第一周课后作业内容
- 针对Imagenet数据(s3://ai-cultivate/1percent_ImageNet.txt),进行基本的数据统计(统计框/图片的平均,最大,最小宽高),数据预处理(对数据做旋转增强,randomcrop),并做可视化分析对比数据处理前后的变化
- 针对外部同学,不指定图片来源,可以使用任意来源的100张图片,进行基本的数据统计(统计框/图片的平均,最大,最小宽高),数据预处理(对数据做旋转增强,randomcrop),并做可视化分析对比数据处理前后的变化

代码
import boto3
import boto3
import cv2
import nori2 as nori
import numpy as np
from imgaug import augmenters as iaa
from meghair.utils import io
from meghair.utils.imgproc import imdecode
from refile import smart_open
s3_client = boto3.client('s3', endpoint_url="http://oss.i.brainpp.cn")
bucket = "ai-cultivate"
key="1percent_ImageNet.txt"
# 从 s3 读取文件,并将其转换成 mat 矩阵: numpy.ndarray
def read_img(bucket, key):
resp = s3_client.get_object(Bucket=bucket, Key=key)
res = resp['Body'].read().decode('utf8')
data = res.split('\n')
nori_ids = list(map(lambda x: x.split('\t')[0], data))[-20::2] # 从倒数第20个开始,步长为2,取到最后一个
fetcher = nori.Fetcher()
img_list = list(map(lambda x: imdecode(fetcher.get(x)), nori_ids)) # imdecode 将文件转成 mat 矩阵格式
print(type(img_list[0]))
return img_list
# 统计图片的大小 ,平均高度、最大高度、最小高度、平均宽度、最大宽度、最小宽度
def get_img_statistics(img_list):
img_size_list = []
for i, img in enumerate(img_list):
img_size_list.append({"img_num": "img_{}".format(i), "height": img.shape[0], "width": img.shape[1]})
height_list = [img_size['height'] for img_size in img_size_list]
width_list = [img_size['width'] for img_size in img_size_list]
# 求高度的平均值
avg_height = np.mean(height_list)
max_height = max(height_list)
min_height = min(height_list)
avg_width = np.mean(width_list)
max_width = max(width_list)
min_width = min(width_list)
img_info = {
'avg_height': avg_height,
'max_height': max_height,
'min_height': min_height,
'avg_width': avg_width,
'max_width': max_width,
'min_width': min_width,
'img_size': img_size_list
}
print("image statistic result: {}".format(img_info))
# 图片增强
def enhance_img(img_list):
H, W = 128, 128
NUM = 6 # 每张图要变换的张数
seq = iaa.Sequential([
iaa.Fliplr(0.5), # 对50%的图像进行水翻转
iaa.Crop(percent=(0, 0.05)), # 四边以 0, 0.05 的比例进行裁剪
iaa.Affine(
scale = {"x": (0.8, 1.2), "y": (0.8, 1.2)},
translate_px = {"x": (-16, 16), "y": (-16,16)},
rotate = (-45, 45)
),
iaa.GaussianBlur(sigma=(0, 2.0)),
iaa.Resize({"height": H, "width": W})
], random_order=True)
res = np.zeros(shape=((H + 10)* len(img_list), (W + 10)*NUM, 3),dtype = np.uint8)
for i, img in enumerate(img_list):
img_array = np.array([img] * NUM, dtype = np.uint8)
write_img = np.zeros(shape=(H, (W + 10)*NUM, 3), dtype=np.uint8)
images_aug = seq.augment_images(images=img_array)
for j, item in enumerate(images_aug):
write_img[:, j * (W+10): j * (W+10) + W, :] = item
res[i * (H+10): i*(H+10) + H, :, :] = write_img
# 将结果写到一张图中
cv2.imwrite('result.jpg', res)
if __name__ == '__main__':
img_list = read_img(bucket, key)
get_img_statistics(img_list)
enhance_img(img_list)
结果:
wenjuan
import re
import requests
from urllib import parse
def get_image(keyword):
url ='https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord={encode_keyword}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&word={encode_keyword}&s=&se=&ta&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn={pn}&rn=30&gsm=1e&1622791309020= ’
header = {
‘User-Agent’: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36’,
‘Referer’:‘https://image.baidu.com’
}
compile_reg = re.compile(‘thumbURL.*?.jpg’)
encode_keyword = parse.quote(keyword)
i = 1
for pn in range(1,20):
url = url.format(encode_keyword=encode_keyword,pn=pn)
url ='https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord={encode_keyword}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&word={encode_keyword}&s=&se=&ta&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&pn=' + str(pn) + '&rn=30&gsm=1e&1622791309020= '
print(url)
ret = requests.get(url,headers=header)
img_url_list = compile_reg.findall(ret.text)
img_url_list = map(lambda x: x.replace('thumbURL":"', ''), img_url_list)
for img_url in img_url_list:
img = requests.get(img_url)
with open('./data/06042/image_{}.jpg'.format(i), 'wb') as f:
f.write(img.content)
i += 1
if name == “main”:
keyword = “充气拱门”
get_image(keyword)
import boto3
import cv2
import nori2 as nori
import numpy as np
import refile
from imgaug import augmenters as iaa
from meghair.utils.imgproc import imdecode
s3_client = boto3.client('s3', endpoint_url="http://oss.i.brainpp.cn")
bucket = "ai-cultivate"
key = "1percent_ImageNet.txt"
H, W = 128, 128
NUM = 4
resp = s3_client.get_object(Bucket=bucket, Key=key)
res = resp['Body'].read().decode('utf8')
data = res.split('\n')
nori_ids = list(map(lambda x: x.split('\t')[0], data))[-10::2]
fetcher = nori.Fetcher()
img_list = list(map(lambda x: imdecode(fetcher.get(x)), nori_ids))
seq = iaa.Sequential([
iaa.Fliplr(0.6),
iaa.Crop(percent=(0, 0.05)),
iaa.Affine(
scale={"x": (0.8, 1.2), "y": (0.8, 1.2)},
translate_px={"x": (-16, 16), "y": (-16, 16)},
rotate=(-45, 45)
),
iaa.GaussianBlur(sigma=(0, 2.0)),
iaa.Resize({"height": H, "width": W})
