
我把cocomini数据集的annotations里面的cocomini.json文件用 with open ,json.load读入后,把相同图片的annotation合并到了同一个txt文件中,但是最终txt的数量和图片的数量不一样?不知道为啥,正确的应该是一样的,即一张图片对应一个txt,然后把它交给yolov3读取训练

这是合并后的txt
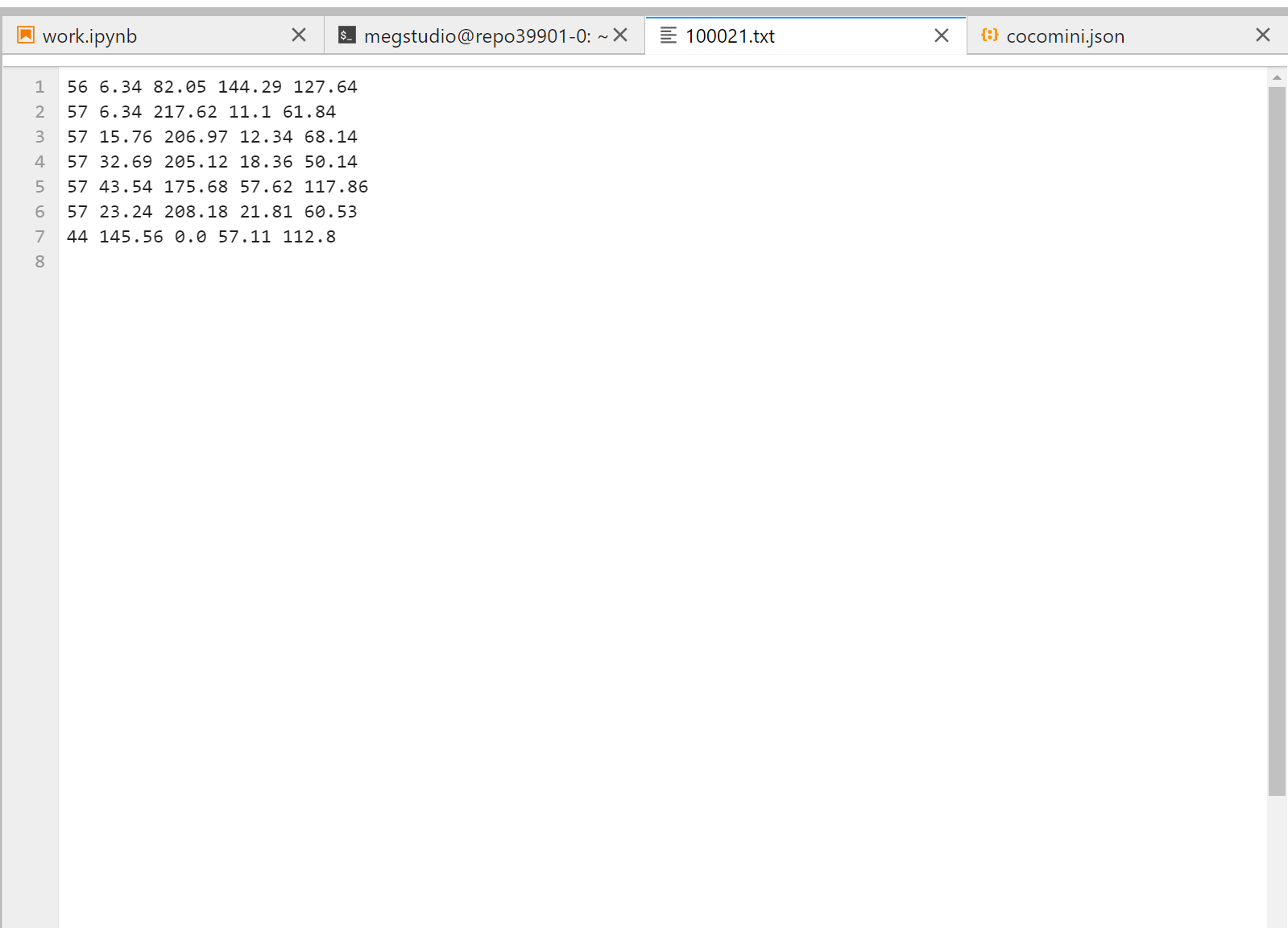
这是合并的代码
import os
d = dict()
for i in range(600000):
d[i] = ‘’
for idx,key in enumerate(dataset[‘annotations’]):
ca_id = key[‘category_id’]
bbox = key[‘bbox’]
img_id = key[‘image_id’]
s = ‘’
s = str(ca_id)
print(“S1 {}”.format(s))
for i in bbox:
s += (' ' + str(i))
s += '\n'
d[int(img_id)] += s
print(“id:{} str:{}”.format(img_id,d[img_id]))
del s
print(“f1”)
pth = “/home/megstudio/workspace/data/cocomini/labels_train/”
if os.path.isfile(pth+"{}.txt".format(img_id))
for i in d:
if d[i] != ‘’:
with open(pth+"{}.txt".format(i),‘w’) as f:
f.write(d[i])
print(‘f2’)
 明白了
明白了