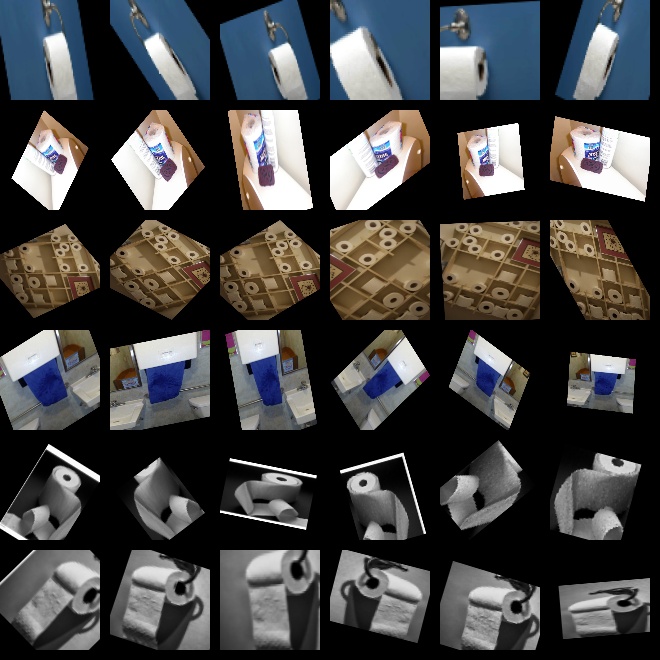
第一周作业题目链接:【AI培训第四期第一周课后作业】
第二周作业题目链接:【AI培训第四期第二周课后作业】
第三周作业题目链接:【AI培训第四期第三周课后作业】
【AI-CAMP四期】第二组作业
拱晓晨的作业
第一周个人作业
import boto3
import cv2
import nori2 as nori
import numpy as np
from imgaug import augmenters as iaa
from meghair.utils.imgproc import imdecode
endpoint_url="http://oss.i.brainpp.cn"
bucket = "ai-cultivate"
key = "1percent_ImageNet.txt"
s3_client = boto3.client('s3', endpoint_url="http://oss.i.brainpp.cn")
# 获取图像
def read_images(bucket, key):
txt_file = s3_client.get_object(Bucket=bucket, Key=key)
data = txt_file['Body'].read().decode("utf8").split('\n')
nori_ids = list(map(lambda x: x.split('\t')[0], data))[20:30]
fetcher = nori.Fetcher()
images = list(map(lambda x: imdecode(fetcher.get(x)), nori_ids))
return images
# 获取图像统计数据
def get_statistics(images):
height_list = []
width_list = []
for image in images:
height_list.append(image.shape[0])
width_list.append(image.shape[1])
avg_height = np.mean(height_list)
max_height = max(height_list)
min_height = min(height_list)
avg_width = np.mean(width_list)
max_width = max(width_list)
min_width = min(width_list)
statistics = {
'avg_height': avg_height,
'max_height': max_height,
'min_height': min_height,
'avg_width': avg_width,
'max_width': max_width,
'min_width': min_width}
print("统计数据: {}".format(statistics))
return
# 增强图像
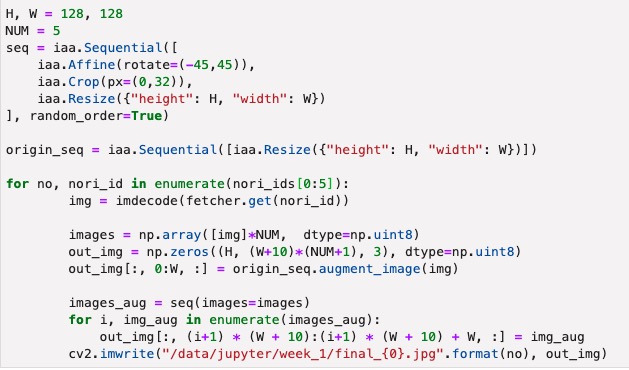
def augment_image(images):
H, W = 128, 128
NUM = 5
sometimes = lambda aug: iaa.Sometimes(0.5, aug)
ori_seq = iaa.Sequential([iaa.Resize({"height": H, "width": W})])
seq = iaa.Sequential([
iaa.Fliplr(0.5), # 50%的图像镜像翻转
iaa.Flipud(0.2), # 20%的图像左右翻转
iaa.Crop(percent=(0, 0.1)), # 四边以0 - 0.1之间的比例像素剪裁
sometimes(iaa.Affine( # 对一部分图像做仿射变换
scale={"x": (0.8, 1.2), "y": (0.8, 1.2)}, # 图像缩放80%-120%
rotate=(-45, 45) # ±45度旋转
)),
iaa.GaussianBlur(sigma=(0, 2.0)), # 高斯模糊
iaa.Resize({"height": H, "width": W})
], random_order=True)
res = np.zeros(shape=((H + 10) * len(images), (W + 10) * (NUM + 1), 3), dtype=np.uint8)
for i, image in enumerate(images):
image_array = np.array([image] * NUM, dtype=np.uint8)
write_image = np.zeros(shape=(H, (W + 10) * (NUM + 1), 3), dtype=np.uint8)
ori_image = ori_seq.augment_image(image)
write_image[:, 0: W, :] = ori_image
images_aug = seq.augment_images(images=image_array)
for j, item in enumerate(images_aug):
write_image[:, (j + 1) * (W + 10): (j + 1) * (W + 10) + W, :] = item
res[i * (H + 10): i * (H + 10) + H, :, :] = write_image
cv2.imwrite("results.jpg", res)
if __name__ == "__main__":
images = read_images(bucket, key)
get_statistics(images)
augment_image(images)
统计数据: {‘avg_height’: 363.3, ‘max_height’: 683, ‘min_height’: 110, ‘avg_width’: 512.9, ‘max_width’: 1024, ‘min_width’: 176}

第二周个人作业
已在MegStudio上提交 作业项目链接
第二周小组作业(拱晓晨 褚兮铭组):
import numpy as np
import megengine as mge
import megengine.functional as F