], random_order=True)
res = np.zeros(shape=((H + 10) * len(img_list), (W + 10) * NUM, 3), dtype=np.uint8)
for i, img in enumerate(img_list):
img_array = np.array([img] * NUM, dtype=np.uint8)
write_img = np.zeros(shape=(H, (W + 10) * NUM, 3), dtype=np.uint8)
images_aug = seq.augment_images(images=img_array)
for j, item in enumerate(images_aug):
write_img[:, j * (W + 10): j * (W + 10) + W, :] = item
res[i * (H + 10): i * (H + 10) + H, :, :] = write_img
# 写入结果
cv2.imwrite('enhance_img.jpg', res)
imgs_list=[]
for i, img in enumerate(img_list):
imgs_list.append(
{
"height": img.shape[0],
"width": img.shape[1],
}
)
height_list = [img_size["height"] for img_size in imgs_list]
width_list = [img_size["width"] for img_size in imgs_list]
print("-----统计结果如下-------------")
print("高度:")
print("最大高度:", max(height_list))
print("最小高度:", min(height_list))
print("平均高度:", np.mean(height_list), "\n")
print("宽度:")
print("最大宽度:", max(width_list))
print("最小宽度:", min(width_list))
print("平均宽度:", np.mean(width_list))
代码:
import cv2
import imgaug as ia
import imgaug.augmenters as iaa
import nori2 as nori
import numpy as np
import boto3
import boto3
from meghair.utils import io
from meghair.utils.imgproc import imdecode
bucket = "ai-cultivate"
key="1percent_ImageNet.txt"
host = "http://oss.i.brainpp.cn"
# Client初始化
s3_client = boto3.client('s3', endpoint_url=host)
# 读取文件
def read_img(bucket, key):
resp = s3_client.get_object(Bucket=bucket, Key=key)
# print(resp['Body'].read())
data = resp['Body'].read().decode('utf8').split('\n')
nori_ids = list(map(lambda x: x.split('\t')[0], data))[-10::2]
fetcher = nori.Fetcher()
img_list = list(map(lambda x: imdecode(fetcher.get(x)), nori_ids))
return img_list
# 统计图片平均高度、最大高度、最小高度、平均宽度、最大宽度、最小宽度
def get_img_info(img_list):
img_info_list = []
for i, img in enumerate(img_list):
img_info_list.append(
{
"num": "img_num_{}".format(i),
"height": img.shape[0],
"width": img.shape[1],
}
)
height_list = [img_size["height"] for img_size in img_info_list]
width_list = [img_size["width"] for img_size in img_info_list]
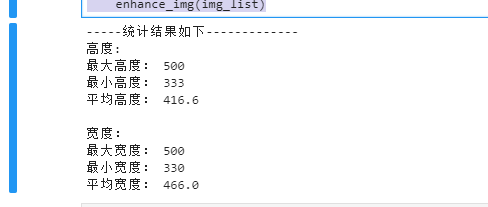
print("-----统计结果如下-------------")
print("高度:")
print("最大高度:", max(height_list))
print("最小高度:", min(height_list))
print("平均高度:", np.mean(height_list), "\n")
print("宽度:")
print("最大宽度:", max(width_list))
print("最小宽度:", min(width_list))
print("平均宽度:", np.mean(width_list))
# # 图片增强
def enhance_img(img_list):
seq = iaa.Sequential([
iaa.Sometimes(0.5,iaa.Crop(px=(0, 16))),#裁剪
iaa.Fliplr(0.4),#镜像翻转
iaa.Flipud(0.4),#上下翻转
iaa.Affine(
scale={"x": (0.8, 1.2), "y": (0.8, 1.2)},#缩放
rotate=(-90, 90)#旋转
),
iaa.GaussianBlur(sigma=(0, 2.0)),
iaa.Resize({"height": H, "width": W})
], random_order=True)
res = np.zeros(shape=((H + 10) * len(img_list), (W + 10) * NUM, 3), dtype=np.uint8)
for i, img in enumerate(img_list):
img_array = np.array([img] * NUM, dtype=np.uint8)
write_img = np.zeros(shape=(H, (W + 10) * NUM, 3), dtype=np.uint8)
images_aug = seq.augment_images(images=img_array)
for j, item in enumerate(images_aug):
write_img[:, j * (W + 10): j * (W + 10) + W, :] = item
res[i * (H + 10): i * (H + 10) + H, :, :] = write_img
# 写入结果
cv2.imwrite('enhance_img.jpg', res)
if __name__ == '__main__':
img_list = read_img(bucket, key)
get_img_info(img_list)
enhance_img(img_list)
结果:
统计结果
import boto3
import cv2
import nori2 as nori
import numpy as np
from imgaug import augmenters as iaa
from meghair.utils import io
from meghair.utils.imgproc import imdecode
from refile import smart_open
s3_client = boto3.client('s3', endpoint_url="http://oss.i.brainpp.cn")
bucket = "ai-cultivate"
key="1percent_ImageNet.txt"
# 从 s3 读取文件,并将其转换成 mat 矩阵: numpy.ndarray
def read_img(bucket, key):
resp = s3_client.get_object(Bucket=bucket, Key=key)
res = resp['Body'].read().decode('utf8')
data = res.split('\n')
nori_ids = list(map(lambda x: x.split('\t')[0], data))[:30:2]
fetcher = nori.Fetcher()
img_list = list(map(lambda x: imdecode(fetcher.get(x)), nori_ids)) # imdecode 将文件转成 mat 矩阵格式
# print(type(img_list[0]))
return img_list
# 统计图片的大小 ,平均高度、最大高度、最小高度、平均宽度、最大宽度、最小宽度
def img_statistics(img_list):
img_size_list = []
for i, img in enumerate(img_list):
img_size_list.append({"img_num": "img_{}".format(i), "height": img.shape[0], "width": img.shape[1]})
height_list = [img_size['height'] for img_size in img_size_list]
width_list = [img_size['width'] for img_size in img_size_list]
# 求高度的平均值
avg_height = np.mean(height_list)
max_height = max(height_list)
min_height = min(height_list)
avg_width = np.mean(width_list)
max_width = max(width_list)
min_width = min(width_list)
img_info = {
'avg_height': avg_height,
'max_height': max_height,
'min_height': min_height,
'avg_width': avg_width,
'max_width': max_width,
'min_width': min_width
}
print("image statistic result: {}".format(img_info))
# 图片增强
def enhance_img(img_list):
H, W = 128, 128
NUM = 6
sometimes = lambda aug: iaa.Sometimes(0.5, aug)
seq = iaa.Sequential([
