize({"height": H, "width": W})
])
img_augs = seq(images=img_10)
def make_rgb(img):
r = img[0]
g = img[1]
b = img[2]
ir = Image.fromarray(r)
ig = Image.fromarray(g)
ib = Image.fromarray(b)
rgb = Image.merge("RGB", (ir, ig, ib))
return rgb
for i in range(10):
plt.subplot(10, 2, 2*i + 1)
img_rgb = make_rgb(img_10[i])
plt.imshow(img_rgb)
plt.subplot(10, 2, 2 * i + 2)
img_aug_rgb = make_rgb(img_augs[i])
plt.imshow(img_aug_rgb)
plt.show()
if __name__ == '__main__':
get_all_data()
print_sizes()
enhance()
avg_width is 32.0, avg_height is 32.0
width_max is 32, width_min is 32
height_max is 32, height_min is 32

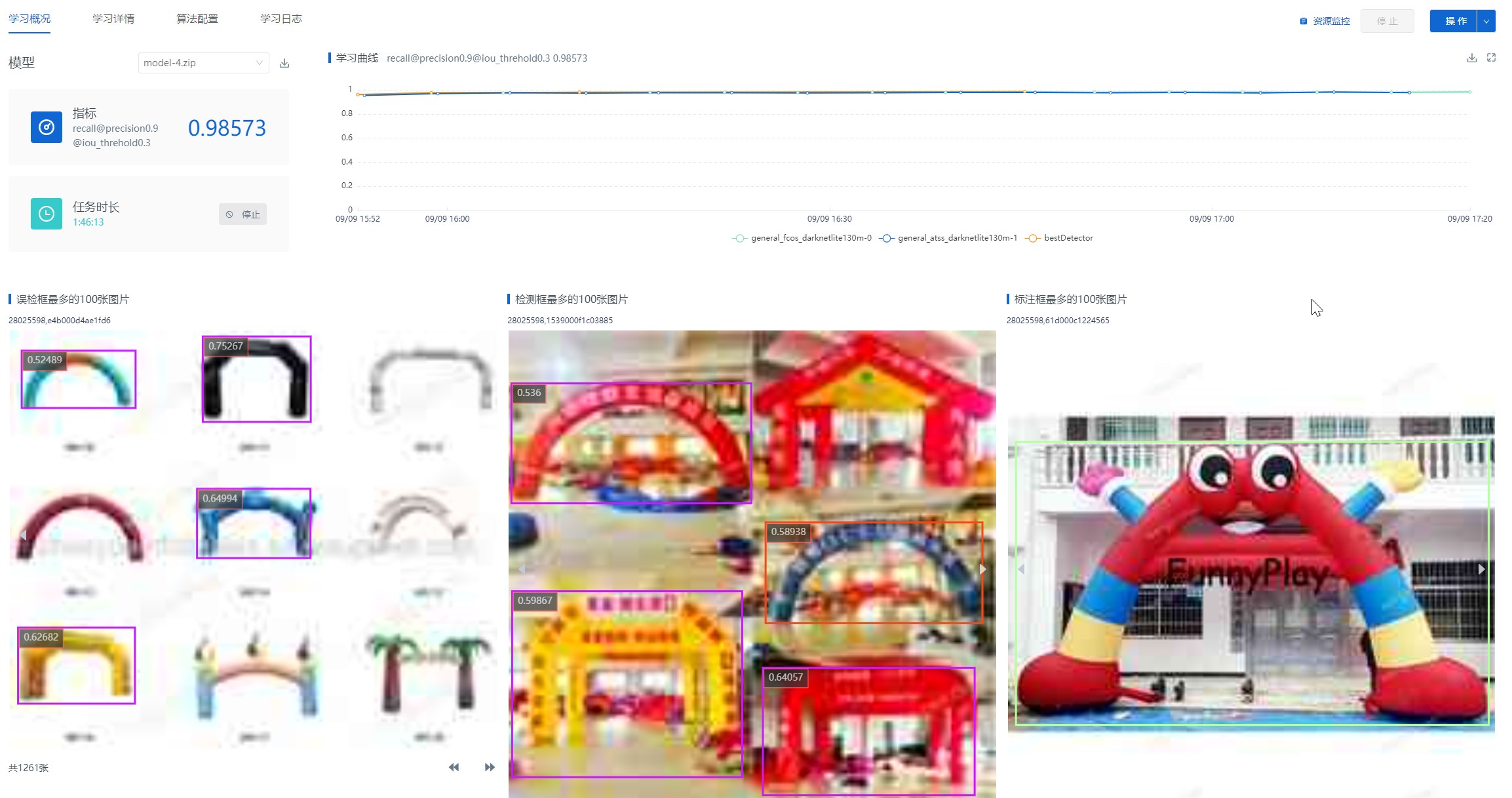
充气拱门地址:https://oss.iap.wh-a.brainpp.cn/liangmuxin-data-processing-oss/AI_training/class3/充气拱门/
已注册众智,并提交需求
import synonyms
print(synonyms.nearby("小吃", size=100)) # 获取近义词
爬虫结果在oss下面所有不是充气拱门的:
https://oss.iap.wh-a.brainpp.cn/liangmuxin-data-processing-oss/AI_training/class3/
import random
import cv2
import imgaug as ia
import numpy as np
from imgaug import augmenters as iaa
from refile import smart_open
from refile.smart import smart_path_join
from remisc.brainpp import get_oss_preview_url
from restore import nori_fetcher
"""
针对Imagenet数据(s3://ai-cultivate/1percent_ImageNet.txt),
进行基本的数据统计(统计框/图片的平均,最大,最小宽高),
数据预处理(对数据做旋转增强,randomcrop),
并做可视化分析对比数据处理前后的变化
"""
nf = nori_fetcher()
def load_nid_list(ds_path):
lst = list()
with smart_open(ds_path) as ds:
for line in ds:
nid, _, _ = line.split()
lst.append(nid)
return lst
def sampler(lst, number):
return random.sample(lst, number)
def decode_nori_image(nid):
return cv2.imdecode(
np.frombuffer(nf.get(nid), np.uint8),
cv2.IMREAD_COLOR,
)
def im_s3_write(
name,
npimg,
s3_root_path="s3://drx/ai",
