AI-CAMP四期作业贴:【AI培训第四期课后作业内容帖】

第二周作业
作业链接:https://git-core.megvii-inc.com/ai_train/ai_yanwenhui/-/tree/master/week-2
task1
task2

![]()

AI-CAMP四期作业贴:【AI培训第四期课后作业内容帖】
作业链接:https://git-core.megvii-inc.com/ai_train/ai_yanwenhui/-/tree/master/week-2
task1
task2
![]()
AI-CAMP四期作业贴:【AI培训第四期课后作业内容帖】
统计
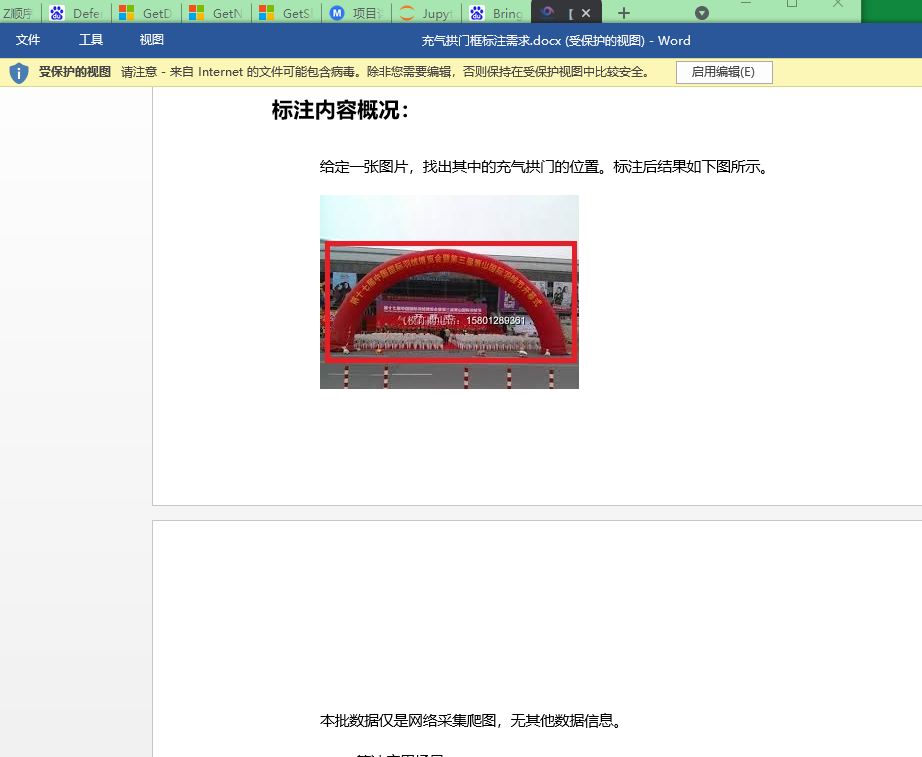
图片crop
https://git-core.megvii-inc.com/qianlu/ai-learning
img = cv2.imread(‘images_2.jpg’)
H, W = 200, 200
seq = iaa.Sequential([
iaa.Fliplr(0.5),
iaa.Flipud(0.5),
iaa.Crop(px=(0, 16)),
iaa.Resize({“height”: H, “width”: W}),
iaa.GaussianBlur(2.0),
iaa.EdgeDetect(alpha=(0, 0.7)),
iaa.Sometimes(0.5, iaa.Crop(px=(0, 16))),
iaa.Sometimes(0.5, iaa.Affine(
# 图像缩放80%-120%
scale={“x”: (0.8, 1.2), “y”: (0.8, 1.2)},
# 平移 ±20%
translate_percent={“x”: (-0.2, 0.2), “y”: (-0.2, 0.2)},
# 旋转 45°
rotate=(-45, 45),
# 剪切 16度
shear=(-16, 16),
# 使用临近差值活双线性差值
order=[0, 1],
# 全白全黑填充
cval=(0, 255),
# 定义填充图像外区域的方法
mode=imgaug.ALL
)),
], random_order=True)
NUM = 10
images = np.array([img] * NUM, dtype=np.uint8)
images_aug = seq.augment_images(images)
write_image = np.zeros((H, (W + 10) * (NUM + 1), 3), dtype=np.uint8)
write_image[:, 0:W, :] = img
for i, image in enumerate(images_aug):
write_image[:, (i + 1) * W:(i + 2) * W, :] = image
cv2.imwrite(“img/tmp_aug_random.jpg”, write_image)
https://studio.brainpp.com/project/10338?name=AI_第2节课作业
%matplotlib inline
import matplotlib.pyplot as plt
import megengine as mge
import megengine.functional as F
from megengine.autodiff import GradManager
import megengine.optimizer as optim
import numpy as np
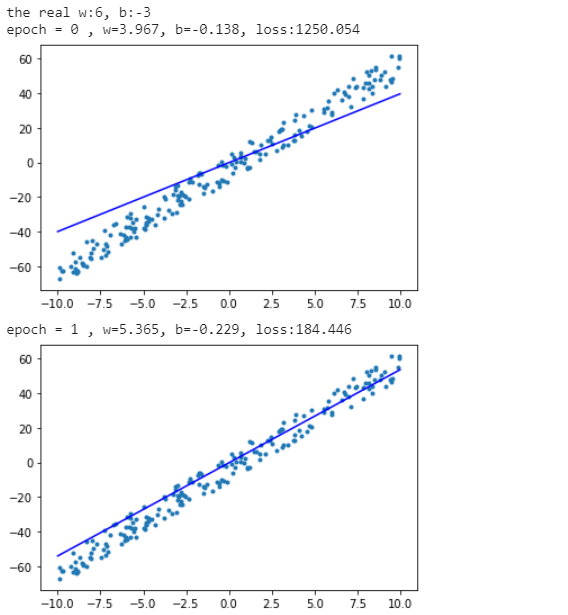
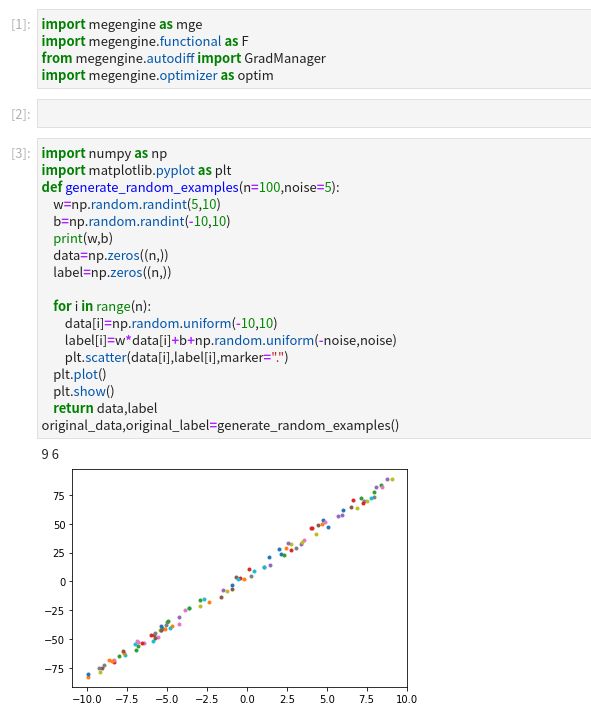
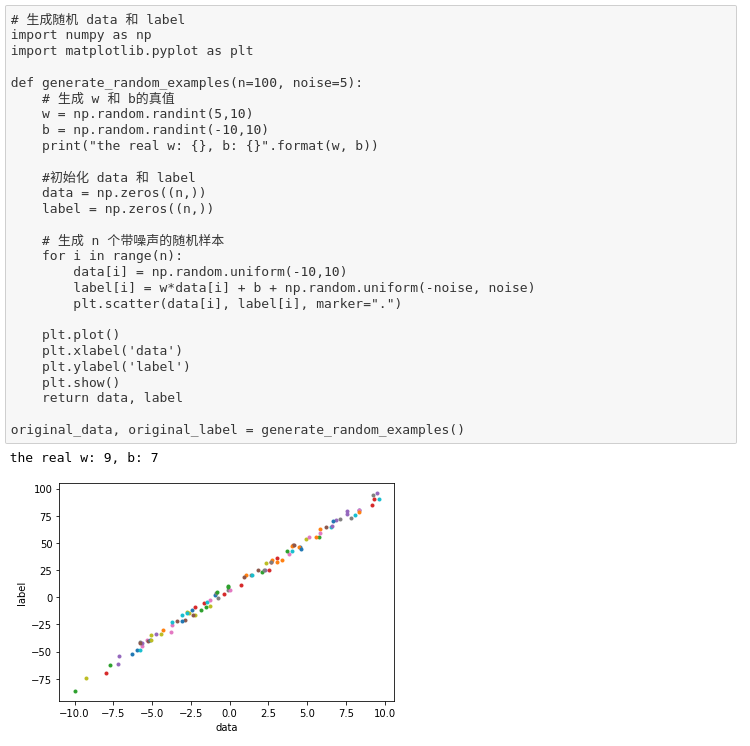