iaa.Fliplr(0.5), # 对50%的图像进行水平翻转
iaa.Flipud(0.3), #对30%的图像进行上下翻转
sometimes(iaa.Affine(
scale = {"x": (0.8, 1.2), "y": (0.8, 1.2)},
translate_percent = {"x": (-0.2, 0.2), "y": (-0.2,0.2)},
rotate = (-30, 30)
)),
sometimes(iaa.GaussianBlur((0,2.0))),
iaa.Resize({"height": H, "width": W})
], random_order=True)
res = np.zeros(shape=((H + 10)* len(img_list), (W + 10)*NUM, 3),dtype = np.uint8)
for i, img in enumerate(img_list):
img_array = np.array([img] * NUM, dtype = np.uint8)
write_img = np.zeros(shape=(H, (W + 10)*NUM, 3), dtype=np.uint8)
images_aug = seq.augment_images(images=img_array)
for j, item in enumerate(images_aug):
write_img[:, j * (W+10): j * (W+10) + W, :] = item
res[i * (H+10): i*(H+10) + H, :, :] = write_img
# 将结果写到一张图中
cv2.imwrite('test.jpg', res)
if __name__ == '__main__':
img_list = read_img(bucket, key)
img_statistics(img_list)
enhance_img(img_list)
图片输出
代码:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import argparse
import cv2
import boto3
import imgaug as ia
import imgaug.augmenters as iaa
from meghair.utils.imgproc import imdecode
import nori2 as nori
import numpy as np
import random
def read_images(path):
# host = 'http://oss.i.brainpp.cn'
# s3_client = boto3.client('s3', endpoint_url=host)
# resp = s3_client.get_object(Bucket='ai-cultivate', Key='1percent_ImageNet.txt')
# text = resp['Body'].read().decode('utf8')
text = nori.utils.smart_open(path).read()
data = text.split('\n')
nori_ids = [data[i].split('\t')[0].strip() for i in range(len(data) - 1)]
f = nori.Fetcher()
# hwc
images = [imdecode(f.get(nori_id)) for nori_id in nori_ids]
return images
def get_statistics(images):
h = np.array([image.shape[0] for image in images])
w = np.array([image.shape[1] for image in images])
avg_h = h.mean()
avg_w = w.mean()
max_h = h.max()
max_w = w.max()
min_h = h.min()
min_w = w.min()
info = {
'img_num': len(images),
'avg_h': avg_h,
'avg_w': avg_w,
'max_h': max_h,
'max_w': max_w,
'min_h': min_h,
'min_w': min_w
}
return info
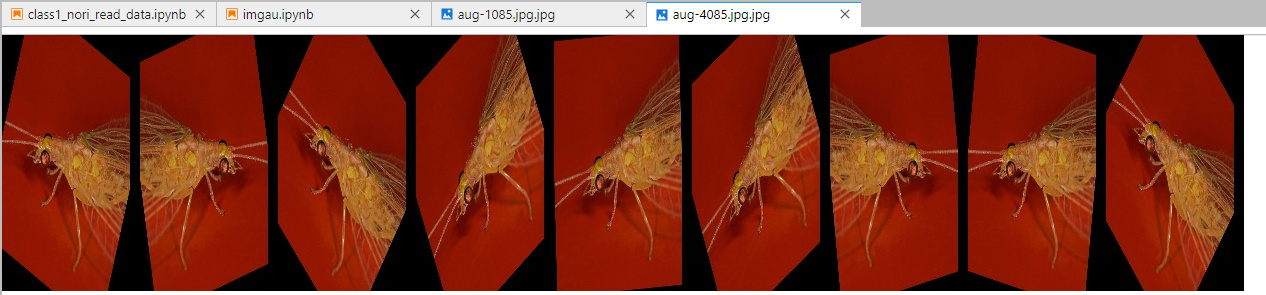
def augment(images, out_path):
H, W = 256, 256
NUM = 6
TIMES = 8
ia.seed(1)
seq = iaa.Sequential([
iaa.Sometimes(0.5, iaa.Fliplr(0.5)),
iaa.Sometimes(0.5, iaa.Crop(px=(0, 20))),
iaa.Sometimes(0.5, iaa.Affine(rotate=(-45, 45))),
iaa.Resize({
'height': 256,
'width': 256
})
],
random_order=True)
write_img = np.zeros(
shape=((H + 10) * TIMES, (W + 10) * NUM, 3), dtype=np.uint8)
i = 0
for cnt in range(TIMES):
idx = random.randint(0, len(images))
image = images[idx]
img_array = np.array([image] * NUM, dtype=np.uint8)
images_aug = seq.augment_images(images=img_array)
for j, img in enumerate(images_aug):
write_img[i * (H + 10):i * (H + 10) +
H, j * (W + 10):j * (W + 10) + W, :] = img
i += 1
cv2.imwrite(out_path, write_img)
def main():
parser = argparse.ArgumentParser(
description='Image preprocess.',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument(
'--input',
required=False,
default='s3://ai-cultivate/1percent_ImageNet.txt',
help='data path')
parser.add_argument(
'--output',
required=False,
default='processed_image.jpg',
help='result path')
args = parser.parse_args()
images = read_images(args.input)
info = get_statistics(images)
print(info)
augment(images, args.output)
if __name__ == '__main__':
main()
运行结果:
第一周作业:
import boto3
import cv2
import nori2 as nori
import numpy as np
import imgaug.augmenters as iaa
from meghair.utils.imgproc import imdecode
from urllib.parse import urlparse
import matplotlib.pyplot as plt
host = 'http://oss.i.brainpp.cn'
oss_url = 's3://ai-cultivate/1percent_ImageNet.txt'
H,W = 256, 128
NUM=9
# Client初始化
s3_client = boto3.client('s3', endpoint_url=host)
fetcher = nori.Fetcher()
# 读取oss中的数据
def read_oss_img():
url = urlparse(oss_url)
obj = s3_client.get_object(Bucket=url.netloc, Key=url.path.lstrip("/"))
return obj['Body'].read().decode("UTF-8").split('\n')
# 图片统计
def img_statics(imgUrlList):
max_width = -1
max_height = -1
min_width = 0xFFFFFFFF
min_height = 0xFFFFFFFF
sum_width = -1
sum_height = -1
imgUrlList = [line.split() for line in imgUrlList if len(line) > 0]
for i, line in enumerate(imgUrlList):
if i % 1000 == 0:
print(f"{i}/{len(line)}")
img = nori_get_image(line[0])
sum_height += img.shape[0]
sum_width += img.shape[1]
if max_height < img.shape[0]:
max_height = img.shape[0]
if max_width < img.shape[1]:
max_width = img.shape[1]
if min_height > img.shape[0]:
min_height = img.shape[0]
if min_width > img.shape[1]:
min_width = img.shape[1]
# 图片写到本地
jpg = imdecode(fetcher.get(line[0]))[..., :3]
img_name = "%s.jpg" % i
cv2.imwrite(img_name, jpg)
# 随机选择图进行增强
if i % np.random.random_integers(10000):
img_aug(img_name)
print('max_width is:{}, max_height is:{}', max_width, max_height)
print('min_width is:{}, min_height is:{}', min_width, min_height)
print('avg_width is:{}, avg_height is:{}', sum_width/len(imgUrlList), sum_height/len(imgUrlList))
# 图片增强
def img_aug(img_name):
img = cv2.imread(img_name)