quality=90,
):
dst_path = smart_path_join(s3_root_path, name)
with smart_open(dst_path, "wb") as f:
f.write(
cv2.imencode(".jpg", npimg, (cv2.IMWRITE_JPEG_QUALITY, quality))[
1
].tobytes()
)
return get_oss_preview_url(dst_path)
def imgs_vconcat(imgs):
return cv2.vconcat(imgs)
def imgs_hconcat(imgs):
return cv2.hconcat(imgs)
def main(ds_path):
nids = load_nid_list(ds_path)
nids = sampler(nids, 10)
# 数据统计(统计框/图片的平均,最大,最小宽高)
lst = [decode_nori_image(nid).shape for nid in nids]
arr = np.array(lst)
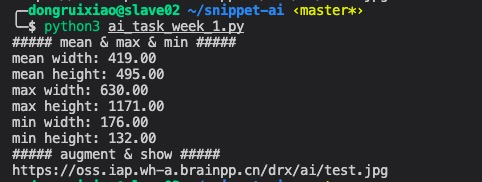
print("##### mean & max & min #####")
print("mean width: %.2f" % np.mean(arr[:, 1]))
print("mean height: %.2f" % np.mean(arr[:, 0]))
print("max width: %.2f" % np.max(arr[:, 1]))
print("max height: %.2f" % np.max(arr[:, 0]))
print("min width: %.2f" % np.min(arr[:, 1]))
print("min height: %.2f" % np.min(arr[:, 0]))
# 数据预处理(对数据做旋转增强,randomcrop)
imgs = [decode_nori_image(nid) for nid in nids]
seq = iaa.Sequential(
[
iaa.Resize({"width": 256, "height": 256}),
iaa.Crop(px=(0, 16)),
iaa.Fliplr(0.5),
iaa.GaussianBlur((0, 1.0)),
iaa.Affine(
scale={"x": (0.8, 1.2), "y": (0.8, 1.2)},
translate_percent={"x": (-0.2, 0.2), "y": (-0.2, 0.2)},
rotate=(-45, 45),
shear=(-16, 16),
cval=(0, 0),
mode=ia.ALL,
),
]
)
augimgs = seq.augment_images(imgs)
origin = imgs_hconcat([cv2.resize(img, (256, 256)) for img in imgs])
augimg = imgs_hconcat(augimgs)
output = imgs_vconcat([origin, augimg])
s3_url = im_s3_write("test.jpg", output)
print("##### augment & show #####")
print(s3_url)
if __name__ == "__main__":
ds_path = "s3://ai-cultivate/1percent_ImageNet.txt"
main(ds_path)
import megengine as mge
import megengine.functional as F
from megengine.autodiff import GradManager