from megengine.data.dataset import MNIST
from megengine.data import SequentialSampler, RandomSampler, DataLoader
from megengine.autodiff import GradManager
import megengine.optimizer as optim
MNIST_DATA_PATH = "/data/homework/dataset/MINST" # 记得修改这里的路径
# 设置超参数
bs = 64
lr = 1e-6
epochs = 5
# 读取原始数据集
train_dataset = MNIST(root=MNIST_DATA_PATH, train=True, download=False)
num_features = train_dataset[0][0].size
num_classes = 10
# 训练数据加载与预处理
train_sampler = SequentialSampler(dataset=train_dataset, batch_size=bs)
train_dataloader = DataLoader(dataset=train_dataset, sampler=train_sampler)
# 初始化参数
W = mge.Parameter(np.zeros((num_features, num_classes)))
b = mge.Parameter(np.zeros((num_classes,)))
# 定义模型
def linear_cls(X):
return F.matmul(X, W) + b
# 定义求导器和优化器
gm = GradManager().attach([W, b])
optimizer = optim.SGD([W, b], lr=lr)
# 模型训练
for epoch in range(epochs):
total_loss = 0
for batch_data, batch_label in train_dataloader:
batch_data = F.flatten(mge.tensor(batch_data), 1).astype("float32")
batch_label = mge.tensor(batch_label)
with gm:
pred = linear_cls(batch_data)
loss = F.loss.cross_entropy(pred, batch_label)
gm.backward(loss)
optimizer.step().clear_grad()
total_loss += loss.item()
print("epoch = {}, loss = {:.6f}".format(epoch+1, total_loss / len(train_dataset)))
06 12:44:54 process the raw files of train set…
100%|██████████████████████████████████| 60000/60000 [00:03<00:00, 16832.05it/s]
100%|████████████████████████████████| 60000/60000 [00:00<00:00, 1509810.54it/s]
06 12:44:58[mgb] WRN cuda unavailable: no CUDA-capable device is detected(100) ndev=-1
epoch = 1, loss = 0.008332
epoch = 2, loss = 0.005662
epoch = 3, loss = 0.005243
epoch = 4, loss = 0.005026
epoch = 5, loss = 0.004887
test_dataset = MNIST(root=MNIST_DATA_PATH, train=False, download=False)
test_sampler = RandomSampler(dataset=test_dataset, batch_size=bs)
test_dataloader = DataLoader(dataset=test_dataset, sampler=test_sampler)
nums_correct = 0
for batch_data, batch_label in test_dataloader:
batch_data = F.flatten(mge.tensor(batch_data), 1).astype("float32")
batch_label = mge.tensor(batch_label)
logits = linear_cls(batch_data)
pred = F.argmax(logits, axis=1)
nums_correct += (pred == batch_label).sum().item()
print("Accuracy = {:.3f}".format(nums_correct / len(test_dataset)))
06 12:45:25 process the raw files of test set…
100%|██████████████████████████████████| 10000/10000 [00:00<00:00, 16922.16it/s]
100%|████████████████████████████████| 10000/10000 [00:00<00:00, 1518135.23it/s]
Accuracy = 0.917
李仁君的作业:
第一周
#https://discourse.brainpp.cn/t/topic/848
import boto3
import nori2 as nori
from meghair.utils.imgproc import imdecode
import numpy as np
from imgaug import augmenters as iaa
import cv2
host = "http://oss.i.brainpp.cn/"
bucket = "ai-cultivate"
key = "1percent_ImageNet.txt"
s3_client = boto3.client('s3', endpoint_url=host)