images = np.array(
[img] * NUM,
dtype=np.uint8
)
seq = iaa.Sequential([
iaa.Fliplr(0.5),
iaa.Crop(px=(0, 16)),
iaa.Resize({"height": H, "width": W})
], random_order=True)
images_aug = seq(images=images)
write_img = np.zeros((H, (W+10)*NUM, 3), dtype=np.uint8)
for i, img in enumerate(images_aug):
write_img[:, i*(W+10): i*(W+10)+W, :] = img
file_name = 'img_aug' + img_name
cv2.imwrite(file_name, write_img)
def nori_get_image(nori_id):
buf = fetcher.get(nori_id)
img = cv2.imdecode(np.frombuffer(buf, dtype=np.uint8) , cv2.IMREAD_COLOR)
return cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
def main():
img_url_list = read_oss_img()
img_statics(img_url_list)
if __name__ == '__main__':
main()
import nori2 as nori
import cv2
import refile
import boto3
import numpy as np
from meghair.utils import io
from meghair.utils.imgproc import imdecode
from imgaug import augmenters as iaa
fetcher = nori.Fetcher()
s3_client = boto3.client('s3', endpoint_url="http://oss.i.brainpp.cn")
bucket = "ai-cultivate"
key = "1percent_ImageNet.txt"
H, W = 128, 128
NUM = 6
resp = s3_client.get_object(Bucket=bucket, Key=key)
res = resp['Body'].read().decode('utf8')
widths = 0
heights = 0
maxw = 0
maxh = 0
count = 0
data = res.split('\n')
nori_ids = list(map(lambda x: x.split('\t')[0], data))[-10::2]
fetcher = nori.Fetcher()
img_list = list(map(lambda x: imdecode(fetcher.get(x)), nori_ids))
for img in img_list :
widths += img.shape[0]
heights += img.shape[1]
if maxw < img.shape[0]:
maxw = img.shape[0]
if maxh < img.shape[1]:
maxh = img.shape[1]
count = count + 1
print("average width={}, average height={}".format(widths/count, heights/count))
print("max width={} height={}".format(maxw, maxh))
res = np.zeros(shape=((H + 10) * len(img_list), (W + 10) * NUM, 3), dtype=np.uint8)
seq = iaa.Sequential([
iaa.Fliplr(0.6),
iaa.Flipud(0.5),
iaa.Crop(percent=(0, 0.05)),
iaa.Sometimes(0.5, iaa.GaussianBlur(sigma=(0, 2.0))),
iaa.Resize({"height": H, "width": W})
])
for i, img2 in enumerate(img_list):
img_array = np.array([img2] * NUM, dtype=np.uint8)
write_img = np.zeros(shape=(H, (W + 10) * NUM, 3), dtype=np.uint8)
images_aug = seq.augment_images(images=img_array)
for j, item in enumerate(images_aug):
write_img[:, j * (W + 10): j * (W + 10) + W, :] = item
res[i * (H + 10): i * (H + 10) + H, :, :] = write_img
# 写入结果
cv2.imwrite('enhance.jpg', res)
第三周课后作业:
代码:
import os
import time
import json
import math
def get_images(query, n, path):
# 不知道为啥len=500也只有100张
iters = math.ceil(n / 100)
left = n
for it in range(iters):
start = it * 100
num = min(left, 100)
req = 'https://pic.sogou.com/napi/pc/searchList?mode=2&cwidth=1440&cheight=900&dm=4&query=' + query + '&start=' + str(
start) + '&xml_len=' + str(num)
imgs = requests.get(req)
jd = json.loads(imgs.text)
jd = jd['data']['items']
img_urls = [j['oriPicUrl'] for j in jd]
# img_urls = [j['thumbUrl'] for j in jd]
print("len:", len(img_urls))
for i in range(len(img_urls)):
try:
img_url = img_urls[i]
save_path = path + str(start + i) + '.jpg'
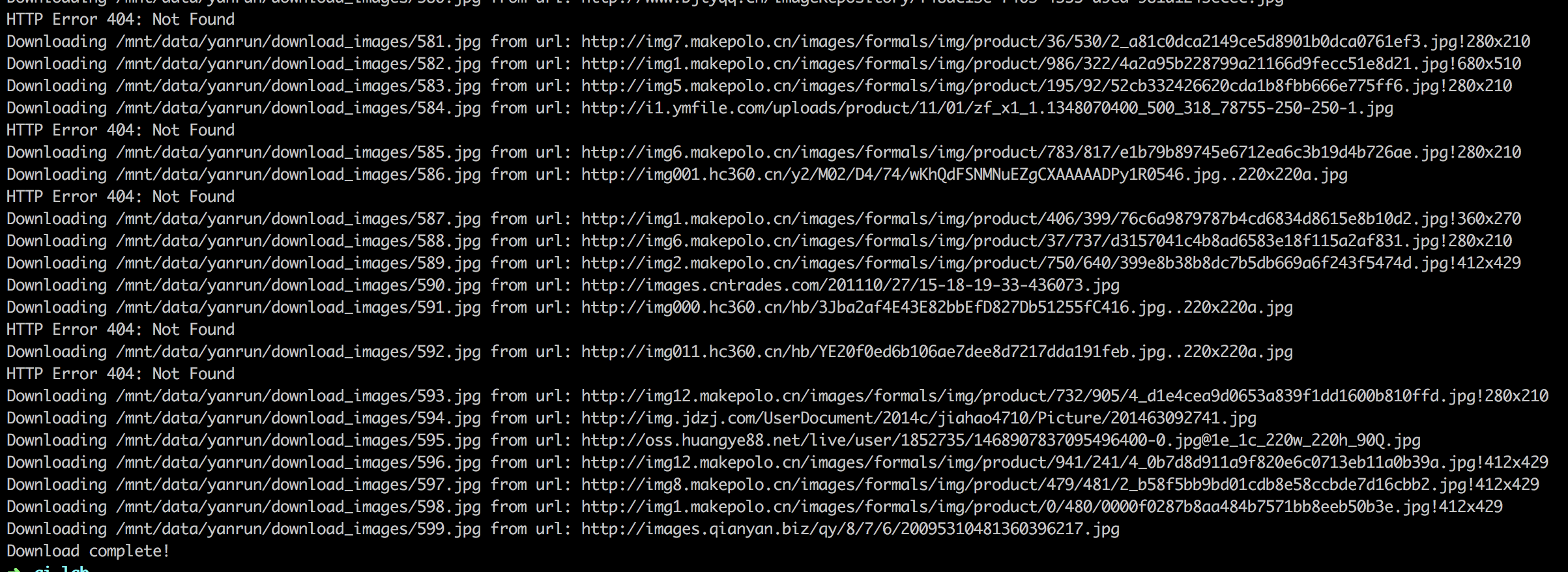
print('Downloading {} from url: {}'.format(save_path, img_url))
urllib.request.urlretrieve(img_url, save_path)
except Exception as e:
print(e)
left -= num
print('Download complete!')
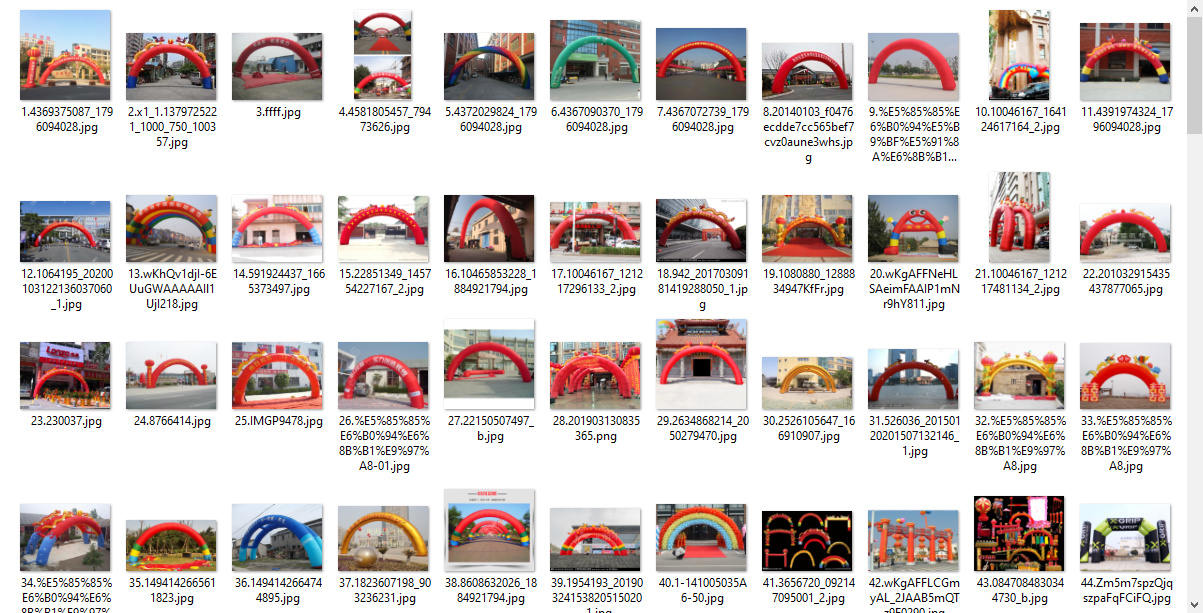
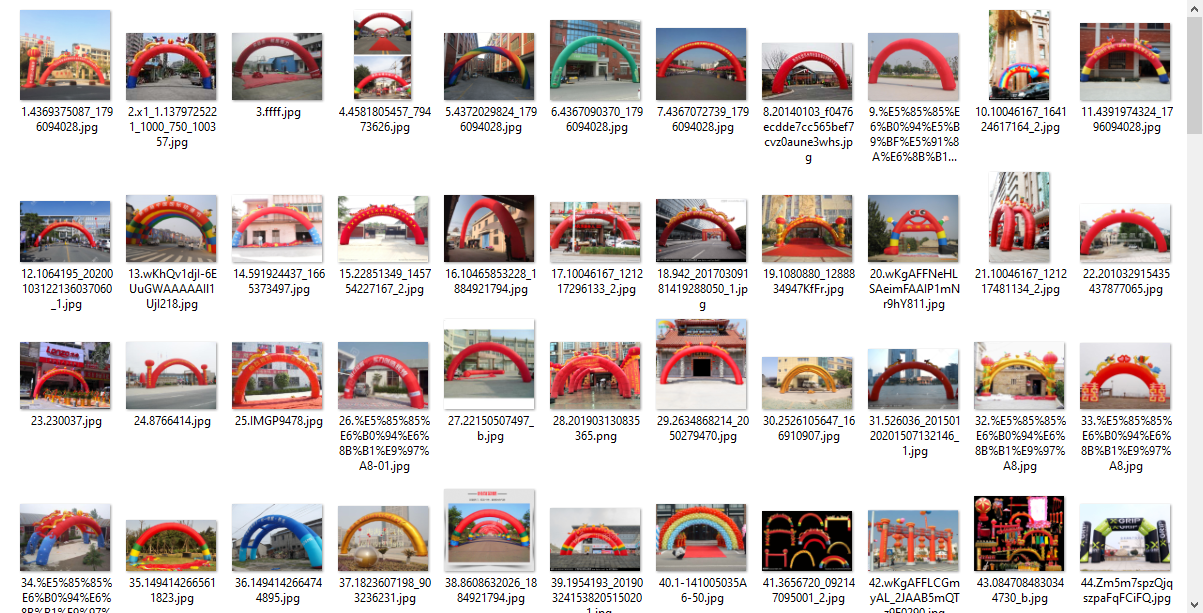
def crawler():
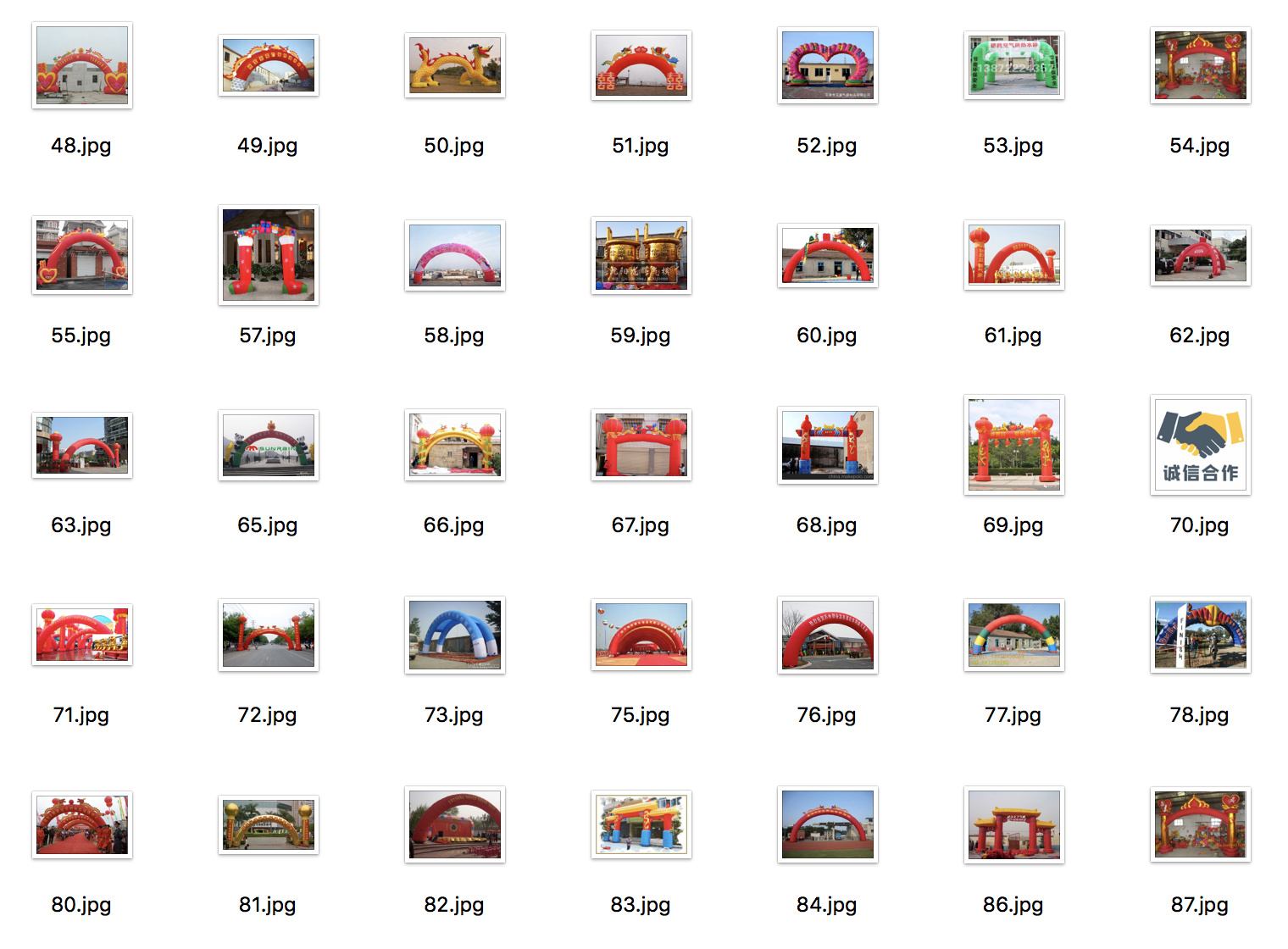
get_images('充气拱门', 600, '/mnt/data/yanrun/download_images/')
def main():
crawler()
if __name__ == '__main__':
main()
运行结果:
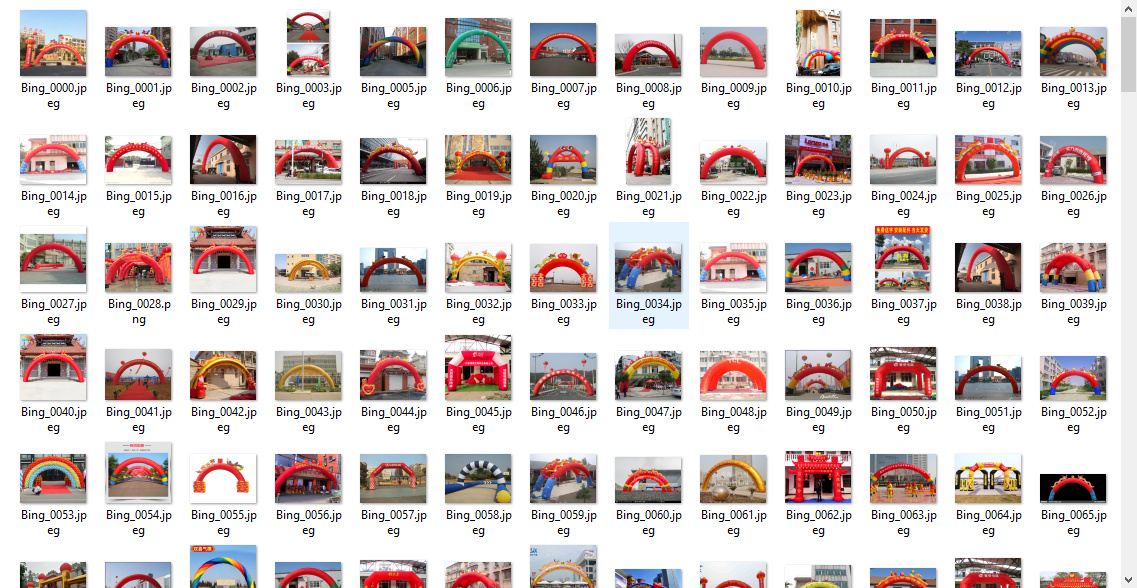
爬取微软bing图片数据
import os
import urllib.parse
import urllib.request
from bs4 import BeautifulSoup
import re
import time
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 UBrowser/6.1.2107.204 Safari/537.36'
}
url = "https://cn.bing.com/images/async?q={0}&first={1}&count={2}&scenario=ImageBasicHover&datsrc=N_I&layout=ColumnBased&mmasync=1&dgState=c*9_y*2226s2180s2072s2043s2292s2295s2079s2203s2094_i*71_w*198&IG=0D6AD6CBAF43430EA716510A4754C951&SFX={3}&iid=images.5599"
# 需要爬取的图片关键词
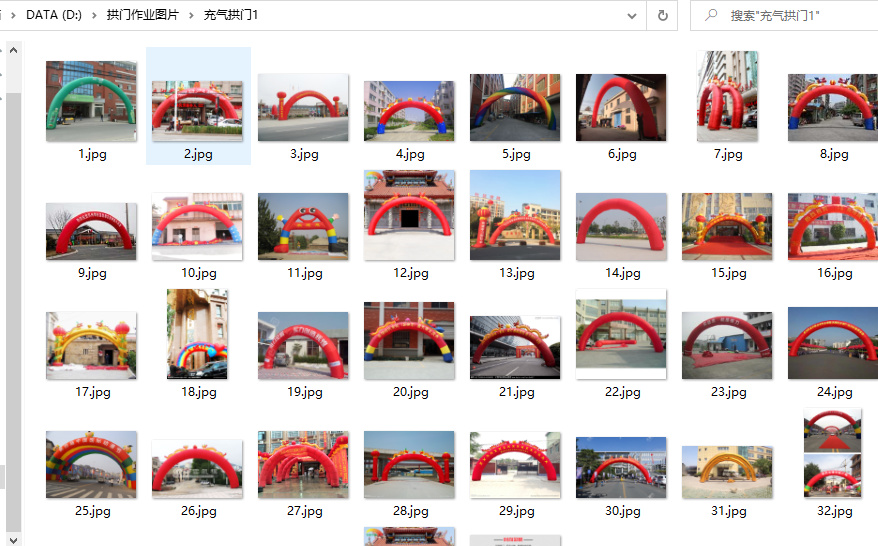
name = "充气拱门"
# 本地存储路径
path = "D:\\" + name
'''获取缩略图列表页'''
def getStartHtml(url, key, first, loadNum, sfx):
page = urllib.request.Request(url.format(key, first, loadNum, sfx), headers=header)
html = urllib.request.urlopen(page)
return html
'''从缩略图列表页中找到原图的url,并返回这一页的图片数量'''
def findImgUrlFromHtml(html, rule, url, key, first, loadNum, sfx, count):
soup = BeautifulSoup(html, "lxml")
link_list = soup.find_all("a", class_="iusc")
url = []
for link in link_list:
result = re.search(rule, str(link))
# 将字符串"amp;"删除
url = result.group(0)
# 组装完整url
url = url[8:len(url)]
# 打开高清图片网址
getImage(url, count)
count += 1
# 完成一页,继续加载下一页
return count
'''从原图url中将原图保存到本地'''
def getImage(url, count):
try:
time.sleep(0.4)
urllib.request.urlretrieve(url, path + '\\' + str(count + 1) + '.jpg')
except Exception:
time.sleep(1)
print("产生了一点点错误,跳过...")