from megengine.optimizer import SGD
import numpy as np
import matplotlib.pyplot as plt
def random_xandy_examples(n=100, noise=5):
k = np.random.randint(10, 20)
b = np.random.randint(-20, 20)
xarr = np.random.uniform(-10, 10, size=n)
narr = np.random.uniform(-noise, noise, size=n)
yarr = np.array([x * k + b + n for x, n in zip(xarr, narr)])
return xarr, yarr
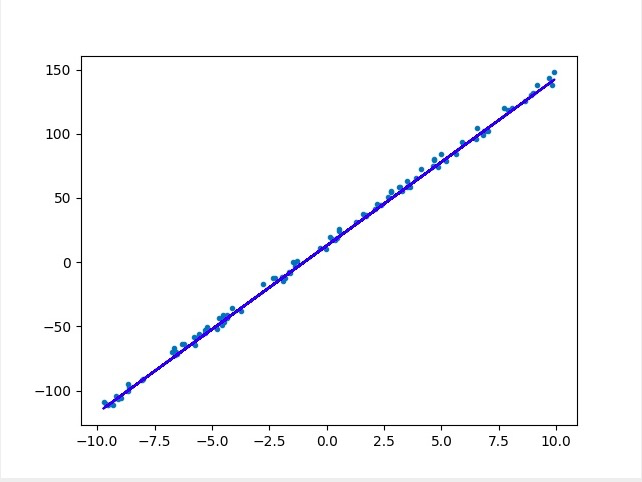
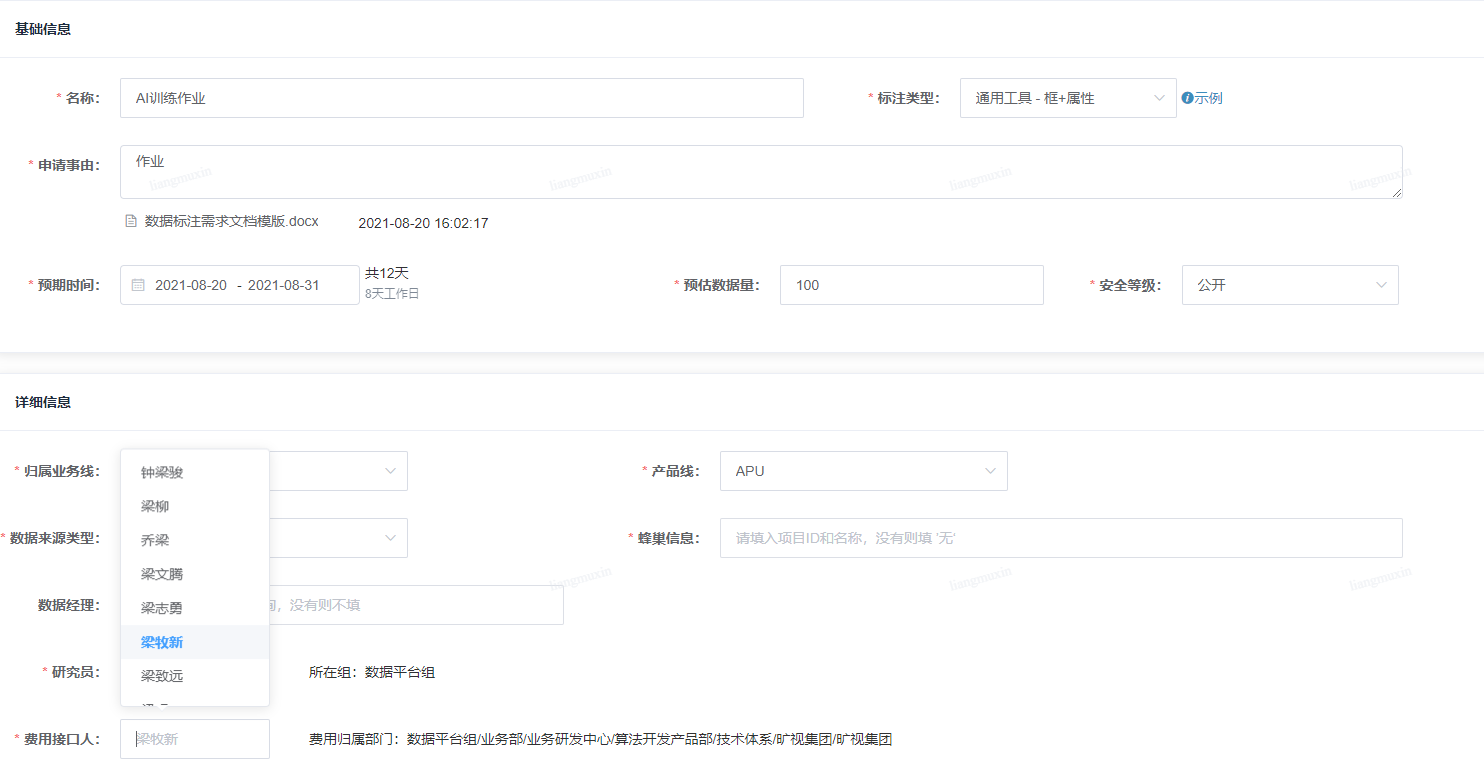
def plot_savefig(xs, ys, preds=None, name="ai_task_week_2.jpg"):
plt.figure()
plt.plot(xs, ys, ".")
if preds:
plt.plot(xs, preds, "-b")
plt.savefig(name)
def mge_train(data, label, epochs=100):
d = mge.Tensor(data)
l = mge.Tensor(label)
k = mge.Parameter([0.0])
b = mge.Parameter([0.0])
lr = 0.01
def linear_model(x):
return F.mul(x, k) + b
gm = GradManager().attach([k, b])
sgd = SGD([k, b], lr=lr)
for epoch in range(epochs):
with gm:
pred = linear_model(d)
loss = F.loss.square_loss(pred, l)
gm.backward(loss)
sgd.step().clear_grad()
print(epoch, k.item(), b.item(), loss.item())
return k.item(), b.item()
if __name__ == "__main__":
data, label = random_xandy_examples()
plot_savefig(data, label)
k, b = mge_train(data, label)
plot_savefig(data, label, preds=[k * x + b for x in data])
链接到 megstudio
# 这里写了一个稍微能异步点的爬虫
import os
import httpx
import asyncio
from remisc.brainpp import md5_str
import tqdm
import aiofiles
class BaiduSpider:
def __init__(
self,
keyword,
total_num,
start_num,
dst_path="/data/snippet-ai/images",
headers={},
num_per_page=30,
) -> None:
self._keyword = keyword
self._total_num = total_num
self._current_num = 0
self._start_num = start_num
self._prefix_url = "https://image.baidu.com/search/acjson?"