def read_img():
image_res = s3_client.get_object(Bucket=bucket, Key=key)
image_data = image_res['Body'].read().decode("utf8")
images = image_data.split('\n')
nori_ids = list(map(lambda x: x.split('\t')[0], images))[-7:-1:1]
fetcher = nori.Fetcher()
imgs = list(map(lambda x: imdecode(fetcher.get(x)), nori_ids))
return imgs
def compare(imgs):
height_list = []
width_list = []
for i,img in enumerate(imgs):
height_list.append(img.shape[0])
width_list.append(img.shape[1])
avg_height = np.mean(height_list)
avg_width = np.mean(width_list)
max_height = max(height_list)
max_width = max(width_list)
min_height = min(height_list)
min_width = min(width_list)
img_info = {'avg_height':avg_height,'avg_width':avg_width,'max_height':max_height,'max_width':max_width,'min_height':min_height,'min_width':min_width}
print(img_info)
def augmenters_img(imgs):
H, W = 100, 100
NUM = 6
seq = iaa.Sequential([
iaa.Fliplr(0.5), # 图像的50%概率水平翻转
iaa.Crop(px=(0, 25)), # 四边以0 - 25像素剪裁
iaa.Affine(
scale={"x": (0.5, 1.2), "y": (0.5, 1.2)}, # 图像缩放
translate_px={"x": (-6, 16), "y": (-6, 16)}, # 像素随机平移
rotate=(-30, 60) # 旋转-30度或60度
),
iaa.GaussianBlur(sigma=(0, 2.0)), # 高斯模糊
iaa.Resize({"height": H, "width": W})
], random_order=True)
res = np.zeros(shape=((H + 10) * len(imgs), (W + 10) * NUM, 3), dtype=np.uint8)
for i, img in enumerate(imgs):
img_array = np.array([img] * NUM, dtype=np.uint8)
write_img = np.zeros(shape=(H, (W + 10) * NUM, 3), dtype=np.uint8)
images_aug = seq.augment_images(images=img_array)
for j, item in enumerate(images_aug):
write_img[:, j * (W + 10): j * (W + 10) + W, :] = item
res[i * (H + 10): i * (H + 10) + H, :, :] = write_img
cv2.imwrite("augmenters.jpg", res)
if __name__ == '__main__':
imgs = read_img()
compare(imgs)
augmenters_img(imgs)
结果:
{'avg_height': 408.0, 'avg_width': 476.5, 'max_height': 500, 'max_width': 654, 'min_height': 330, 'min_width': 330}
图片:
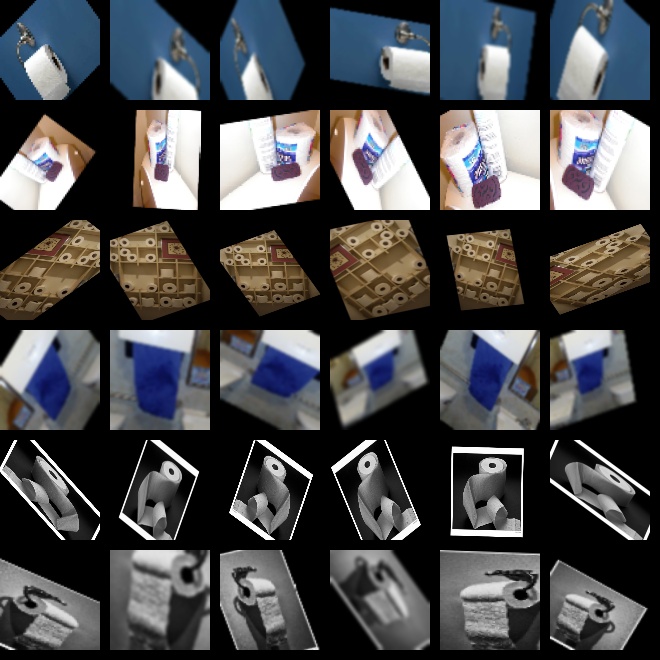
褚兮铭的作业:
第一周个人作业:
import boto3
import cv2
import nori2 as nori
import numpy as np
from imgaug import augmenters as iaa
from meghair.utils.imgproc import imdecode
s3_client = boto3.client('s3', endpoint_url="http://oss.i.brainpp.cn")
bucket = "ai-cultivate"
key = "1percent_ImageNet.txt"
# 读图
def read_img(bucket, key):
txt_file = s3_client.get_object(Bucket=bucket, Key=key)
data = txt_file['Body'].read().decode("utf8").split('\n')
nori_ids = list(map(lambda x: x.split('\t')[0], data))[-11:-1:1]
fetcher = nori.Fetcher()
img_list = list(map(lambda x: imdecode(fetcher.get(x)), nori_ids))
return img_list
# 统计
def get_img_statistics(img_list):
height_list = []
width_list = []
for img in img_list:
height_list.append(img.shape[0])
width_list.append(img.shape[1])
avg_height = np.mean(height_list)
max_height = max(height_list)
min_height = min(height_list)
avg_width = np.mean(width_list)
max_width = max(width_list)