else:
print("图片+1,成功保存 " + str(count + 1) + " 张图")
def main():
key = urllib.parse.quote(name)
first = 1500
loadNum = 35
sfx = 1
count = 0
# 正则表达式
rule = re.compile(r"\"murl\"\:\"http\S[^\"]+")
# 图片保存路径
if not os.path.exists(path):
os.makedirs(path)
# 抓500张好了
while count < 500:
html = getStartHtml(url, key, first, loadNum, sfx)
count += findImgUrlFromHtml(html, rule, url, key, first, loadNum, sfx, count)
first = count + 1
sfx += 1
if __name__ == '__main__':
main()
爬取百度数据:
# coding:utf-8
import os
import re
import urllib
import shutil
import requests
import itertools
# ------------------------ Hyperparameter ------------------------
main_folder = '/home/wangcong/test' # 存放图片的主目录
main_dir = '/' # 在主目录下设置子目录
"""
1. 如有多个关键字,需用空格进行分隔。
2. 每个关键字会单独存一个文件夹。
"""
keyword_lst = ['充气拱门图片']
# 设定保存后的图片格式
save_type = '.jpg'
# 每个关键字需要爬取的图片数量
max_num = 500
# ------------------------ URL decoding ------------------------
str_table = {
'_z2C$q': ':',
'_z&e3B': '.',
'AzdH3F': '/'
}
char_table = {
'w': 'a',
'k': 'b',
'v': 'c',
'1': 'd',
'j': 'e',
'u': 'f',
'2': 'g',
'i': 'h',
't': 'i',
'3': 'j',
'h': 'k',
's': 'l',
'4': 'm',
'g': 'n',
'5': 'o',
'r': 'p',
'q': 'q',
'6': 'r',
'f': 's',
'p': 't',
'7': 'u',
'e': 'v',
'o': 'w',
'8': '1',
'd': '2',
'n': '3',
'9': '4',
'c': '5',
'm': '6',
'0': '7',
'b': '8',
'l': '9',
'a': '0'
}
char_table = {ord(key): ord(value) for key, value in char_table.items()}
headers = {"User-Agent" : "User-Agent:Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0;"}
# ------------------------ Encoding ------------------------
def decode(url):
for key, value in str_table.items():
url = url.replace(key, value)
return url.translate(char_table)
# ------------------------ Page scroll down ------------------------
def buildUrls(keyword):
word = urllib.parse.quote(keyword)
url = r"http://pic.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&fp=result&queryWord={word}&cl=2&lm=-1&ie=utf-8&oe=utf-8&st=-1&ic=0&word={word}&face=0&istype=2nc=1&pn={pn}&rn=60"
urls = (url.format(word=word, pn=x) for x in itertools.count(start=0, step=60))
return urls
re_url = re.compile(r'"objURL":"(.*?)"')
# ------------------------ Get imgURL ------------------------
def resolveImgUrl(html):
imgUrls = [decode(x) for x in re_url.findall(html)]
return imgUrls
# ------------------------ Download imgs ------------------------
def downImgs(imgUrl, dirpath, imgName):
filename = os.path.join(dirpath, imgName)
try:
res = requests.get(imgUrl, timeout=15)
if str(res.status_code)[0] == '4':
print(str(res.status_code), ":", imgUrl)
return False
except Exception as e:
print(e)
return False
with open(filename + save_type, 'wb') as f:
f.write(res.content)
# ------------------------ Check save dir ------------------------
def mkDir(dst_dir):
try:
shutil.rmtree(dst_dir)
except:
pass
os.makedirs(dst_dir)
# ------------------------ Pull Img ------------------------
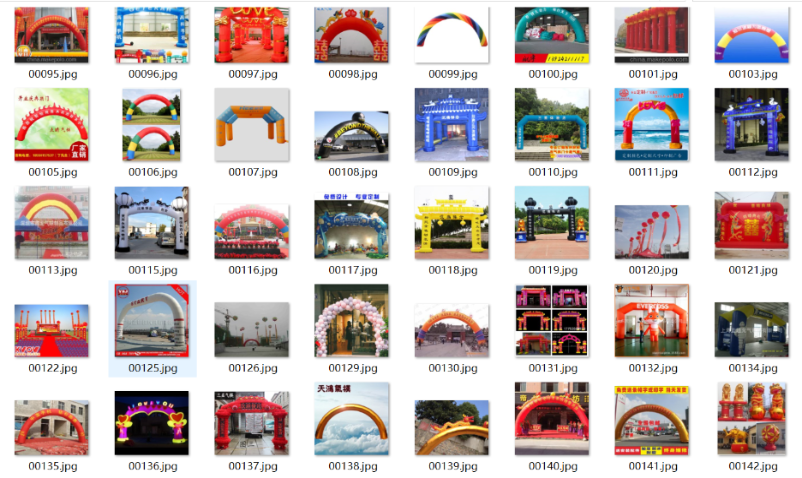
def pull_img(cur_keyword, save_dir):
print('\n\n', '= = ' * 10, ' keyword Spider 「{}」'.format(cur_keyword), ' = =' * 10, '\n\n')
mkDir(save_dir)
urls = buildUrls(cur_keyword)
idx = 0
for url in urls:
html = requests.get(url, timeout=10,headers=headers).content.decode('utf-8')
imgUrls = resolveImgUrl(html)
# Ending if no img
if len(imgUrls) == 0:
break
for url in imgUrls:
downImgs(url, save_dir, '{:>05d}'.format(idx + 1))
print(' {:>05d}'.format(idx + 1))
idx += 1
if idx >= max_num:
break
if idx >= max_num:
break
print('\n\n', '= = ' * 10, ' Download ', idx, ' pic ', ' = =' * 10, '\n\n')
if __name__ == '__main__':
for cur_keyword in keyword_lst:
save_dir = main_folder + main_dir + cur_keyword
pull_img(cur_keyword, save_dir)
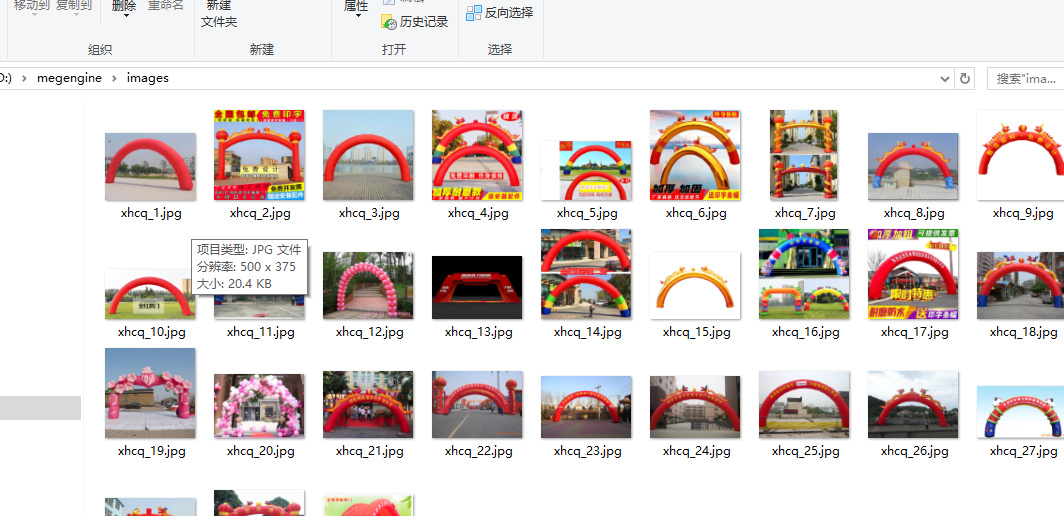
第三周作业_爬取拱门图片_梅陈:
import json
import time
import requests
from urllib.parse import quote
headers = {
'Accept':
'text/plain, */*; q=0.01',
'Accept-Language':
'zh-CN,zh;q=0.9',
'Connection':
'keep-alive',
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',
}
def search(keyword, num):
imageurl_set = []
page = num // 30
keyword = quote(keyword.encode('gbk'))
for pn in range(0, page + 1):
get_imageurl = "http://image.baidu.com/search/acjson?tn=resultjson_com&logid=6764420735902983598&ipn=rj&ct=201326592&is=&fp=result&queryWord={}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&word={}&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&fr=&expermode=&force=&pn={}&rn=30&gsm=3c&{}=".format(
keyword, keyword, pn * 30,
time.time() * 1000)
response = requests.get(get_imageurl, headers=headers, timeout=20)
try:
content = json.loads(response.text)
data = content.get('data')
for each in data[:-1]:
objURL = each.get('hoverURL')
if not objURL:
continue
imageurl_set.append(objURL)
print(objURL)
except Exception as e:
print(e)
return imageurl_set
if __name__ == "__main__":
ls = search("拱门", 20)
num = 1
for i in ls:
print(i)
filename = "D:\\megengine\\images\\xhcq_" + str(num) + ".jpg"
r = requests.get(i)
with open(filename, 'wb') as f:
f.write(r.content)
num += 1
import argparse
import codecs
import datetime
import html
import http.client
import json
import os
import random
import re
import ssl
import sys
import time # Importing the time library to check the time of code execution
import urllib.request
from http.client import IncompleteRead, BadStatusLine
from urllib.parse import quote
from urllib.request import Request, urlopen
from urllib.request import URLError, HTTPError
from tqdm import tqdm
http.client._MAXHEADERS = 1000
args_list = ["keywords", "keywords_from_file", "prefix_keywords", "suffix_keywords",
"limit", "format", "color", "color_type", "usage_rights", "size",
"exact_size", "aspect_ratio", "type", "time", "time_range", "delay", "url", "single_image",
"output_directory", "image_directory", "proxy", "similar_images", "specific_site",
"print_urls", "print_size", "print_paths", "metadata", "extract_metadata", "socket_timeout",
"language", "prefix", "chromedriver", "related_images", "safe_search",
"no_numbering", "offset", "download", "save_source", "silent_mode", "ignore_urls"]
class googleimagesdownload:
def __init__(self):
pass
# Downloading entire Web Document (Raw Page Content)
def download_page(self, url):
try:
headers = {}
headers[
'User-Agent'] = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36"
req = urllib.request.Request(url, headers=headers)
resp = urllib.request.urlopen(req)
respData = str(resp.read())
return respData
except Exception as e:
print("Could not open URL. Please check your internet connection and/or ssl settings \n"
"If you are using proxy, make sure your proxy settings is configured correctly")
sys.exit()
# Download Page for more than 100 images
def download_extended_page(self, url, chromedriver):
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
options = webdriver.ChromeOptions()
options.add_argument('--no-sandbox')
options.add_argument("--headless")
try:
browser = webdriver.Chrome(chromedriver, options=options)
except Exception as e:
print("chromedriver not found (use the '--chromedriver' argument to specify the path to the executable)"
"or google chrome browser is not installed on your machine (exception: %s)" % e)
sys.exit()
browser.set_window_size(1920, 3840) # 4k
# Open the link
browser.get(url)
time.sleep(0.5)
element = browser.find_element_by_tag_name("body")
pbar = tqdm(enumerate(range(30)), desc='Downloading HTML...', total=30) # progress bar
for _ in pbar:
try: # click 'see more' button if found
# browser.find_element_by_id("smb").click() # google images 'see more' button
browser.find_element_by_class_name('btn_seemore').click() # bing images 'see more' button
except:
pass
pbar.desc = 'Downloading HTML... %d elements' % len(browser.page_source) # page source
element.send_keys(Keys.PAGE_DOWN)
time.sleep(random.random() * 0.2 + 0.1) # bot id protection
source = browser.page_source # page source
browser.close() # close browser
return source
# Correcting the escape characters for python2
def replace_with_byte(self, match):
return chr(int(match.group(0)[1:], 8))
def repair(self, brokenjson):
invalid_escape = re.compile(r'\\[0-7]{1,3}') # up to 3 digits for byte values up to FF
return invalid_escape.sub(self.replace_with_byte, brokenjson)
# Finding 'Next Image' from the given raw page
def get_next_tab(self, s):
start_line = s.find('class="dtviD"')
if start_line == -1: # If no links are found then give an error!