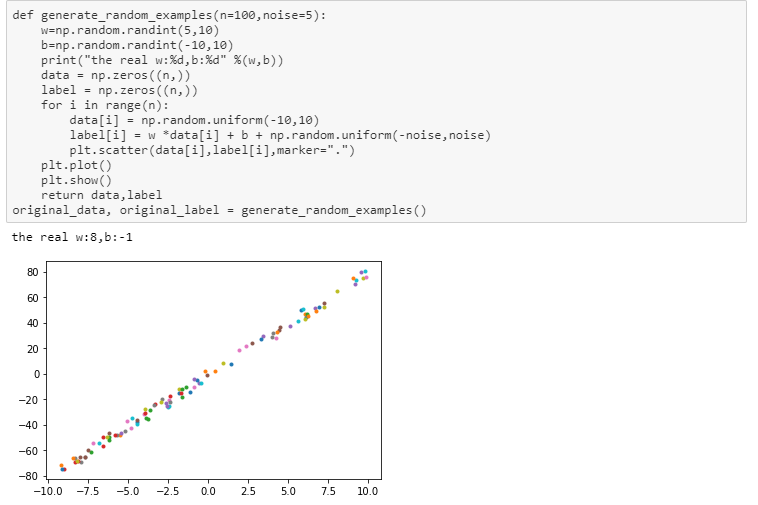
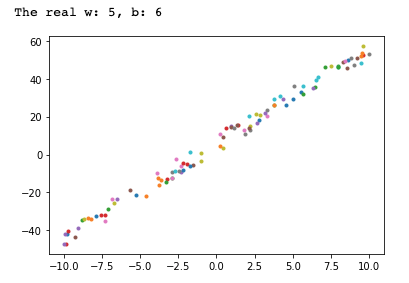
def generate_random_examples(n=100, noise=5):
w = np.random.randint(5, 10)
b = np.random.randint(-10, 10)
print(‘the real w:{}, b:{}’.format(w, b))
data = np.zeros((n,))
label = np.zeros((n,))
for i in range(n):
data[i] = np.random.uniform(-10, 10)
label[i] = w * data[i] + b + np.random.uniform(-noise, noise)
return data, label
o_data, o_label = generate_random_examples(n=200, noise=8)
epochs = 5
lr = 0.01
mt_data = mge.tensor(o_data)
mt_label = mge.tensor(o_label)
m_w = mge.Parameter([0.0])
m_b = mge.Parameter([0.0])
def m_liner_model(x):
return F.mul(m_w, x) + m_b
gm = GradManager().attach([m_w, m_b])
optimizer = optim.SGD([m_w, m_b], lr=lr)
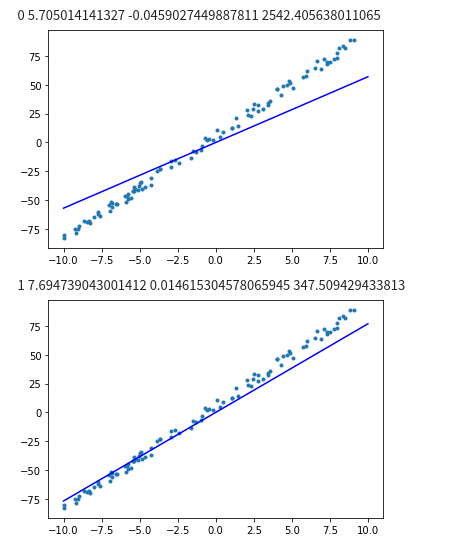
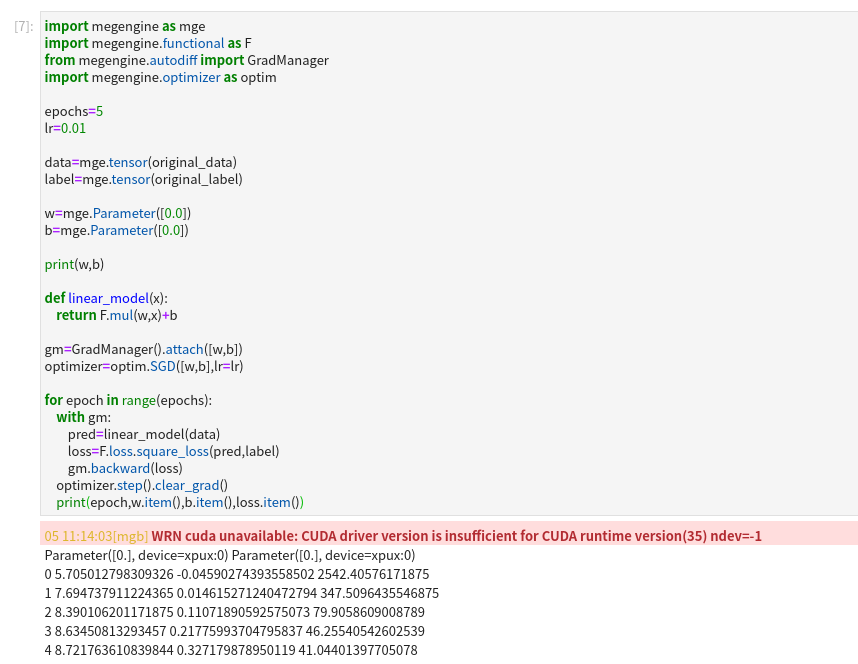
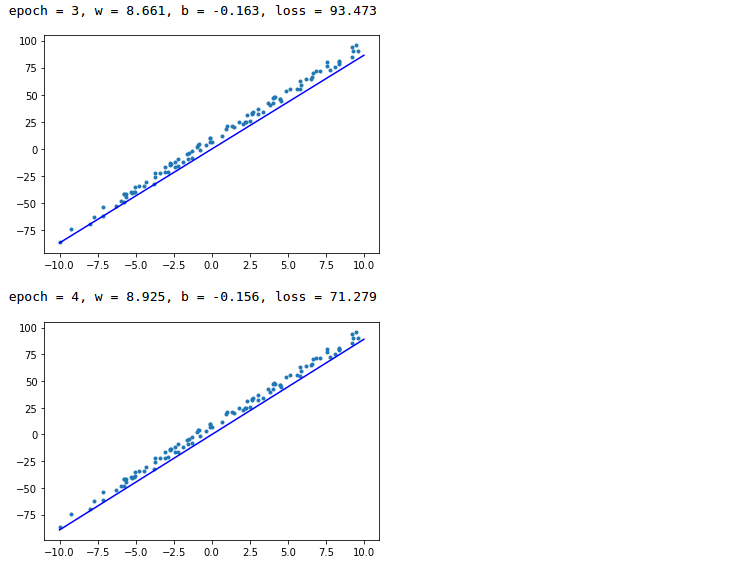
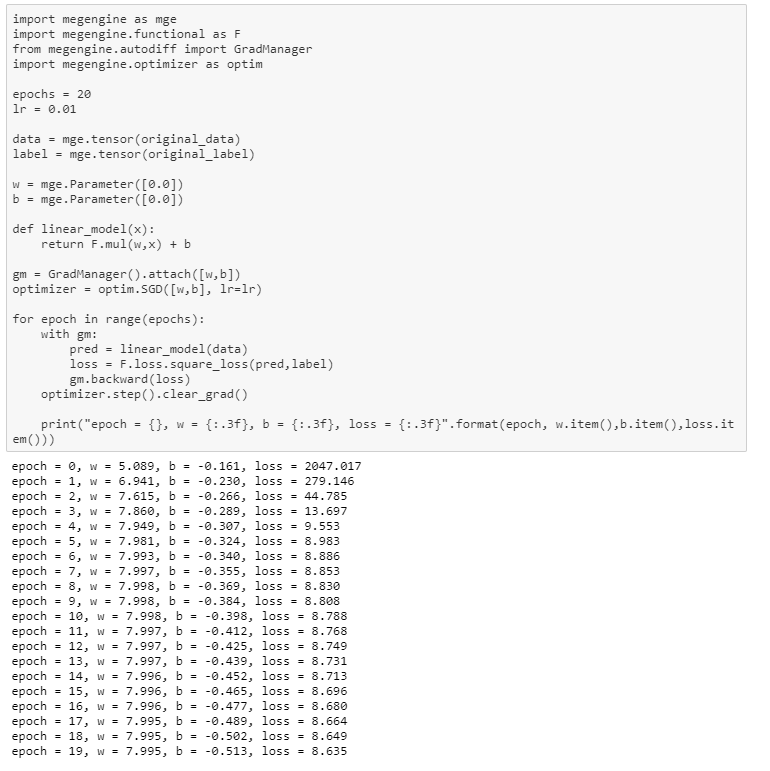
for epoch in range(epochs):
with gm:
pred = m_liner_model(mt_data)
loss = F.loss.square_loss(pred , mt_label)
gm.backward(loss)
optimizer.step().clear_grad()
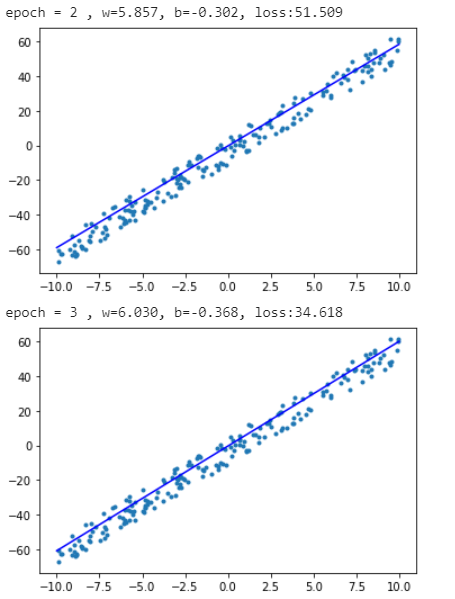
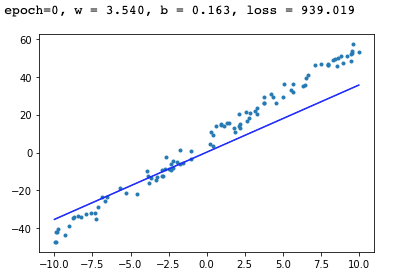
print('epoch = {} , w={:.3f}, b={:.3f}, loss:{:.3f}'.format(epoch, m_w.item(), m_b.item(), loss.item()))
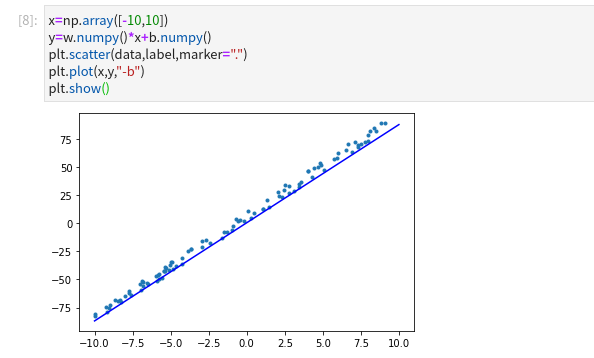
x = np.array([-10, 10])
y = m_w * x + m_b
plt.scatter(o_data, o_label, marker=".")
plt.plot(x, y, "-b")
plt.show()
import json
import time
import requests
from urllib.parse import quote
headers = {
‘Accept’:
‘text/plain, /; q=0.01’,
‘Accept-Language’:
‘zh-CN,zh;q=0.9’,
‘Connection’:
‘keep-alive’,
‘User-Agent’:
‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36’,
}
def search(keyword, num):
imageurl_set =
page = num // 30