self._already_download = set()
self._dst_path = dst_path
os.makedirs(dst_path, exist_ok=True)
self._num_per_page = num_per_page
self._client = httpx.AsyncClient(headers=headers, http2=True)
async def _run(self):
with tqdm.tqdm(
desc="downloading: ",
total=self._total_num,
ascii=True,
) as pbar:
while self._current_num < self._total_num:
urlst = await self.get_url_list(self._start_num)
lst, _ = await asyncio.wait(
[asyncio.ensure_future(self.download(l)) for l in urlst],
return_when=asyncio.ALL_COMPLETED,
)
self._start_num += self._num_per_page
self._current_num += len(lst)
pbar.update(len(lst))
def run(self):
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.ensure_future(self._run()))
async def get_url_list(self, pageid):
param = {
"tn": "resultjson_com",
"logid": "8846269338939606587",
"ipn": "rj",
"ct": "201326592",
"is": "",
"fp": "result",
"queryWord": self._keyword,
"cl": "2",
"lm": "-1",
"ie": "utf-8",
"oe": "utf-8",
"adpicid": "",
"st": "-1",
"z": "",
"ic": "",
"hd": "",
"latest": "",
"copyright": "",
"word": self._keyword,
"s": "",
"se": "",
"tab": "",
"width": "",
"height": "",
"face": "0",
"istype": "2",
"qc": "",
"nc": "1",
"fr": "",
"expermode": "",
"force": "",
"cg": "girl",
"pn": pageid,
"rn": self._num_per_page,
"gsm": "1e",
}
res = await self._client.get(url=self._prefix_url, params=param)
print(res.url)
res.encoding = "utf-8"
ims = []
res_data = res.json(strict=False)["data"]
for img_url in res_data:
img_url = img_url.get("thumbURL")
if not img_url:
continue
if self._current_num > self._total_num:
print(f"Finished.")
return
if img_url in self._already_download:
continue
self._already_download.add(img_url)
ims.append(img_url)
print("Get imageset len: %s" % len(ims))
return ims
async def download(self, img_url):
print("Download image: %s" % img_url)
img = await self._client.get(img_url)
filename = os.path.basename(img_url)
async with aiofiles.open(
os.path.join(self._dst_path, "{}.jpg".format(md5_str(filename))),
"wb",
) as f:
await f.write(img.content)
if __name__ == "__main__":
headers = {
"User-Agent": "Mozilla/5.0(Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0",
"Referer": "https://image.baidu.com",
}
keyword = ""
for keyword in ["美食", "小吃", "特色菜", "传统美食", "特色美食"]:
try:
spider = BaiduSpider(
keyword,
total_num=20000,
start_num=0,
headers=headers,
dst_path="/data/snippet-ai/foos/{}".format(keyword),
)
spider.run()
except:
pass
#coding:utf-8
import boto3
import cv2
import nori2 as nori
import numpy as np
from imgaug import augmenters as iaa
from meghair.utils.imgproc import imdecode
s3_client = boto3.client('s3', endpoint_url="http://oss.i.brainpp.cn")
bucket = "ai-cultivate"
key="1percent_ImageNet.txt"
# 从 s3 读取文件,并将其转换成 mat 矩阵: numpy.ndarray
def read_img(bucket, key):
resp = s3_client.get_object(Bucket=bucket, Key=key)
# print(resp)
res = resp['Body'].read().decode('utf8')
data = res.split('\n')
# 取前十张照片操作
nori_ids = list(map(lambda x: x.split('\t')[0], data))[:10]
print(nori_ids)
fetcher = nori.Fetcher()
img_list = list(map(lambda x: imdecode(fetcher.get(x)), nori_ids)) # imdecode 将文件转成 mat 矩阵格式
return img_list
# 统计图片的大小 ,平均高度、最大高度、最小高度、平均宽度、最大宽度、最小宽度
def get_img_statistics(img_list):
img_size_list = []
for i, img in enumerate(img_list):
img_size_list.append({"img_num": "img_{}".format(i), "height": img.shape[0], "width": img.shape[1]})
# print(img_size_list)
height_list = [img_size['height'] for img_size in img_size_list]
width_list = [img_size['width'] for img_size in img_size_list]
# 求高度的平均值
avg_height = np.mean(height_list)
max_height = max(height_list)
min_height = min(height_list)
avg_width = np.mean(width_list)
max_width = max(width_list)
min_width = min(width_list)