end_quote = 0
link = "no_tabs"
return link, '', end_quote
else:
start_line = s.find('class="dtviD"')
start_content = s.find('href="', start_line + 1)
end_content = s.find('">', start_content + 1)
url_item = "https://www.google.com" + str(s[start_content + 6:end_content])
url_item = url_item.replace('&', '&')
start_line_2 = s.find('class="dtviD"')
s = s.replace('&', '&')
start_content_2 = s.find(':', start_line_2 + 1)
end_content_2 = s.find('&usg=', start_content_2 + 1)
url_item_name = str(s[start_content_2 + 1:end_content_2])
chars = url_item_name.find(',g_1:')
chars_end = url_item_name.find(":", chars + 6)
if chars_end == -1:
updated_item_name = (url_item_name[chars + 5:]).replace("+", " ")
else:
updated_item_name = (url_item_name[chars + 5:chars_end]).replace("+", " ")
return url_item, updated_item_name, end_content
# Getting all links with the help of '_images_get_next_image'
def get_all_tabs(self, page):
tabs = {}
while True:
item, item_name, end_content = self.get_next_tab(page)
if item == "no_tabs":
break
else:
if len(item_name) > 100 or item_name == "background-color":
break
else:
tabs[item_name] = item # Append all the links in the list named 'Links'
time.sleep(0.1) # Timer could be used to slow down the request for image downloads
page = page[end_content:]
return tabs
# Format the object in readable format
def format_object(self, object):
if '?' in object['murl']:
object['murl'] = object['murl'].split('?')[0]
formatted_object = {}
formatted_object['image_format'] = object['murl'].split('.')[-1]
formatted_object['image_height'] = False
formatted_object['image_width'] = False
formatted_object['image_link'] = object['murl'].replace(" ", "+")
formatted_object['image_description'] = object['desc']
formatted_object['image_host'] = object['purl']
formatted_object['image_source'] = object['purl']
return formatted_object
# function to download single image
def single_image(self, image_url):
main_directory = "images"
extensions = ('.bmp', '.jpg', '.jpeg', '.png', '.tif', '.tiff', '.dng')
url = image_url
try:
os.makedirs(main_directory)
except OSError as e:
if e.errno != 17:
raise
pass
req = Request(url, headers={
"User-Agent": "Mozilla/5.0 (X11; Linux i686) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1312.27 Safari/537.17"})
response = urlopen(req, None, 10)
data = response.read()
response.close()
image_name = str(url[(url.rfind('/')) + 1:])
if '?' in image_name:
image_name = image_name[:image_name.find('?')]
# if ".jpg" in image_name or ".gif" in image_name or ".png" in image_name or ".bmp" in image_name or ".svg" in image_name or ".webp" in image_name or ".ico" in image_name:
if any(map(lambda extension: extension in image_name, extensions)):
file_name = main_directory + "/" + image_name
else:
file_name = main_directory + "/" + image_name + ".jpg"
image_name = image_name + ".jpg"
try:
output_file = open(file_name, 'wb')
output_file.write(data)
output_file.close()
except IOError as e:
raise e
except OSError as e:
raise e
print("completed ====> " + image_name.encode('raw_unicode_escape').decode('utf-8'))
return
def similar_images(self, similar_images):
try:
searchUrl = 'https://www.google.com/searchbyimage?site=search&sa=X&image_url=' + similar_images
headers = {}
headers[
'User-Agent'] = "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36"
req1 = urllib.request.Request(searchUrl, headers=headers)
resp1 = urllib.request.urlopen(req1)
content = str(resp1.read())
l1 = content.find('AMhZZ')
l2 = content.find('&', l1)
urll = content[l1:l2]
newurl = "https://www.google.com/search?tbs=sbi:" + urll + "&site=search&sa=X"
req2 = urllib.request.Request(newurl, headers=headers)
resp2 = urllib.request.urlopen(req2)
l3 = content.find('/search?sa=X&q=')
l4 = content.find(';', l3 + 19)
urll2 = content[l3 + 19:l4]
return urll2
except:
return "Cloud not connect to Google Images endpoint"
# Building URL parameters
def build_url_parameters(self, arguments):
if arguments['language']:
lang = "&lr="
lang_param = {"Arabic": "lang_ar", "Chinese (Simplified)": "lang_zh-CN",
"Chinese (Traditional)": "lang_zh-TW", "Czech": "lang_cs", "Danish": "lang_da",
"Dutch": "lang_nl", "English": "lang_en", "Estonian": "lang_et", "Finnish": "lang_fi",
"French": "lang_fr", "German": "lang_de", "Greek": "lang_el", "Hebrew": "lang_iw ",
"Hungarian": "lang_hu", "Icelandic": "lang_is", "Italian": "lang_it", "Japanese": "lang_ja",
"Korean": "lang_ko", "Latvian": "lang_lv", "Lithuanian": "lang_lt", "Norwegian": "lang_no",
"Portuguese": "lang_pt", "Polish": "lang_pl", "Romanian": "lang_ro", "Russian": "lang_ru",
"Spanish": "lang_es", "Swedish": "lang_sv", "Turkish": "lang_tr"}
lang_url = lang + lang_param[arguments['language']]
else:
lang_url = ''
if arguments['time_range']:
json_acceptable_string = arguments['time_range'].replace("'", "\"")
d = json.loads(json_acceptable_string)
time_range = ',cdr:1,cd_min:' + d['time_min'] + ',cd_max:' + d['time_max']
else:
time_range = ''
if arguments['exact_size']:
size_array = [x.strip() for x in arguments['exact_size'].split(',')]
exact_size = ",isz:ex,iszw:" + str(size_array[0]) + ",iszh:" + str(size_array[1])
else:
exact_size = ''
built_url = "&tbs="
counter = 0
params = {'color': [arguments['color'], {'red': 'ic:specific,isc:red', 'orange': 'ic:specific,isc:orange',
'yellow': 'ic:specific,isc:yellow', 'green': 'ic:specific,isc:green',
'teal': 'ic:specific,isc:teel', 'blue': 'ic:specific,isc:blue',
'purple': 'ic:specific,isc:purple', 'pink': 'ic:specific,isc:pink',
'white': 'ic:specific,isc:white', 'gray': 'ic:specific,isc:gray',
'black': 'ic:specific,isc:black', 'brown': 'ic:specific,isc:brown'}],
'color_type': [arguments['color_type'],
{'full-color': 'ic:color', 'black-and-white': 'ic:gray', 'transparent': 'ic:trans'}],
'usage_rights': [arguments['usage_rights'],
{'labeled-for-reuse-with-modifications': 'sur:fmc', 'labeled-for-reuse': 'sur:fc',
'labeled-for-noncommercial-reuse-with-modification': 'sur:fm',
'labeled-for-nocommercial-reuse': 'sur:f'}],
'size': [arguments['size'],
{'large': 'isz:l', 'medium': 'isz:m', 'icon': 'isz:i', '>400*300': 'isz:lt,islt:qsvga',
'>640*480': 'isz:lt,islt:vga', '>800*600': 'isz:lt,islt:svga',
'>1024*768': 'visz:lt,islt:xga', '>2MP': 'isz:lt,islt:2mp', '>4MP': 'isz:lt,islt:4mp',
'>6MP': 'isz:lt,islt:6mp', '>8MP': 'isz:lt,islt:8mp', '>10MP': 'isz:lt,islt:10mp',
'>12MP': 'isz:lt,islt:12mp', '>15MP': 'isz:lt,islt:15mp', '>20MP': 'isz:lt,islt:20mp',
'>40MP': 'isz:lt,islt:40mp', '>70MP': 'isz:lt,islt:70mp'}],
'type': [arguments['type'], {'face': 'itp:face', 'photo': 'itp:photo', 'clipart': 'itp:clipart',
'line-drawing': 'itp:lineart', 'animated': 'itp:animated'}],
'time': [arguments['time'], {'past-24-hours': 'qdr:d', 'past-7-days': 'qdr:w', 'past-month': 'qdr:m',
'past-year': 'qdr:y'}],
'aspect_ratio': [arguments['aspect_ratio'],
{'tall': 'iar:t', 'square': 'iar:s', 'wide': 'iar:w', 'panoramic': 'iar:xw'}],
'format': [arguments['format'],
{'jpg': 'ift:jpg', 'gif': 'ift:gif', 'png': 'ift:png', 'bmp': 'ift:bmp', 'svg': 'ift:svg',
'webp': 'webp', 'ico': 'ift:ico', 'raw': 'ift:craw'}]}
for key, value in params.items():
if value[0] is not None:
ext_param = value[1][value[0]]
# counter will tell if it is first param added or not
if counter == 0:
# add it to the built url
built_url = built_url + ext_param
counter += 1
else:
built_url = built_url + ',' + ext_param
counter += 1
built_url = lang_url + built_url + exact_size + time_range
return built_url
# building main search URL
def build_search_url(self, search_term, params, url, similar_images, specific_site, safe_search):
# check safe_search
safe_search_string = "&safe=active"
# check the args and choose the URL
if url:
url = url
elif similar_images:
print(similar_images)
keywordem = self.similar_images(similar_images)
url = 'https://www.google.com/search?q=' + keywordem + '&espv=2&biw=1366&bih=667&site=webhp&source=lnms&tbm=isch&sa=X&ei=XosDVaCXD8TasATItgE&ved=0CAcQ_AUoAg'
elif specific_site:
url = 'https://www.google.com/search?q=' + quote(
search_term.encode(
'utf-8')) + '&as_sitesearch=' + specific_site + '&espv=2&biw=1366&bih=667&site=webhp&source=lnms&tbm=isch' + params + '&sa=X&ei=XosDVaCXD8TasATItgE&ved=0CAcQ_AUoAg'
else:
url = 'https://www.google.com/search?q=' + quote(
search_term.encode(
'utf-8')) + '&espv=2&biw=1366&bih=667&site=webhp&source=lnms&tbm=isch' + params + '&sa=X&ei=XosDVaCXD8TasATItgE&ved=0CAcQ_AUoAg'
# safe search check
if safe_search:
url = url + safe_search_string
return url
# measures the file size
def file_size(self, file_path):
if os.path.isfile(file_path):
file_info = os.stat(file_path)
size = file_info.st_size
for x in ['bytes', 'KB', 'MB', 'GB', 'TB']:
if size < 1024.0:
return "%3.1f %s" % (size, x)
size /= 1024.0
return size
# keywords from file
def keywords_from_file(self, file_name):
search_keyword = []
with codecs.open(file_name, 'r', encoding='utf-8-sig') as f:
if '.csv' in file_name:
for line in f:
if line in ['\n', '\r\n']:
pass
else:
search_keyword.append(line.replace('\n', '').replace('\r', ''))
elif '.txt' in file_name:
for line in f:
if line in ['\n', '\r\n']:
pass
else:
search_keyword.append(line.replace('\n', '').replace('\r', ''))
else:
print("Invalid file type: Valid file types are either .txt or .csv \n"
"exiting...")