keyword = quote(keyword.encode(‘gbk’))
for pn in range(0, page + 1):
get_imageurl = “http://image.baidu.com/search/acjson?tn=resultjson_com&logid=6764420735902983598&ipn=rj&ct=201326592&is=&fp=result&queryWord={}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&word={}&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&fr=&expermode=&force=&pn={}&rn=30&gsm=3c&{}=”.format(
keyword, keyword, pn * 30,
time.time() * 1000)
response = requests.get(get_imageurl, headers=headers, timeout=20)
try:
content = json.loads(response.text)
data = content.get('data')
for each in data[:-1]:
objURL = each.get('hoverURL')
if not objURL:
continue
imageurl_set.append(objURL)
print(objURL)
except Exception as e:
print(e)
return imageurl_set
if name == “main”:
ls = search(“充气拱门”, 20)
num = 1
for i in ls:
print(i)
filename = “D:\tmp\pic\gongmen\gongmen_” + str(num) + “.jpg”
r = requests.get(i)
with open(filename, ‘wb’) as f:
f.write(r.content)
num += 1
AI-CAMP第四期作业贴:
import boto3
import cv2
import imgaug as ia
import imgaug.augmenters as iaa
import nori2 as nori
import numpy as np
import os
from meghair.utils import io
from meghair.utils.imgproc import imdecode
from refile import smart_open
s3_client = boto3.client(“s3”, endpoint_url=“http://oss.i.brainpp.cn”)
resp = s3_client.get_object(Bucket=“ai-cultivate”, Key=“1percent_ImageNet.txt”)
res = resp[“Body”].read().decode(“utf8”)
data = res.split("\n")[:-1]
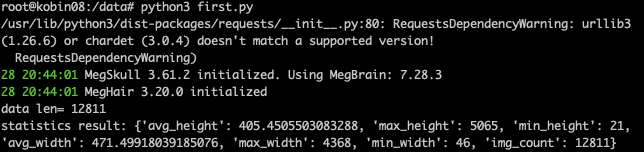
print(“data len=”, len(data))
nori_ids = list(map(lambda x: x.split("\t")[0], data))
fetcher = nori.Fetcher()
datas = list(map(lambda x: imdecode(fetcher.get(x)), nori_ids))
imgs_list =
for k, image in enumerate(datas):
imgs_list.append(
{
“num”: “img_num_{}”.format(k),