img_info = {
'avg_height': avg_height,
'max_height': max_height,
'min_height': min_height,
'avg_width': avg_width,
'max_width': max_width,
'min_width': min_width,
'img_size': img_size_list
}
print("image statistic result: {}".format(img_info))
# 图片增强
def enhance_img(img_list):
H, W = 128, 128
NUM = 7 # 每张图要变换的张数
seq = iaa.Sequential([
iaa.Fliplr(0.5), # 水平翻转
iaa.Affine(
scale = {"x": (0.8, 1.2), "y": (0.8, 1.2)},
translate_px = {"x": (-16, 16), "y": (-16,16)},
rotate = (-45, 45)
),
iaa.Crop(px=(0, 16)),
iaa.GaussianBlur(sigma=(0, 2.0)),
iaa.Resize({"height": H, "width": W})
], random_order=True)
res = np.zeros(shape=((H + 10)* len(img_list), (W + 10)*NUM, 3),dtype = np.uint8)
for i, img in enumerate(img_list):
img_array = np.array([img] * NUM, dtype = np.uint8)
write_img = np.zeros(shape=(H, (W + 10)*NUM, 3), dtype=np.uint8)
images_aug = seq.augment_images(images=img_array)
for j, item in enumerate(images_aug):
write_img[:, j * (W+10): j * (W+10) + W, :] = item
res[i * (H+10): i*(H+10) + H, :, :] = write_img
# 将结果写到一张图中
#cv2.imshow("result", res)
cv2.imwrite('result.jpg', res)
if __name__ == '__main__':
img_list = read_img(bucket, key)
get_img_statistics(img_list)
enhance_img(img_list)
#coding:utf-8
import numpy as np
import matplotlib.pyplot as plt
import megengine as mge
import megengine.functional as F
from megengine.autodiff import GradManager
import megengine.optimizer as optim
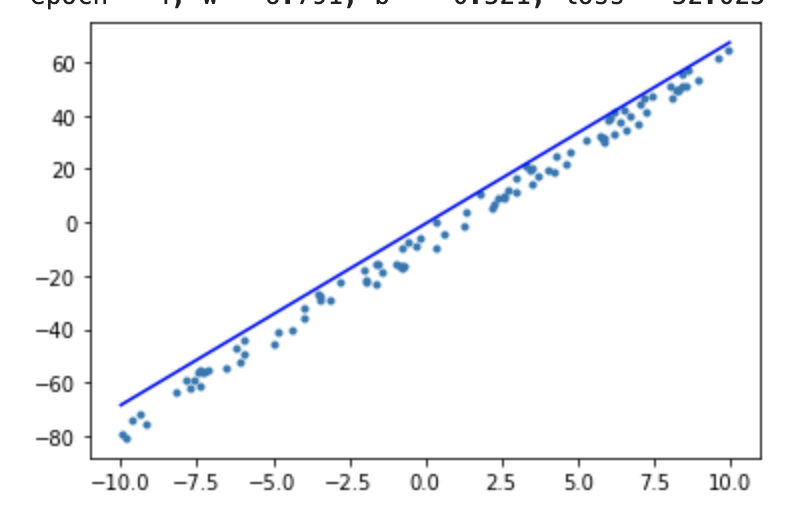
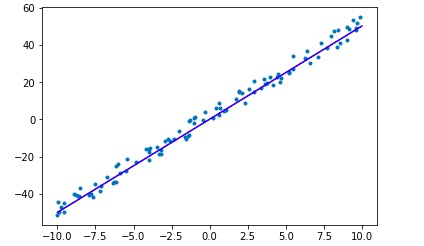
def generate_random_data(n = 100, noise = 5):
w = np.random.randint(5, 10)
b = np.random.randint(-10, 10)
print("The actual w: {}, b: {}".format(w, b))
# init data and label
data = np.zeros((n, ))
label = np.zeros((n, ))
# generate random data in the size of n, and noise to it
for i in range(n):
data[i] = np.random.uniform(-10, 10)
label[i] = w * data[i] + b + np.random.uniform(-noise, noise)
plt.scatter(data[i], label[i], marker = ".")
# show sample data
plt.plot()
plt.show()
return data, label
def linear_fitting(data, label):
epochs = 5
lr = 0.01
original_data, original_label = generate_random_data()
print(original_data, original_label)
# get data
data = mge.tensor(original_data)
label = mge.tensor(original_label)
# init parameter
w = mge.Parameter([0.0])
b = mge.Parameter([0.0])
# define model
def linear_model(x):
return F.mul(w, x) + b
# define gradmanager and optimizer
gm = GradManager().attach([w, b])
optimizer = optim.SGD([w, b], lr = lr)
for epoch in range(epochs):
with gm:
pred = linear_model(data)
loss = F.loss.square_loss(pred, label)
gm.backward(loss)
optimizer.step().clear_grad()
print("epoch = {}, w = {:.3f}, b = {:.3f}, loss = {:.3f}".format(epoch, w.item(), b.item(), loss.item()))
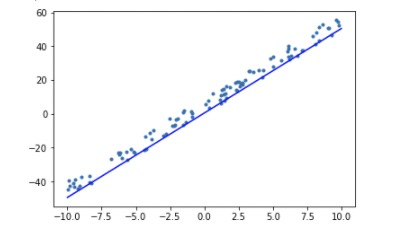
# check result
x = np.array([-10, 10])
y = w.numpy() * x + b.numpy()
plt.scatter(data, label, marker = ".")
plt.plot(x, y, "-b")
plt.show()
if __name__ == "__main__":
original_data, original_label = generate_random_data()
linear_fitting(original_data, original_label)
import megengine.module as M
import megengine.functional as F
import time
import numpy as np
import megengine as mge
from megengine.optimizer import SGD
from megengine.autodiff import GradManager
from megengine.data import DataLoader
from megengine.data.transform import ToMode, Pad, Normalize, Compose
from megengine.data.sampler import RandomSampler
from megengine.data.dataset import MNIST
from megengine.data.sampler import SequentialSampler
train_dataset = MNIST(root="/home/luona/examples/dataset/MNIST", train=True, download=False)
test_dataset = MNIST(root="/home/luona/examples/dataset/MNIST", train=False, download=False)