min_width = min(width_list)
img_info = {'avg_height': avg_height, 'max_height': max_height, 'min_height': min_height,
'avg_width': avg_width, 'max_width': max_width, 'min_width': min_width}
print("图片信息统计结果: {}".format(img_info))
return
# 图片增强
def enhance_img(img_list):
H, W = 128, 128
NUM = 5
ori_seq = iaa.Sequential([iaa.Resize({"height": H, "width": W})])
seq = iaa.Sequential([
iaa.Fliplr(0.5), # 图像的50%概率水平翻转
iaa.Crop(percent=(0, 0.1)), # 四边以0 - 0.1之间的比例像素剪裁
iaa.Affine(
scale={"x": (0.8, 1.2), "y": (0.8, 1.2)}, # 图像缩放
rotate=(-90, 90) # 旋转-90度或90度
),
iaa.GaussianBlur(sigma=(0, 2.0)), # 高斯模糊
iaa.Resize({"height": H, "width": W})
], random_order=True)
res = np.zeros(shape=((H + 10) * len(img_list), (W + 10) * (NUM + 1), 3), dtype=np.uint8)
for i, img in enumerate(img_list):
img_array = np.array([img] * NUM, dtype=np.uint8)
write_img = np.zeros(shape=(H, (W + 10) * (NUM + 1), 3), dtype=np.uint8)
ori_img = ori_seq.augment_image(img)
write_img[:, 0: W, :] = ori_img
images_aug = seq.augment_images(images=img_array)
for j, item in enumerate(images_aug):
write_img[:, (j + 1) * (W + 10): (j + 1) * (W + 10) + W, :] = item
# 结果写在一张图片里
res[i * (H + 10): i * (H + 10) + H, :, :] = write_img
cv2.imwrite("new_result.jpg", res)
if __name__ == "__main__":
images = read_img(bucket, key)
get_img_statistics(images)
enhance_img(images)
图片信息统计结果: {‘avg_height’: 410.6, ‘max_height’: 500, ‘min_height’: 325, ‘avg_width’: 469.2, ‘max_width’: 654, ‘min_width’: 330}
结果图片:(每行第一张图为Resize后的原图)

第二周个人作业:
MegStudio提交
https://studio.brainpp.com/project/10461?name=AI培训课后作业(4_2)_chuximing_作业
第二周小组作业(拱晓晨 褚兮铭组):
import numpy as np
import megengine as mge
import megengine.functional as F
from megengine.data.dataset import MNIST
from megengine.data import SequentialSampler, RandomSampler, DataLoader
from megengine.autodiff import GradManager
import megengine.optimizer as optim
MNIST_DATA_PATH = "/data/homework/dataset/MINST" # 记得修改这里的路径
# 设置超参数
bs = 64
lr = 1e-6
epochs = 5
# 读取原始数据集
train_dataset = MNIST(root=MNIST_DATA_PATH, train=True, download=False)
num_features = train_dataset[0][0].size
num_classes = 10
# 训练数据加载与预处理
train_sampler = SequentialSampler(dataset=train_dataset, batch_size=bs)
train_dataloader = DataLoader(dataset=train_dataset, sampler=train_sampler)
# 初始化参数
W = mge.Parameter(np.zeros((num_features, num_classes)))
b = mge.Parameter(np.zeros((num_classes,)))
# 定义模型
def linear_cls(X):
return F.matmul(X, W) + b
# 定义求导器和优化器
gm = GradManager().attach([W, b])
optimizer = optim.SGD([W, b], lr=lr)
# 模型训练
for epoch in range(epochs):
total_loss = 0
for batch_data, batch_label in train_dataloader:
batch_data = F.flatten(mge.tensor(batch_data), 1).astype("float32")
batch_label = mge.tensor(batch_label)
with gm:
pred = linear_cls(batch_data)
loss = F.loss.cross_entropy(pred, batch_label)
gm.backward(loss)
optimizer.step().clear_grad()
