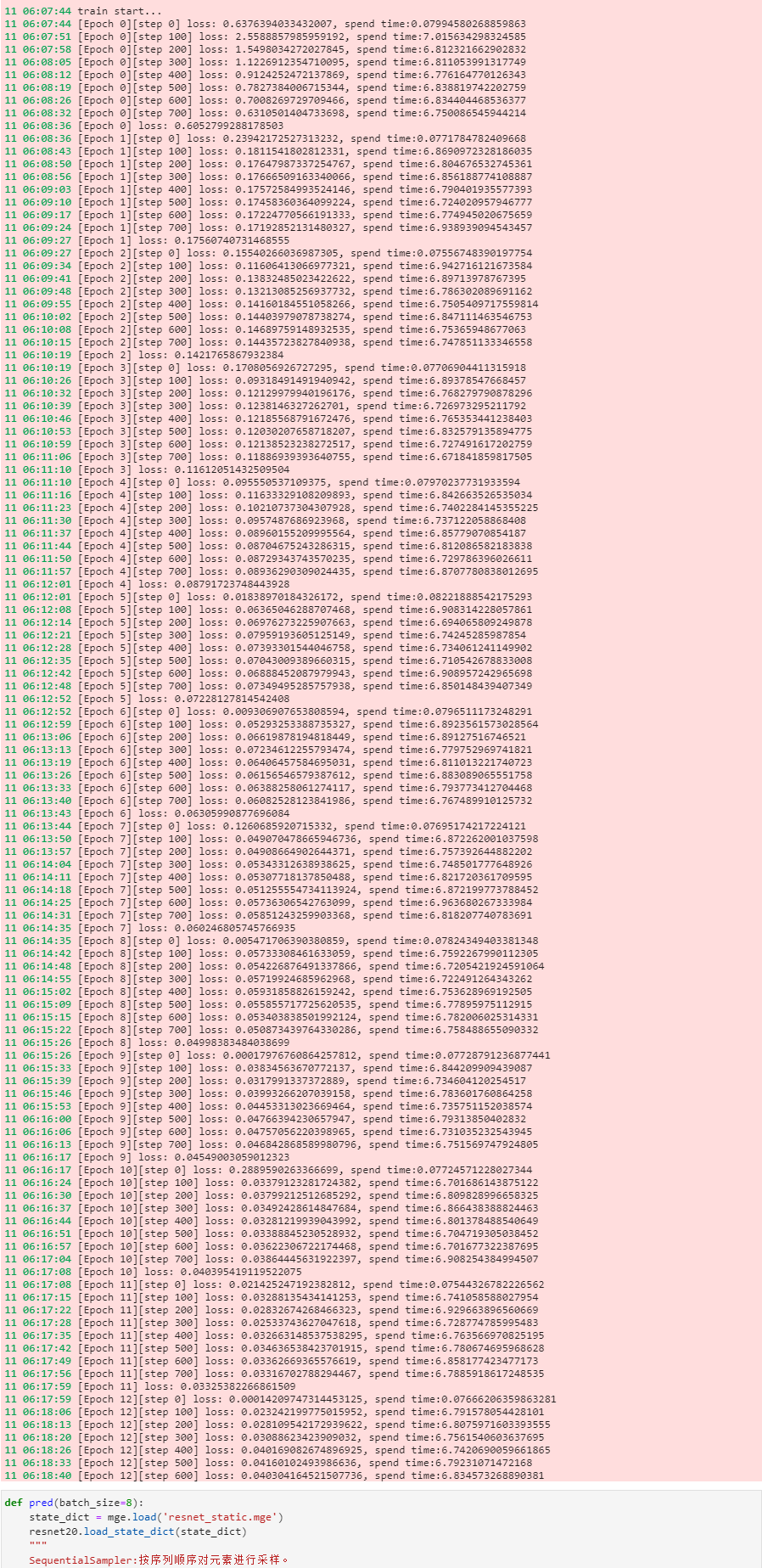
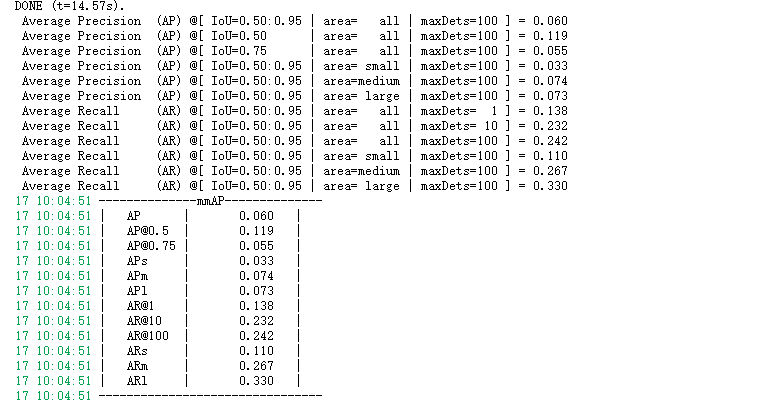
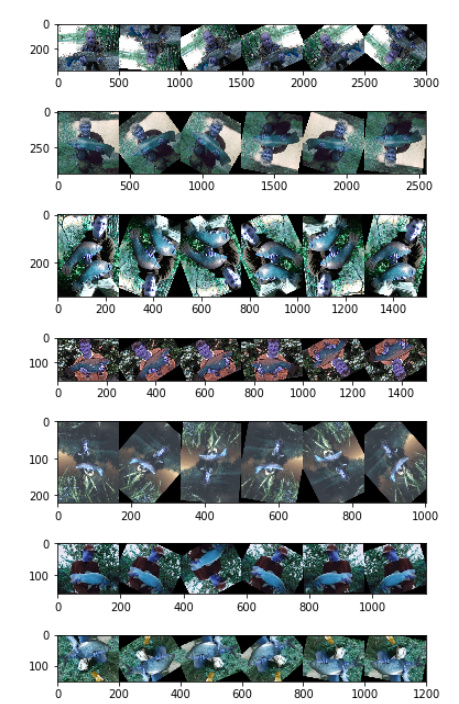
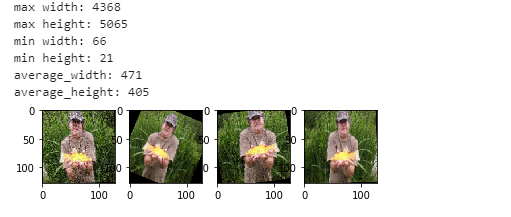
代码
import cv2
import boto3
import numpy as np
import nori2 as nori
import imgaug as ia
from imgaug import augmenters as iaa
from meghair.utils import io
from meghair.utils.imgproc import imdecode
img_list = []
enhance_num = 10
host = "http://oss.i.brainpp.cn"
fetcher = nori.Fetcher()
# Client初始化
s3_client = boto3.client('s3', endpoint_url=host)
# 获取一个 object
def get_bucket_object(bucket_name="ai-cultivate", object_key="1percent_ImageNet.txt"):
resp = s3_client.get_object(Bucket=bucket_name, Key=object_key)
return resp['Body'].read().decode("utf8")
sometimes = lambda aug: iaa.Sometimes(0.5, aug)
aug = iaa.Sequential(
[
iaa.Fliplr(0.5), # 对50%的图像进行镜像翻转
iaa.Flipud(0.2), # 对20%的图像做左右翻转
sometimes(iaa.Crop(percent=(0, 0.1))), # 对随机的一部分图像做crop操作
# 对一部分图像做仿射变换
sometimes(iaa.Affine(
scale={"x": (0.8, 1.2), "y": (0.8, 1.2)}, # 图像缩放为80%到120%之间
translate_percent={"x": (-0.2, 0.2), "y": (-0.2, 0.2)}, # 平移±20%之间
rotate=(-45, 45), # 旋转±45度之间
shear=(-16, 16), # 剪切变换±16度,(矩形变平行四边形)
order=[0, 1], # 使用最邻近差值或者双线性差值
cval=(0, 255), # 全白全黑填充
mode=ia.ALL # 定义填充图像外区域的方法
)),
],
random_order=True # 随机的顺序把这些操作用在图像上
)
def img_enhance(img):