# 读取训练数据并进行预处理
dataloader = DataLoader(
train_dataset,
transform=Compose([
Normalize(mean=0.1307*255, std=0.3081*255),
Pad(2),
ToMode('CHW'),
]),
sampler=RandomSampler(dataset=train_dataset, batch_size=64), # 训练时一般使用RandomSampler来打乱数据顺序
)
# 读取测试数据
test_sampler = SequentialSampler(test_dataset, batch_size=500)
dataloader_test = DataLoader(
test_dataset,
sampler=test_sampler,
transform=Compose([
Normalize(mean=0.1307*255, std=0.3081*255),
Pad(2),
ToMode('CHW'),
]),
)
class LeNet(M.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = M.Conv2d(1, 6, 5)
self.relu1 = M.ReLU()
self.pool1 = M.MaxPool2d(2, 2)
self.conv2 = M.Conv2d(6, 16, 5)
self.relu2 = M.ReLU()
self.pool2 = M.MaxPool2d(2, 2)
self.fc1 = M.Linear(16 * 5 * 5, 120)
self.relu3 = M.ReLU()
self.fc2 = M.Linear(120, 84)
self.relu4 = M.ReLU()
self.classifier = M.Linear(84, 10)
def forward(self, x):
x = self.pool1(self.relu1(self.conv1(x)))
x = self.pool2(self.relu2(self.conv2(x)))
# F.flatten 将原本形状为(N, C, H, W)的张量 x 从第一个维度(即C)开始拉平成一个维度
# 得到的新的张量为(N, C*H*W),等价于 reshape 操作:x = x.reshape(x.shape[0], -1)
x = F.flatten(x, 1)
x = self.relu3(self.fc1(x))
x = self.relu4(self.fc2(x))
x = self.classifier(x)
return x
def train_func():
# 实例化网络
le_net = LeNet()
# SGD优化方法,学习率lr=0.05
optimizer = SGD(le_net.parameters(), lr=0.05)
gm = GradManager().attach(le_net.parameters())
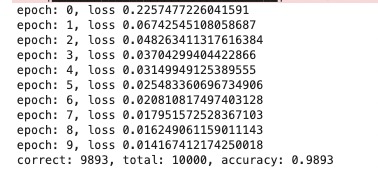
total_epochs = 10 # 共运行10个epoch
for epoch in range(total_epochs):
total_loss = 0
for step, (batch_data, batch_label) in enumerate(dataloader):
with gm:
pred = le_net(batch_data)
loss = F.loss.cross_entropy(pred, batch_label)
gm.backward(loss)
batch_label = batch_label.astype(np.int32)
optimizer.step().clear_grad() # 根据梯度更新参数值并将参数的梯度置零
total_loss += loss.numpy().item()
print("epoch: {}, loss {}".format(epoch, total_loss/len(dataloader)))
mge.save(le_net.state_dict(), 'mnist_net.mge')
def eval_func():
correct = 0
total = 0
le_net = LeNet()
state_dict = mge.load('mnist_net.mge')
le_net.load_state_dict(state_dict)
le_net.eval()
for idx, (batch_data, batch_label) in enumerate(dataloader_test):
batch_label = batch_label.astype(np.int32)
pred = le_net(batch_data)
loss = F.loss.cross_entropy(pred, batch_label)
predicted = pred.numpy().argmax(axis=1)
correct += (predicted == batch_label).sum().item()
total += batch_label.lsshape[0]
print("correct: {}, total: {}, accuracy: {}".format(correct, total, float(correct) / total))
if __name__ == "__main__":
train_func()
eval_func()
结果
代码
#coding:utf-8
import boto3
import cv2
import nori2 as nori
import numpy as np
from imgaug import augmenters as iaa
from meghair.utils.imgproc import imdecode
s3_client = boto3.client(‘s3’, endpoint_url=“http://oss.i.brainpp.cn”)
bucket = “ai-cultivate”
key=“1percent_ImageNet.txt”
def read_img(bucket, key):
resp = s3_client.get_object(Bucket=bucket, Key=key)
# print(resp)
res = resp[‘Body’].read().decode(‘utf8’)
data = res.split(’\n’)
# 取前十张照片操作
nori_ids = list(map(lambda x: x.split(’\t’)[0], data))[:10]
print(nori_ids)
fetcher = nori.Fetcher()
img_list = list(map(lambda x: imdecode(fetcher.get(x)), nori_ids)) # imdecode 将文件转成 mat 矩阵格式
return img_list
def get_img_statistics(img_list):
img_size_list =
for i, img in enumerate(img_list):
img_size_list.append({“img_num”: “img_{}”.format(i), “height”: img.shape[0], “width”: img.shape[1]})
height_list = [img_size['height'] for img_size in img_size_list]
width_list = [img_size['width'] for img_size in img_size_list]
# 求高度的平均值
avg_height = np.mean(height_list)
max_height = max(height_list)
min_height = min(height_list)
avg_width = np.mean(width_list)
max_width = max(width_list)
min_width = min(width_list)
img_info = {
'avg_height': avg_height,