total_loss += loss.item()
print("epoch = {}, loss = {:.6f}".format(epoch+1, total_loss / len(train_dataset)))
06 12:44:54 process the raw files of train set…
100%|██████████████████████████████████| 60000/60000 [00:03<00:00, 16832.05it/s]
100%|████████████████████████████████| 60000/60000 [00:00<00:00, 1509810.54it/s]
06 12:44:58[mgb] WRN cuda unavailable: no CUDA-capable device is detected(100) ndev=-1
epoch = 1, loss = 0.008332
epoch = 2, loss = 0.005662
epoch = 3, loss = 0.005243
epoch = 4, loss = 0.005026
epoch = 5, loss = 0.004887
test_dataset = MNIST(root=MNIST_DATA_PATH, train=False, download=False)
test_sampler = RandomSampler(dataset=test_dataset, batch_size=bs)
test_dataloader = DataLoader(dataset=test_dataset, sampler=test_sampler)
nums_correct = 0
for batch_data, batch_label in test_dataloader:
batch_data = F.flatten(mge.tensor(batch_data), 1).astype("float32")
batch_label = mge.tensor(batch_label)
logits = linear_cls(batch_data)
pred = F.argmax(logits, axis=1)
nums_correct += (pred == batch_label).sum().item()
print("Accuracy = {:.3f}".format(nums_correct / len(test_dataset)))
06 12:45:25 process the raw files of test set…
100%|██████████████████████████████████| 10000/10000 [00:00<00:00, 16922.16it/s]
100%|████████████████████████████████| 10000/10000 [00:00<00:00, 1518135.23it/s]
Accuracy = 0.917
苗建伟的作业:
第一周个人作业
#coding:utf-8
import boto3
import cv2
import nori2 as nori
import numpy as np
from imgaug import augmenters as iaa
from meghair.utils.imgproc import imdecode
host = "http://oss.i.brainpp.cn/"
bucket = "ai-cultivate"
key = "1percent_ImageNet.txt"
s3_client = boto3.client('s3', endpoint_url=host)
def read_img():
resp = s3_client.get_object(Bucket=bucket, Key=key)
datas = resp['Body'].read().decode('utf8')
data_list = datas.split('\n')
nori_ids = list(map(lambda x: x.split('\t')[0], data_list))[100:110]
fetcher = nori.Fetcher()
img_list = list(map(lambda x: imdecode(fetcher.get(x)), nori_ids))
return img_list
def stat(img_list):
height_list = []
width_list = []
for i, img in enumerate(img_list):
height_list.append(img.shape[0])
width_list.append(img.shape[1])
avg_height = np.mean(height_list)
max_height = max(height_list)
min_height = min(height_list)
avg_width = np.mean(width_list)
max_width = max(width_list)
min_width = min(width_list)
img_info = {
'avg_height': avg_height,
'max_height': max_height,
'min_height': min_height,
'avg_width': avg_width,
'max_width': max_width,
'min_width': min_width,
}
print("image statistic result: {}".format(img_info))
def enhance_img(img_list):
H, W = 128, 64
Gap = 16
NUM = 9
seq = iaa.Sequential([
iaa.Fliplr(0.5),
iaa.Crop(px=(10, 50)),
iaa.Affine(
scale = {"x": (0.8, 1.2), "y": (0.8, 1.2)},
translate_px = {"x": (-16, 16), "y": (-16,16)},
rotate = (-75, 75)
),
iaa.GaussianBlur(sigma=(0, 2.0)),
iaa.Resize({"height": H, "width": W})