sys.exit()
return search_keyword
# make directories
def create_directories(self, main_directory, dir_name):
# make a search keyword directory
try:
if not os.path.exists(main_directory):
os.makedirs(main_directory)
time.sleep(0.2)
path = (dir_name)
sub_directory = os.path.join(main_directory, path)
if not os.path.exists(sub_directory):
os.makedirs(sub_directory)
else:
path = (dir_name)
sub_directory = os.path.join(main_directory, path)
if not os.path.exists(sub_directory):
os.makedirs(sub_directory)
except OSError as e:
if e.errno != 17:
raise
pass
return
# Download Images
def download_image(self, image_url, image_format, main_directory, dir_name, count, print_urls, socket_timeout,
prefix, print_size, no_numbering, download, save_source, img_src, silent_mode,
format, ignore_urls):
download_message = ''
if not download:
download_message = '%s %s' % (image_url, download_message)
return 'success', download_message, None, image_url
if ignore_urls:
if any(url in image_url for url in ignore_urls.split(',')):
return "fail", "Image ignored due to 'ignore url' parameter", None, image_url
try:
req = Request(image_url, headers={
"User-Agent": "Mozilla/5.0 (X11; Linux i686) AppleWebKit/537.17 (KHTML, like Gecko) Chrome/24.0.1312.27 Safari/537.17"})
try:
# timeout time to download an image
if socket_timeout:
timeout = float(socket_timeout)
else:
timeout = 10
response = urlopen(req, None, timeout)
data = response.read()
response.close()
extensions = [".jpg", ".jpeg", ".gif", ".png", ".bmp", ".svg", ".webp", ".ico"]
# keep everything after the last '/'
image_name = str(image_url[(image_url.rfind('/')) + 1:])
if format:
if not image_format or image_format != format:
download_status = 'fail'
download_message = "Wrong image format returned. Skipping..."
return_image_name = ''
absolute_path = ''
download_message = '%s %s' % (image_url, download_message)
return download_status, download_message, return_image_name, absolute_path
if image_format == "" or not image_format or "." + image_format not in extensions:
download_status = 'fail'
download_message = "Invalid or missing image format. Skipping..."
return_image_name = ''
absolute_path = ''
download_message = '%s %s' % (image_url, download_message)
return download_status, download_message, return_image_name, absolute_path
elif image_name.lower().find("." + image_format) < 0:
image_name = image_name + "." + image_format
else:
image_name = image_name[:image_name.lower().find("." + image_format) + (len(image_format) + 1)]
# prefix name in image
if prefix:
prefix = prefix + " "
else:
prefix = ''
if no_numbering:
path = main_directory + "/" + dir_name + "/" + prefix + image_name
else:
path = main_directory + "/" + dir_name + "/" + prefix + str(count) + "." + image_name
try:
output_file = open(path, 'wb')
output_file.write(data)
output_file.close()
if save_source:
list_path = main_directory + "/" + save_source + ".txt"
list_file = open(list_path, 'a')
list_file.write(path + '\t' + img_src + '\n')
list_file.close()
absolute_path = os.path.abspath(path)
except OSError as e:
download_status = 'fail'
download_message = "OSError on an image...trying next one..." + " Error: " + str(e)
return_image_name = ''
absolute_path = ''
# return image name back to calling method to use it for thumbnail downloads
download_status = 'success'
download_message = '%s %s' % (image_url, download_message)
return_image_name = prefix + str(count) + "." + image_name
# image size parameter
if not silent_mode:
if print_size:
print("Image Size: " + str(self.file_size(path)))
except UnicodeEncodeError as e:
download_status = 'fail'
download_message = "UnicodeEncodeError on an image...trying next one..." + " Error: " + str(e)
return_image_name = ''
absolute_path = ''
except URLError as e:
download_status = 'fail'
download_message = "URLError on an image...trying next one..." + " Error: " + str(e)
return_image_name = ''
absolute_path = ''
except BadStatusLine as e:
download_status = 'fail'
download_message = "BadStatusLine on an image...trying next one..." + " Error: " + str(e)
return_image_name = ''
absolute_path = ''
except HTTPError as e: # If there is any HTTPError
download_status = 'fail'
download_message = "HTTPError on an image...trying next one..." + " Error: " + str(e)
return_image_name = ''
absolute_path = ''
except URLError as e:
download_status = 'fail'
download_message = "URLError on an image...trying next one..." + " Error: " + str(e)
return_image_name = ''
absolute_path = ''
except ssl.CertificateError as e:
download_status = 'fail'
download_message = "CertificateError on an image...trying next one..." + " Error: " + str(e)
return_image_name = ''
absolute_path = ''
except IOError as e: # If there is any IOError
download_status = 'fail'
download_message = "IOError on an image...trying next one..." + " Error: " + str(e)
return_image_name = ''
absolute_path = ''
except IncompleteRead as e:
download_status = 'fail'
download_message = "IncompleteReadError on an image...trying next one..." + " Error: " + str(e)
return_image_name = ''
absolute_path = ''
return download_status, download_message, return_image_name, absolute_path
# Finding 'Next Image' from the given raw page
def _get_next_item(self, s):
start_line = s.find('imgpt')
if start_line == -1: # If no links are found then give an error!
end_quote = 0
link = "no_links"
return link, end_quote
else:
start_line = s.find('class="imgpt"')
start_object = s.find('m="{', start_line)
end_object = s.find('}"', start_object)
object_raw = str(s[(start_object + 3):(end_object + 1)])
# remove escape characters with python 3.4+
try:
object_decode = bytes(html.unescape(object_raw), "utf-8").decode("unicode_escape")
final_object = json.loads(object_decode)
except:
final_object = ""
return final_object, end_object
# Getting all links with the help of '_images_get_next_image'
def _get_all_items(self, page, main_directory, dir_name, limit, arguments):
items = []
abs_path = []
errorCount = 0
i = 0
count = 1
while count < limit + 1:
object, end_content = self._get_next_item(page)
if object == "no_links":
break
elif object == "":
page = page[end_content:]
elif arguments['offset'] and count < int(arguments['offset']):
count += 1
page = page[end_content:]
else:
# format the item for readability
object = self.format_object(object)
if arguments['metadata']:
if not arguments["silent_mode"]:
print("\nImage Metadata: " + str(object))
# download the images
download_status, download_message, return_image_name, absolute_path = self.download_image(
object['image_link'], object['image_format'], main_directory, dir_name, count,
arguments['print_urls'], arguments['socket_timeout'], arguments['prefix'], arguments['print_size'],
arguments['no_numbering'], arguments['download'], arguments['save_source'],
object['image_source'], arguments["silent_mode"], arguments['format'],
arguments['ignore_urls'])
if not arguments["silent_mode"]:
print('%g/%g %s' % (count, limit, download_message))
if download_status == "success":
count += 1
object['image_filename'] = return_image_name
items.append(object) # Append all the links in the list named 'Links'
abs_path.append(absolute_path)
else:
errorCount += 1
# delay param
if arguments['delay']:
time.sleep(int(arguments['delay']))
page = page[end_content:]
i += 1
if count < limit:
print("Unfortunately all " + str(
limit - count) + " could not be downloaded because some images were not downloadable. " + str(
count - 1) + " is all we got for this search filter!")