'max_height': max_height,
'min_height': min_height,
'avg_width': avg_width,
'max_width': max_width,
'min_width': min_width,
'img_size': img_size_list
}
print("image statistic result: {}".format(img_info))
def enhance_img(img_list):
H, W = 128, 128
NUM = 7 # 每张图要变换的张数
seq = iaa.Sequential([
iaa.Fliplr(0.5), # 水平翻转
iaa.Affine(
scale = {"x": (0.8, 1.2), "y": (0.8, 1.2)},
translate_px = {"x": (-16, 16), "y": (-16,16)},
rotate = (-45, 45)
),
iaa.Crop(px=(0, 16)),
iaa.GaussianBlur(sigma=(0, 2.0)),
iaa.Resize({"height": H, "width": W})
], random_order=True)
res = np.zeros(shape=((H + 10)* len(img_list), (W + 10)*NUM, 3),dtype = np.uint8)
for i, img in enumerate(img_list):
img_array = np.array([img] * NUM, dtype = np.uint8)
write_img = np.zeros(shape=(H, (W + 10)*NUM, 3), dtype=np.uint8)
images_aug = seq.augment_images(images=img_array)
for j, item in enumerate(images_aug):
write_img[:, j * (W+10): j * (W+10) + W, :] = item
res[i * (H+10): i*(H+10) + H, :, :] = write_img
# 将结果写到一张图中
#cv2.imshow("result", res)
cv2.imwrite('result.jpg', res)
if name == ‘main’:
img_list = read_img(bucket, key)
get_img_statistics(img_list)
enhance_img(img_list)
充气拱门地址:
标注需求文档:
清洗需求文档:
爬虫代码
# -*- coding:utf-8 -*-
import os
import json
import time
import requests
import hashlib
from tqdm import tqdm
def download_img(img_path, img_name):
r = requests.get(img_path)
with open(f'{out_path}/{img_name}.jpg', 'wb') as f:
f.write(r.content)
def structure(img):
img_list = []
for i in img:
if i == {}:
continue
md5 = hashlib.md5(i['thumbURL'].encode(encoding='utf-8')).hexdigest()
item_dict = {'k': md5, 'img_url': i['thumbURL']}
img_list.append(item_dict)
return img_list
def request():
response = requests.get('https://image.baidu.com/search/acjson', headers=headers, params=params, cookies=cookies)
return response.json()
def params_setting(page, key_word):
cookies = {
'BDIMGISLOGIN': '0',
'winWH': '%5E6_1440x699',
'BDqhfp': '%25B3%25E4%25C6%25F8%25B9%25B0%25C3%25C5%26%26NaN-1undefined%26%260%26%261',
'BIDUPSID': '36D9A2C93610090C3C9A3937C9EA128D',
'PSTM': '1595555978',
'indexPageSugList': '%5B%22%E9%80%BB%E8%BE%91%E6%80%9D%E7%BB%B4%22%2C%22%E6%B5%81%E7%A8%8B%E9%80%BB%E8%BE%91%E6%80%9D%E7%BB%B4%22%2C%22%E5%A4%A7%E8%AF%9D%E8%A5%BF%E6%B8%B83%22%5D',
'__yjs_duid': '1_e946059cf24a26eff06b8ed1dca9e7ae1620355297511',
'BAIDUID': '52AA2933E5EAA8A53BBF9791B438111A:FG=1',
'MCITY': '-308%3A179%3A',
'BDORZ': 'B490B5EBF6F3CD402E515D22BCDA1598',
'BDSFRCVID': 'imPOJeC62wSG_YoHXB__-OtlVD5f_j6TH6aoCaKyPtZrNiqGvke-EG0PHx8g0K4bgYPFogKKKgOTHICF_2uxOjjg8UtVJeC6EG0Ptf8g0M5',
'H_BDCLCKID_SF': 'tbAHoC_yJII3fP36qR325-K_hl-X5-CsLCIO2hcH0KLKMMJKLRCbyMAYhnKLWb3QQebGQU5j2fb1MRjvWfRs2b0yyGQp35Q3Kb6Q5h5TtUJpeCnTDMRN-lD4bpryKMniWKv9-pnY0hQrh459XP68bTkA5bjZKxtq3mkjbPbDfn02eCKuDT-KDjjbjaus-bbfHjRjLnQqat8_Hnurb6t2XUI8LNDHtpOp0jLfapRPQqAV8Pb13x7IKhLsMRO7ttoyym33XPbbWDj4EI5d-TQSLUL1Db34KjvMtg3C3fow5-ToepvoyPJc3MkPLPjdJJQOBKQB0KnGbUQkeq8CQft20b0EeMtjKjLEtbufVCtatKL3DJjnq4cH-nkEqxby26n4L4j9aJ5nJDoAVfngM6J1XhLn-gc9-P7p2jcZhx-aQpP-HJ7PLlbqMT8P5h57tlvB3evRKl0MLPOtbb0xynoD2-KrKMnMBMni52OnapTn3fAKftnOM46JehL3346-35543bRTLnLy5KJtMDF4jj_Wjj53epJf-K6K-TRQ06rJabC_Hnurh4JzXUI8LNDHt-QkQGvXaUDKMn0V8Pb13x7YL6DsMRO7ttoytDnP-ILbt-cY_Inc-UQoQxL1Db3JL6vMtg3tsR5TKh5oepvoyPJc3MkPLPjdJJQOBKQB0KnGbUQkeq8CQft20b0EeMtjW6LEtJkfoI0bfCK3HR-kbn0aejOLqxby26n0aGR9aJ5nJDobVp33Wtn1WMDmBgc9-P7p3nThMbFKQpP-HJ7J-fRB0b0lK4T0bxbq2KILKl0MLpnWbb0xyTODbpFrQxnMBMni52OnapTn3fAKftnOM46JehL3346-35543bRTLnLy5KJYMDcnK4-XDT50eH3P',
'BDSFRCVID_BFESS': 'imPOJeC62wSG_YoHXB__-OtlVD5f_j6TH6aoCaKyPtZrNiqGvke-EG0PHx8g0K4bgYPFogKKKgOTHICF_2uxOjjg8UtVJeC6EG0Ptf8g0M5',