“height”: image.shape[0],
“width”: image.shape[1],
}
)
height_list = [img_size[“height”] for img_size in imgs_list]
width_list = [img_size[“width”] for img_size in imgs_list]
avg_height = np.mean(height_list)
max_height = max(height_list)
min_height = min(height_list)
avg_width = np.mean(width_list)
max_width = max(width_list)
min_width = min(width_list)
img_info = {
“avg_height”: avg_height,
“max_height”: max_height,
“min_height”: min_height,
“avg_width”: avg_width,
“max_width”: max_width,
“min_width”: min_width,
“img_count”: len(imgs_list),
}
print(“statistics result: {}”.format(img_info))
datas = datas[-40::2]
H,W = 256, 128
ia.seed(1)
NUM = 5
sometimes = lambda aug: iaa.Sometimes(0.5, aug)
seq = iaa.Sequential([
iaa.Fliplr(0.5),
iaa.Crop(px=(0,16)),
iaa.Resize({“height”: H, “width”: W}),
iaa.GaussianBlur(2.0),
iaa.EdgeDetect(alpha=(0, 0.7)),
sometimes(iaa.Affine(
scale={“x”: (0.8, 1.2), “y”: (0.8, 1.2)},
rotate=(-45, 45),
shear=(-16, 16),
order=[0, 1],
mode=ia.ALL
))
], random_order=True)
res = np.zeros(shape=((H + 10) * len(datas), (W + 10) * NUM, 3), dtype=np.uint8)
for j, data in enumerate(datas):
images = np.array(
[data] * NUM,
dtype=np.uint8
)
write_img = np.zeros((H, (W+10)NUM, 3), dtype=np.uint8)
images_aug = seq.augment_images(images=images)
for i, data in enumerate(images_aug):
write_img[:, i(W+10): i*(W+10)+W, :] = data
res[j * (H + 10) : j * (H + 10) + H, :, :] = write_img
img_file = “./result”
if not os.path.exists(img_file):
os.mkdir(img_file)
cv2.imwrite(img_file + “/frist.jpg”, res)
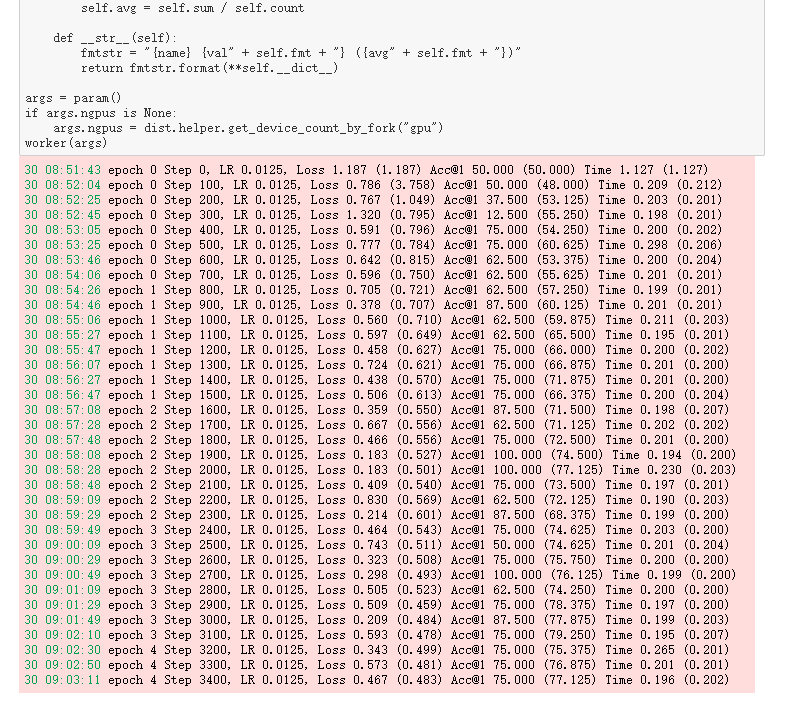
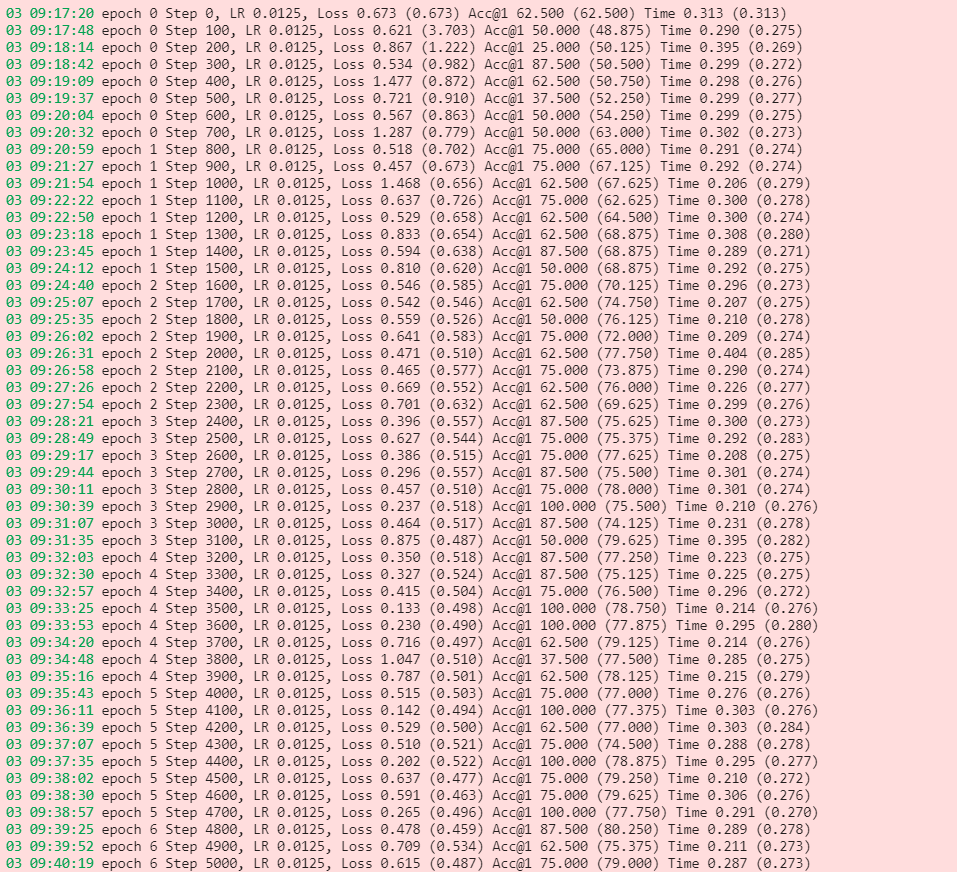
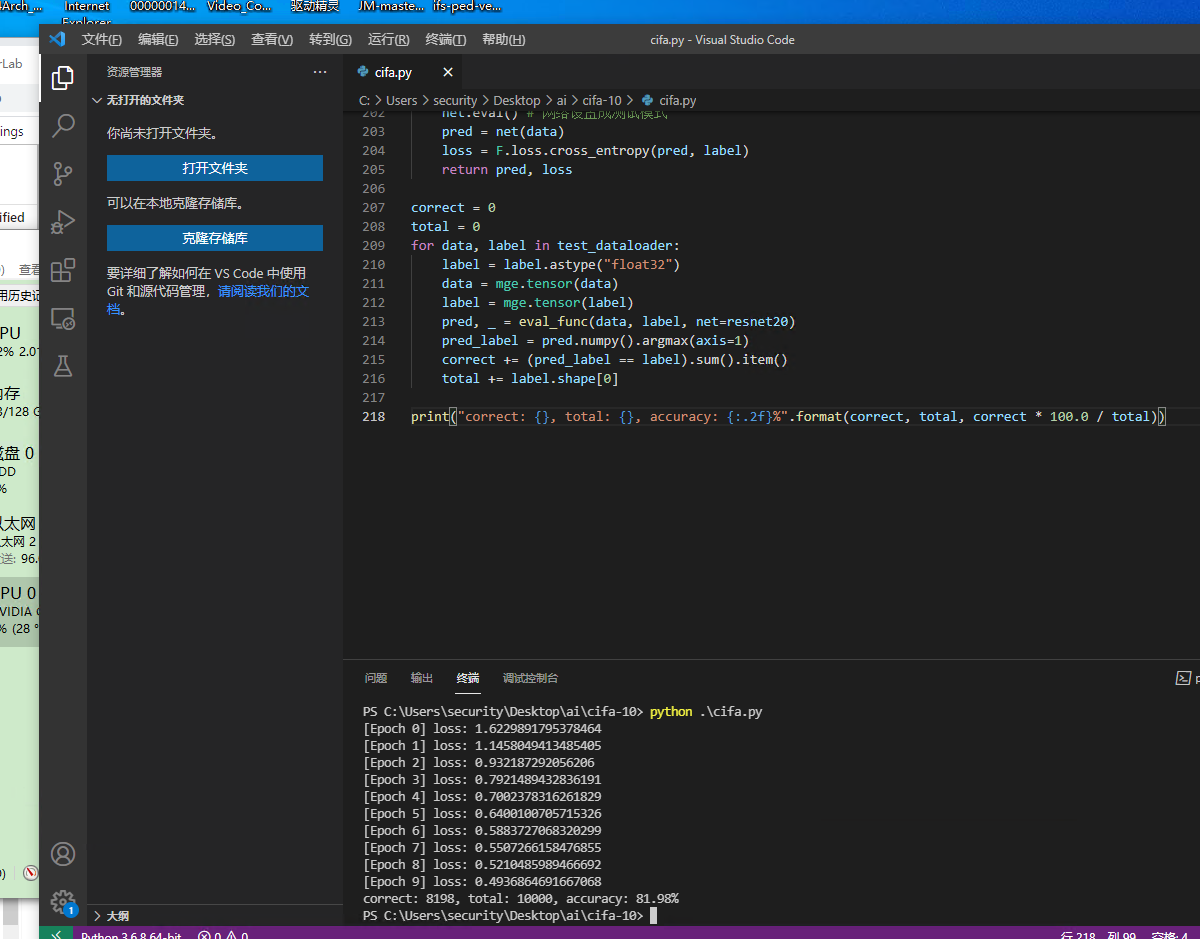
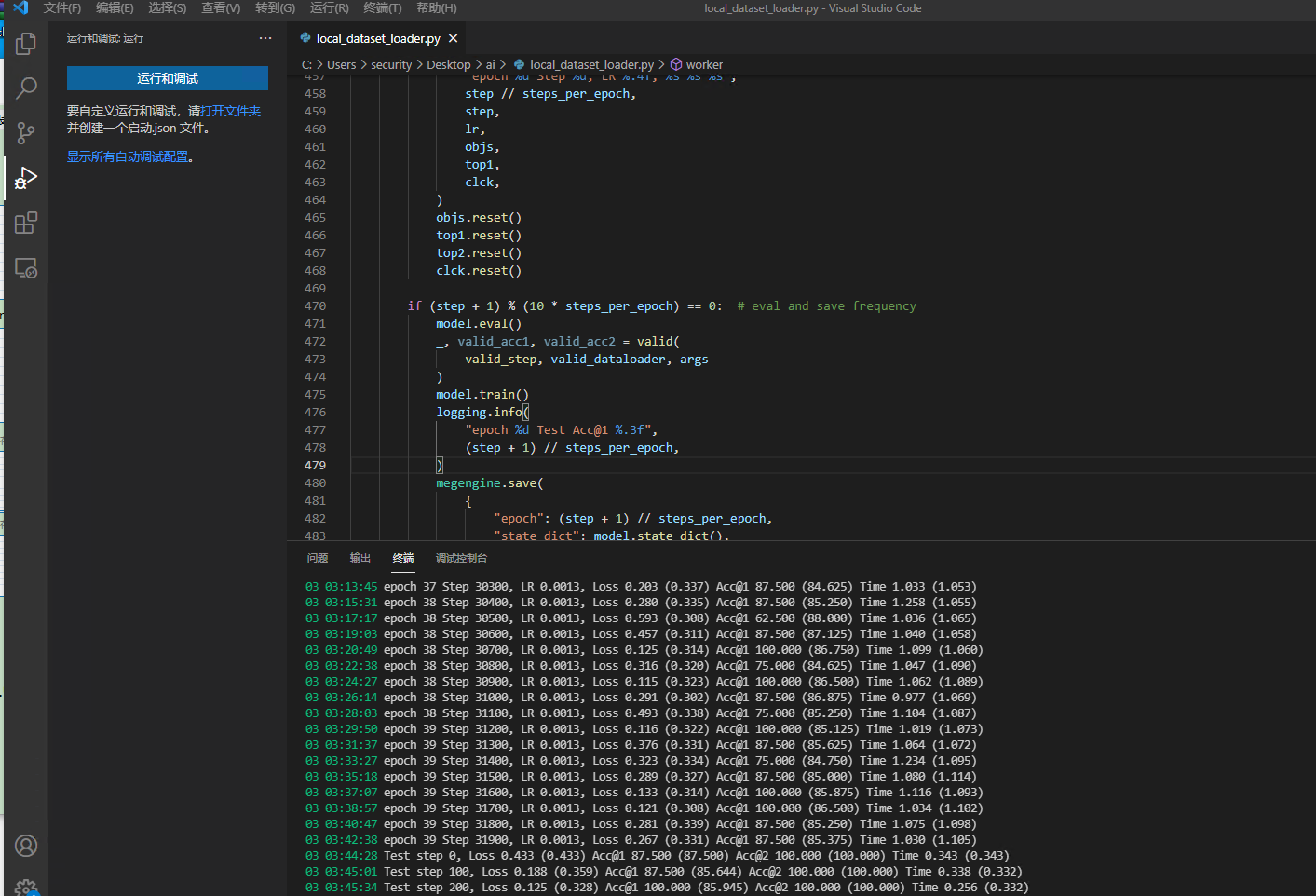