], random_order=True)
res = np.zeros(shape=((H + Gap)* len(img_list), (W + Gap)*NUM, 3),dtype = np.uint8)
for i, img in enumerate(img_list):
img_array = np.array([img] * NUM, dtype = np.uint8)
write_img = np.zeros(shape=(H, (W + Gap)*NUM, 3), dtype=np.uint8)
images_aug = seq.augment_images(images=img_array)
for j, item in enumerate(images_aug):
write_img[:, j * (W+Gap): j * (W+Gap) + W, :] = item
res[i * (H+10): i*(H+10) + H, :, :] = write_img
cv2.imwrite('result.jpg', res)
if __name__ == '__main__':
img_list = read_img()
stat(img_list)
enhance_img(img_list)
统计结果:
{‘avg_height’: 346.9, ‘max_height’: 385, ‘min_height’: 248, ‘avg_width’: 500.0, ‘max_width’: 500, ‘min_width’: 500}
图片结果:

第二周个人作业
megstudio提交:
https://studio.brainpp.com/project/10502?name=AI培训课后作业(4_2)_miaojianwei_作业
第一周个人作业
import boto3
import nori2 as nori
from meghair.utils.imgproc import imdecode
import numpy as np
from imgaug import augmenters as iaa
import cv2
host = "http://oss.i.brainpp.cn/"
bucket = "ai-cultivate"
key = "1percent_ImageNet.txt"
s3_client = boto3.client('s3', endpoint_url=host)
def read_img():
image_res = s3_client.get_object(Bucket=bucket, Key=key)
image_data = image_res['Body'].read().decode("utf8")
images = image_data.split('\n')
nori_ids = list(map(lambda x: x.split('\t')[0], images))[-11:-5:1]
fetcher = nori.Fetcher()
imgs = list(map(lambda x: imdecode(fetcher.get(x)), nori_ids))
return imgs
def compare(imgs):
height_list = []
width_list = []
for i,img in enumerate(imgs):
height_list.append(img.shape[0])
width_list.append(img.shape[1])
avg_height = np.mean(height_list)
avg_width = np.mean(width_list)
max_height = max(height_list)
max_width = max(width_list)
min_height = min(height_list)
min_width = min(width_list)
img_info = {'avg_height':avg_height,'avg_width':avg_width,'max_height':max_height,'max_width':max_width,'min_height':min_height,'min_width':min_width}
print(img_info)
def augmenters_img(imgs):
H, W = 100, 100
NUM = 6
seq = iaa.Sequential([
iaa.Fliplr(0.5), # 图像的50%概率水平翻转
iaa.Crop(px=(0, 25)), # 四边以0 - 25像素剪裁
iaa.Affine(
scale={"x": (0.5, 1.2), "y": (0.5, 1.2)}, # 图像缩放
translate_px={"x": (-6, 16), "y": (-6, 16)}, # 像素随机平移
rotate=(-30, 60) # 旋转-30度或60度
),
iaa.GaussianBlur(sigma=(0, 2.0)), # 高斯模糊
iaa.Resize({"height": H, "width": W})
], random_order=True)
res = np.zeros(shape=((H + 10) * len(imgs), (W + 10) * NUM, 3), dtype=np.uint8)
for i, img in enumerate(imgs):
img_array = np.array([img] * NUM, dtype=np.uint8)
write_img = np.zeros(shape=(H, (W + 10) * NUM, 3), dtype=np.uint8)
images_aug = seq.augment_images(images=img_array)
for j, item in enumerate(images_aug):
write_img[:, j * (W + 10): j * (W + 10) + W, :] = item
res[i * (H + 10): i * (H + 10) + H, :, :] = write_img
cv2.imwrite("augmenters.jpg", res)
if __name__ == '__main__':
imgs = read_img()
compare(imgs)
augmenters_img(imgs)