'H_BDCLCKID_SF_BFESS': 'tbAHoC_yJII3fP36qR325-K_hl-X5-CsLCIO2hcH0KLKMMJKLRCbyMAYhnKLWb3QQebGQU5j2fb1MRjvWfRs2b0yyGQp35Q3Kb6Q5h5TtUJpeCnTDMRN-lD4bpryKMniWKv9-pnY0hQrh459XP68bTkA5bjZKxtq3mkjbPbDfn02eCKuDT-KDjjbjaus-bbfHjRjLnQqat8_Hnurb6t2XUI8LNDHtpOp0jLfapRPQqAV8Pb13x7IKhLsMRO7ttoyym33XPbbWDj4EI5d-TQSLUL1Db34KjvMtg3C3fow5-ToepvoyPJc3MkPLPjdJJQOBKQB0KnGbUQkeq8CQft20b0EeMtjKjLEtbufVCtatKL3DJjnq4cH-nkEqxby26n4L4j9aJ5nJDoAVfngM6J1XhLn-gc9-P7p2jcZhx-aQpP-HJ7PLlbqMT8P5h57tlvB3evRKl0MLPOtbb0xynoD2-KrKMnMBMni52OnapTn3fAKftnOM46JehL3346-35543bRTLnLy5KJtMDF4jj_Wjj53epJf-K6K-TRQ06rJabC_Hnurh4JzXUI8LNDHt-QkQGvXaUDKMn0V8Pb13x7YL6DsMRO7ttoytDnP-ILbt-cY_Inc-UQoQxL1Db3JL6vMtg3tsR5TKh5oepvoyPJc3MkPLPjdJJQOBKQB0KnGbUQkeq8CQft20b0EeMtjW6LEtJkfoI0bfCK3HR-kbn0aejOLqxby26n0aGR9aJ5nJDobVp33Wtn1WMDmBgc9-P7p3nThMbFKQpP-HJ7J-fRB0b0lK4T0bxbq2KILKl0MLpnWbb0xyTODbpFrQxnMBMni52OnapTn3fAKftnOM46JehL3346-35543bRTLnLy5KJYMDcnK4-XDT50eH3P',
'BDRCVFR[dG2JNJb_ajR]': 'mk3SLVN4HKm',
'BDRCVFR[-pGxjrCMryR]': 'mk3SLVN4HKm',
'delPer': '0',
'BAIDUID_BFESS': 'AE40B36E8C844268FB79E22A60250249:FG=1',
'PSINO': '1',
'H_PS_PSSID': '34399_31253_34402_33848_34092_26350_34416_34323_22160_34390_34360',
'BA_HECTOR': '040k812g2k258584vl1ghs2730q',
'userFrom': 'null',
'ab_sr': '1.0.1_MDdjYzdiZDZiMTA5YWE4OGYyMzMxMmNkZmE4MzZlYTMzZWQ1NGQ2MzQxYTNjMzNlNGJmMTA3MWNhZDI4YzYyYWY2YTE1NDkxY2JlNzk0Njc0NDA3N2QwMDRkNmY1NjQ5ZjQwNDQ0NTA2ZDQ5MTViNTlkOGMwM2UwYjM4NDRmY2RiOWExOGIzM2U1YzA1NWFmNmRiZTc3YzZkNmU0MmY3Nw==',
}
headers = {
'Connection': 'keep-alive',
'sec-ch-ua': '"Chromium";v="92", " Not A;Brand";v="99", "Google Chrome";v="92"',
'Accept': 'text/plain, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'sec-ch-ua-mobile': '?0',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'Referer': 'https://image.baidu.com/search/index?tn=baiduimage&ct=201326592&lm=-1&cl=2&ie=gb18030&word=%B3%E4%C6%F8%B9%B0%C3%C5&fr=ala&ala=1&alatpl=normal&pos=0',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
params = (
('tn', 'resultjson_com'),
('logid', '9438258111815632343'),
('ipn', 'rj'),
('ct', '201326592'),
('is', ''),
('fp', 'result'),
('queryWord', key_word),
('cl', '2'),
('lm', '-1'),
('ie', 'utf-8'),
('oe', 'utf-8'),
('adpicid', ''),
('st', ''),
('z', ''),
('ic', ''),
('hd', ''),
('latest', ''),
('copyright', ''),
('word', key_word),
('s', ''),
('se', ''),
('tab', ''),
('width', ''),
('height', ''),
('face', ''),
('istype', ''),
('qc', ''),
('nc', ''),
('fr', ''),
('expermode', ''),
('nojc', ''),
('pn', page),
('rn', '30'),
('gsm', '3c'),
('1629358426248', ''),
)
return cookies, headers, params
if __name__ == '__main__':
num = 30
# 获取前10页
total_page = 10
# 关键字
key_word = '充气拱门'
out_path = f'/Users/megvii/Desktop/AI培训/{key_word}'
if not os.path.exists(out_path):
os.makedirs(out_path)
for i in range(total_page):
page = (i+1) * num
cookies, headers, params = params_setting(page, key_word)
data = request()
print('正在获取{}页的图片数据,请耐心等待.....'.format(i+1))
img_list = structure(data['data'])
print('本页共:{}张图片,正在下载.....'.format(len(img_list)))
print(json.dumps(img_list))
for i2 in tqdm(img_list, total=len(img_list)):
time.sleep(0.2)
download_img(i2['img_url'], i2['k'])
correct: 8758, total: 10000, accuracy: 87.58%
https://studio.brainpp.com/project/10953?name=AI培训课后作业(3_4)_douwenhao_作业

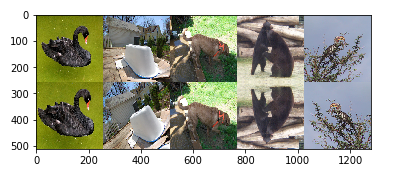
code:
https://git-core.megvii-inc.com/-/ide/project/ai_train/ai-liugaohua/blob/master/-/week1/week1.py
爬取的小吃图片已经上传到小组群
训练了60个epoch:
correct: 8568, total: 10000, accuracy: 85.68%
项目详情 | MegStudio (brainpp.com)
由于训练时间太长,并且没找到中断后恢复的方法,最后减少了epoch数量
09 06:22:47 epoch 9 Step 7900, LR 0.0125, Loss 0.146 (0.355) Acc@1 100.000 (83.625) Time 0.210 (0.222)
项目详情 | MegStudio (brainpp.com)









{kind=link}
{kind=link}
{kind=link}