10 17:18:36 epoch 36 Step 28900, LR 0.0013, Loss 0.256 (0.291) Acc@1 87.500 (88.375) Time 0.142 (0.132)
10 17:18:49 epoch 36 Step 29000, LR 0.0013, Loss 0.223 (0.283) Acc@1 87.500 (88.125) Time 0.137 (0.133)
10 17:19:02 epoch 36 Step 29100, LR 0.0013, Loss 0.183 (0.265) Acc@1 87.500 (88.625) Time 0.138 (0.134)
10 17:19:16 epoch 36 Step 29200, LR 0.0013, Loss 0.361 (0.291) Acc@1 87.500 (88.125) Time 0.144 (0.133)
10 17:19:29 epoch 36 Step 29300, LR 0.0013, Loss 0.228 (0.240) Acc@1 75.000 (89.625) Time 0.145 (0.131)
10 17:19:42 epoch 36 Step 29400, LR 0.0013, Loss 0.318 (0.272) Acc@1 87.500 (87.125) Time 0.134 (0.134)
10 17:19:56 epoch 36 Step 29500, LR 0.0013, Loss 0.046 (0.249) Acc@1 100.000 (89.625) Time 0.126 (0.135)
10 17:20:09 epoch 37 Step 29600, LR 0.0013, Loss 0.147 (0.295) Acc@1 87.500 (86.875) Time 0.134 (0.136)
^@10 17:20:23 epoch 37 Step 29700, LR 0.0013, Loss 0.465 (0.284) Acc@1 62.500 (88.375) Time 0.142 (0.135)
10 17:20:36 epoch 37 Step 29800, LR 0.0013, Loss 0.099 (0.290) Acc@1 100.000 (87.375) Time 0.127 (0.135)
10 17:20:50 epoch 37 Step 29900, LR 0.0013, Loss 0.520 (0.270) Acc@1 87.500 (89.500) Time 0.136 (0.137)
10 17:21:03 epoch 37 Step 30000, LR 0.0013, Loss 0.153 (0.287) Acc@1 87.500 (87.625) Time 0.135 (0.132)
10 17:21:17 epoch 37 Step 30100, LR 0.0013, Loss 0.120 (0.244) Acc@1 100.000 (90.125) Time 0.124 (0.133)
^@10 17:21:30 epoch 37 Step 30200, LR 0.0013, Loss 0.211 (0.274) Acc@1 87.500 (87.875) Time 0.136 (0.136)
10 17:21:44 epoch 37 Step 30300, LR 0.0013, Loss 0.169 (0.266) Acc@1 87.500 (89.625) Time 0.131 (0.136)
10 17:21:57 epoch 38 Step 30400, LR 0.0013, Loss 0.056 (0.256) Acc@1 100.000 (89.875) Time 0.147 (0.136)