return items, errorCount, abs_path
第三周作业:
from __future__ import print_function
import re
import time
import sys
import os
import json
import codecs
import shutil
from urllib.parse import unquote, quote
from selenium import webdriver
from selenium.webdriver import DesiredCapabilities
import requests
from concurrent import futures
if getattr(sys, 'frozen', False):
bundle_dir = sys._MEIPASS
else:
bundle_dir = os.path.dirname(os.path.abspath(__file__))
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = (
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.100"
)
def my_print(msg, quiet=False):
if not quiet:
print(msg)
def google_gen_query_url(keywords, face_only=False, safe_mode=False, image_type=None, color=None):
base_url = "https://www.google.com/search?tbm=isch&hl=en"
keywords_str = "&q=" + quote(keywords)
query_url = base_url + keywords_str
if safe_mode is True:
query_url += "&safe=on"
else:
query_url += "&safe=off"
filter_url = "&tbs="
if color is not None:
if color == "bw":
filter_url += "ic:gray%2C"
else:
filter_url += "ic:specific%2Cisc:{}%2C".format(color.lower())
if image_type is not None:
if image_type.lower() == "linedrawing":
image_type = "lineart"
filter_url += "itp:{}".format(image_type)
if face_only is True:
filter_url += "itp:face"
query_url += filter_url
return query_url
def google_image_url_from_webpage(driver, max_number, quiet=False):
thumb_elements_old = []
thumb_elements = []
while True:
try:
thumb_elements = driver.find_elements_by_class_name("rg_i")
my_print("Find {} images.".format(len(thumb_elements)), quiet)
if len(thumb_elements) >= max_number:
break
if len(thumb_elements) == len(thumb_elements_old):
break
thumb_elements_old = thumb_elements
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
show_more = driver.find_elements_by_class_name("mye4qd")
if len(show_more) == 1 and show_more[0].is_displayed() and show_more[0].is_enabled():
my_print("Click show_more button.", quiet)
show_more[0].click()
time.sleep(3)
except Exception as e:
print("Exception ", e)
pass
if len(thumb_elements) == 0:
return []
my_print("Click on each thumbnail image to get image url, may take a moment ...", quiet)
retry_click = []
for i, elem in enumerate(thumb_elements):
try:
if i != 0 and i % 50 == 0:
my_print("{} thumbnail clicked.".format(i), quiet)
if not elem.is_displayed() or not elem.is_enabled():
retry_click.append(elem)
continue
elem.click()
except Exception as e:
print("Error while clicking in thumbnail:", e)
retry_click.append(elem)
if len(retry_click) > 0:
my_print("Retry some failed clicks ...", quiet)
for elem in retry_click:
try:
if elem.is_displayed() and elem.is_enabled():
elem.click()
except Exception as e:
print("Error while retrying click:", e)
image_elements = driver.find_elements_by_class_name("islib")
image_urls = list()
url_pattern = r"imgurl=\S*&imgrefurl"
for image_element in image_elements[:max_number]:
outer_html = image_element.get_attribute("outerHTML")
re_group = re.search(url_pattern, outer_html)
if re_group is not None:
image_url = unquote(re_group.group()[7:-14])
image_urls.append(image_url)
return image_urls
def bing_gen_query_url(keywords, face_only=False, safe_mode=False, image_type=None, color=None):
base_url = "https://www.bing.com/images/search?"
keywords_str = "&q=" + quote(keywords)
query_url = base_url + keywords_str
filter_url = "&qft="
if face_only is True:
filter_url += "+filterui:face-face"
if image_type is not None:
filter_url += "+filterui:photo-{}".format(image_type)
if color is not None:
if color == "bw" or color == "color":
filter_url += "+filterui:color2-{}".format(color.lower())
else:
filter_url += "+filterui:color2-FGcls_{}".format(color.upper())
query_url += filter_url
return query_url
def bing_image_url_from_webpage(driver):
image_urls = list()
time.sleep(10)
img_count = 0
while True:
image_elements = driver.find_elements_by_class_name("iusc")
if len(image_elements) > img_count:
img_count = len(image_elements)
driver.execute_script(
"window.scrollTo(0, document.body.scrollHeight);")
else:
smb = driver.find_elements_by_class_name("btn_seemore")
if len(smb) > 0 and smb[0].is_displayed():
smb[0].click()
else:
break
time.sleep(3)
for image_element in image_elements:
m_json_str = image_element.get_attribute("m")
m_json = json.loads(m_json_str)
image_urls.append(m_json["murl"])
return image_urls
baidu_color_code = {
"white": 1024, "bw": 2048, "black": 512, "pink": 64, "blue": 16, "red": 1,
"yellow": 2, "purple": 32, "green": 4, "teal": 8, "orange": 256, "brown": 128
}
def baidu_gen_query_url(keywords, face_only=False, safe_mode=False, color=None):
base_url = "https://image.baidu.com/search/index?tn=baiduimage"
keywords_str = "&word=" + quote(keywords)
query_url = base_url + keywords_str
if face_only is True:
query_url += "&face=1"
if color is not None:
print(color, baidu_color_code[color.lower()])
if color is not None:
query_url += "&ic={}".format(baidu_color_code[color.lower()])
print(query_url)
return query_url
def baidu_image_url_from_webpage(driver):
time.sleep(10)
image_elements = driver.find_elements_by_class_name("imgitem")
image_urls = list()
for image_element in image_elements:
image_url = image_element.get_attribute("data-objurl")
image_urls.append(image_url)
return image_urls
def baidu_get_image_url_using_api(keywords, max_number=10000, face_only=False,
proxy=None, proxy_type=None):
def decode_url(url):
in_table = '0123456789abcdefghijklmnopqrstuvw'
out_table = '7dgjmoru140852vsnkheb963wtqplifca'
translate_table = str.maketrans(in_table, out_table)
mapping = {'_z2C$q': ':', '_z&e3B': '.', 'AzdH3F': '/'}
for k, v in mapping.items():
url = url.replace(k, v)
return url.translate(translate_table)
base_url = "https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592"\
"&lm=7&fp=result&ie=utf-8&oe=utf-8&st=-1"
keywords_str = "&word={}&queryWord={}".format(
quote(keywords), quote(keywords))
query_url = base_url + keywords_str
query_url += "&face={}".format(1 if face_only else 0)
init_url = query_url + "&pn=0&rn=30"
proxies = None
if proxy and proxy_type:
proxies = {"http": "{}://{}".format(proxy_type, proxy),
"https": "{}://{}".format(proxy_type, proxy)}
# headers = {
# #'Accept-Encoding': 'gzip, deflate, sdch',
# #'Accept-Language': 'en-US,en;q=0.8',
# #'Upgrade-Insecure-Requests': '1',
# 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
# #'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8',
# #'Cache-Control': 'max-age=0',
# #'Connection': 'keep-alive',
# }
headers = {
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1'
}
res = requests.get(init_url, proxies=proxies, headers=headers)
# init_json = json.loads(res.text.replace(r"\'", ""), encoding='utf-8', strict=False)
init_json = json.loads(res.text.replace(r"\'", ""))
total_num = init_json['listNum']
target_num = min(max_number, total_num)
crawl_num = min(target_num * 2, total_num)
crawled_urls = list()
batch_size = 30
with futures.ThreadPoolExecutor(max_workers=5) as executor:
future_list = list()
def process_batch(batch_no, batch_size):
image_urls = list()
url = query_url + \
"&pn={}&rn={}".format(batch_no * batch_size, batch_size)
try_time = 0
while True:
try:
response = requests.get(url, proxies=proxies, headers=headers)
break
except Exception as e:
try_time += 1
if try_time > 3:
print(e)
return image_urls
response.encoding = 'utf-8'
# res_json = json.loads(response.text.replace(r"\'", ""), encoding='utf-8', strict=False)
res_json = json.loads(response.text.replace(r"\'", ""))
for data in res_json['data']:
if 'objURL' in data.keys():
image_urls.append(decode_url(data['objURL']))
elif 'replaceUrl' in data.keys() and len(data['replaceUrl']) == 2:
image_urls.append(data['replaceUrl'][1]['ObjURL'])
return image_urls
for i in range(0, int((crawl_num + batch_size - 1) / batch_size)):
future_list.append(executor.submit(process_batch, i, batch_size))
for future in futures.as_completed(future_list):
if future.exception() is None:
crawled_urls += future.result()
else:
print(future.exception())
return crawled_urls[:min(len(crawled_urls), target_num)]
def crawl_image_urls(keywords, engine="Google", max_number=10000,
face_only=False, safe_mode=False, proxy=None,
proxy_type="http", quiet=False, browser="phantomjs", image_type=None, color=None):
"""
Scrape image urls of keywords from Google Image Search
:param keywords: keywords you want to search
:param engine: search engine used to search images
:param max_number: limit the max number of image urls the function output, equal or less than 0 for unlimited
:param face_only: image type set to face only, provided by Google
:param safe_mode: switch for safe mode of Google Search
:param proxy: proxy address, example: socks5 127.0.0.1:1080
:param proxy_type: socks5, http
:param browser: browser to use when crawl image urls from Google & Bing
:return: list of scraped image urls
"""
global driver
my_print("\nScraping From {0} Image Search ...\n".format(engine), quiet)
my_print("Keywords: " + keywords, quiet)
if max_number <= 0:
my_print("Number: No limit", quiet)
max_number = 10000
else:
my_print("Number: {}".format(max_number), quiet)
my_print("Face Only: {}".format(str(face_only)), quiet)
my_print("Safe Mode: {}".format(str(safe_mode)), quiet)
if engine == "Google":
query_url = google_gen_query_url(keywords, face_only, safe_mode, image_type, color)
elif engine == "Bing":
query_url = bing_gen_query_url(keywords, face_only, safe_mode, image_type, color)
elif engine == "Baidu":
query_url = baidu_gen_query_url(keywords, face_only, safe_mode, color)
else:
return
my_print("Query URL: " + query_url, quiet)
# if engine != "Baidu":
if True:
browser = str.lower(browser)
if "chrome" in browser:
chrome_path = shutil.which("chromedriver")
chrome_path = "./bin/chromedriver" if chrome_path is None else chrome_path
chrome_options = webdriver.ChromeOptions()
if "headless" in browser:
chrome_options.add_argument("headless")
if proxy is not None and proxy_type is not None:
chrome_options.add_argument("--proxy-server={}://{}".format(proxy_type, proxy))
driver = webdriver.Chrome(chrome_path, chrome_options=chrome_options)
else:
phantomjs_path = shutil.which("phantomjs")
phantomjs_path = "./bin/phantomjs" if phantomjs_path is None else phantomjs_path
phantomjs_args = []
if proxy is not None and proxy_type is not None:
phantomjs_args += [
"--proxy=" + proxy,
"--proxy-type=" + proxy_type,
]
driver = webdriver.PhantomJS(executable_path=phantomjs_path,
service_args=phantomjs_args, desired_capabilities=dcap)
if engine == "Google":
driver.set_window_size(1920, 1080)
driver.get(query_url)
image_urls = google_image_url_from_webpage(driver, max_number, quiet)
elif engine == "Bing":
driver.set_window_size(1920, 1080)
driver.get(query_url)
image_urls = bing_image_url_from_webpage(driver)
else: # Baidu
# driver.set_window_size(1920, 1080)
# driver.get(query_url)
# image_urls = baidu_image_url_from_webpage(driver)
image_urls = baidu_get_image_url_using_api(keywords, max_number=max_number, face_only=face_only,
proxy=proxy, proxy_type=proxy_type)
if engine != "Baidu":
driver.close()
if max_number > len(image_urls):
output_num = len(image_urls)
else:
output_num = max_number
my_print("\n== {0} out of {1} crawled images urls will be used.\n".format(
output_num, len(image_urls)), quiet)
return image_urls[0:output_num]