img = cv2.resize(img, (int(img.shape[0]/4),int(img.shape[1]/4)))
h = img.shape[0]
w = img.shape[1]
img_array = np.array([img] * enhance_num, dtype=np.uint8)
write_img = np.zeros(shape=(h, (w+10) * enhance_num, 3), dtype=np.uint8)
images_aug = aug.augment_images(images=img_array)
for j, item in enumerate(images_aug):
print(item.shape)
write_img[:, j * (w + 10): j * (w + 10) + w, :] = item
cv2.imwrite("data/result.jpg", write_img)
def statistics():
data = get_bucket_object()
for i in data.split('\n'):
if not i:
continue
nori_id, id, img_name = i.split()
img = imdecode(fetcher.get(nori_id))
img_list.append(img.shape)
# # cv2.imwrite(img_name.split('/')[1], img)
img_list_h = [i[0] for i in img_list]
img_list_w = [i[1] for i in img_list]
print('------------------')
print('height \t max:{} \t min:{} \t avg:{}'.format(max(img_list_h), min(img_list_h), np.average(img_list_h)))
print('wight \t max:{} \t min:{} \t avg:{}'.format(max(img_list_w), min(img_list_w), np.average(img_list_w)))
# ------------------
# height max:5065 min:21 avg:405.4505503083288
# wight max:4368 min:46 avg:471.49918039185076
# 对一张图片进行增强,并保存
def enhance():
data = get_bucket_object()
nori_id, id, img_name = data.split('\n')[0].split()
img = imdecode(fetcher.get(nori_id))
img_enhance(img)
if __name__ == '__main__':
statistics()
enhance()