10 17:22:11 epoch 38 Step 30500, LR 0.0013, Loss 0.486 (0.240) Acc@1 75.000 (90.500) Time 0.135 (0.136)
^@10 17:22:24 epoch 38 Step 30600, LR 0.0013, Loss 0.573 (0.251) Acc@1 75.000 (88.750) Time 0.130 (0.135)
import pickle
import re
import os
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from imgaug import augmenters as iaa
import cv2
class Cifar10:
class test:
pass
def init(self, path, one_hot = True):
self.path = path
self.one_hot = one_hot
self._epochs_completed = 0
self._index_in_epoch = 0
self._num_examples = 50000
def _load_data(self):
dic = {}
images = np.zeros([10000, 3,32,32])
labels = []
files = os.listdir(self.path)
test_images = None
for file in files:
if re.match("data_batch_*", file):
with open(self.path +"/" + file, 'rb') as fo: #load train data
dic = pickle.load(fo, encoding = 'bytes')
images = np.r_[images, dic[b"data"].reshape([-1,3,32,32])]
labels.append(dic[b"labels"])
elif re.match("test_batch", file): #load test data
with open(self.path + "/" + file , 'rb') as fo:
dic = pickle.load(fo, encoding = 'bytes')
test_images = np.array(dic[b"data"].reshape([-1, 3, 32, 32]))
test_labels = np.array(dic[b"labels"])
dic["train_images"] = images[10000:].transpose(0,2,3,1)
dic["train_labels"] = np.array(labels).reshape([-1, 1])
dic["test_images"] = test_images.transpose(0,2,3,1)
dic["test_labels"] = test_labels.reshape([-1, 1])
if self.one_hot == True:
dic["train_labels"] = self._one_hot(dic["train_labels"], 10)
dic["test_labels"] = self._one_hot(dic["test_labels"], 10)
self.images, self.labels = dic["train_images"], dic["train_labels"]
self.test.images, self.test.labels = dic["test_images"], dic["test_labels"]
return [dic["train_images"], dic["train_labels"], dic["test_images"], dic["test_labels"] ]
def next_batch(self, batch_size,shuffle=True):
start = self._index_in_epoch
# Shuffle for the first epoch
if self._epochs_completed == 0 and start == 0 and shuffle:
perm0 = np.arange(self._num_examples)
np.random.shuffle(perm0)
self._images = self.images[perm0]
self._labels = self.labels[perm0]
# Go to the next epoch
if start + batch_size > self._num_examples:
# Finished epoch
self._epochs_completed += 1
# Get the rest examples in this epoch
rest_num_examples = self._num_examples - start
images_rest_part = self._images[start:self._num_examples]
labels_rest_part = self._labels[start:self._num_examples]
# Shuffle the data
if shuffle:
perm = np.arange(self._num_examples)
np.random.shuffle(perm)
self._images = self.images[perm]
self._labels = self.labels[perm]
# Start next epoch
start = 0
self._index_in_epoch = batch_size - rest_num_examples
end = self._index_in_epoch
images_new_part = self._images[start:end]
labels_new_part = self._labels[start:end]
return np.concatenate(
(images_rest_part, images_new_part), axis=0), np.concatenate(
(labels_rest_part, labels_new_part), axis=0)
else:
self._index_in_epoch += batch_size
end = self._index_in_epoch
return self._images[start:end], self._labels[start:end]
def _one_hot(self, labels, num):
size= labels.shape[0]
label_one_hot = np.zeros([size, num])
for i in range(size):
label_one_hot[i, np.squeeze(labels[i])] = 1
return label_one_hot
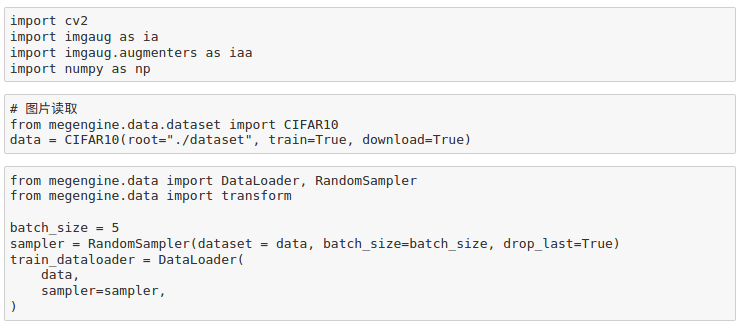
def load_cifar10(path, one_hot = True):
cifar10 = Cifar10(path, one_hot)
cifar10._load_data()
return cifar10
path = r"dataset/cifar-10-batches-py"
cifar10 = load_cifar10(path, one_hot = False)
images = cifar10.images
print(“训练集图片:” + str(images.shape))
labels = cifar10.labels
print(“训练集类别:” + str(labels.shape))
test_images1 = cifar10.test.images
print(“测试集图片:”+ str(test_images1.shape))
test_labels = cifar10.test.labels
print(“测试集类别:”+ str(test_labels.shape))
batch_xs, batch_ys = cifar10.next_batch(batch_size = 500, shuffle = True)
print(“batch_xs shape is:” + str(batch_xs.shape))
print(“batch_ys shape is:” + str(batch_ys.shape))
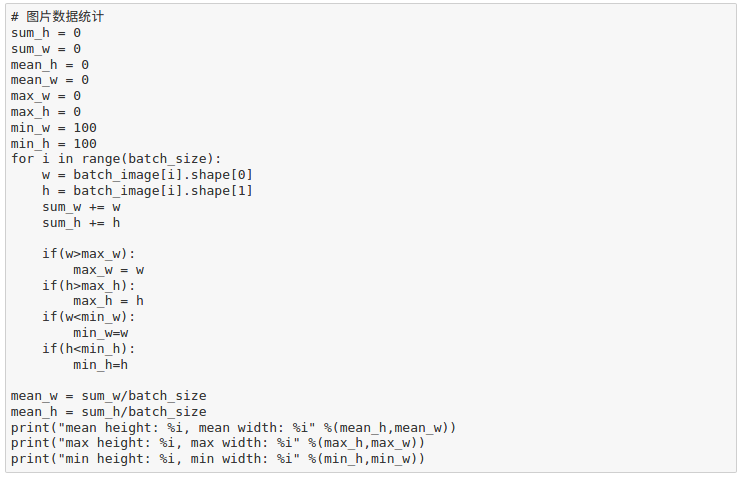
def img_mean_max_min(np_array):
npa = np.array(np_array)
max_w = npa.max(axis=0)
min_h = npa.min(axis=0)
mean_w = npa.mean(axis=0)
mean_h = npa.mean(axis=0)
result_format = [max_w[0],min_h[1],mean_w[0],mean_h[1]]
print(“最大宽: {0}, 最大高: {1},平均宽: {2}, 平均高: {3}”.format(*result_format))
img_shape_list =
for img in images:
img_shape_list.append(list(img.shape))
gap = 16
H, W = 256, 128
NUM = 9
img_mean_max_min(img_shape_list)
sometimes = lambda aug: iaa.Sometimes(0.5, aug)
seq = iaa.Sequential([
iaa.Fliplr(0.5), # 对50%的图像进行镜像旋转
iaa.Flipud(0.2), # 对20%的图像做左右翻转
sometimes(iaa.Crop(px = (0, 100))), # 对随机的一部分图像做crop操作
sometimes(iaa.Affine(
scale={“x”: (0.8, 1.2), “y”: (0.8, 1.2)}, #图像缩放为80% 到120% 之间
translate_percent = {“x”: (-0.2, 0.2), “y”: (-0.2, 0.2)} ,# 平移 ±20%之间
rotate=(-45, 45), # 旋转±45度之间
shear=(-16, 16), # 剪切变换±16度,(矩形变为平行四边形
order=[0,1], # 使用最近相邻差值或者双线性差值
cval = (0, 255), # 全白全黑填充
)),
iaa.Resize({"height": H, "width": W})
], random_order=True)
res = np.zeros(shape=((H + gap)* len(images), (W + gap)*NUM, 3),dtype = np.uint8)
for img in images:
img_shape_list.append(list(img.shape))
images = np.array(
[img] * NUM,
dtype = np.uint8
)
write_img = np.zeros((H, (W + 10) * NUM, 3), dtype = np.uint8)
images_aug = seq(images = images)
for i, img in enumerate(images_aug):
write_img[:, i*(W+10): i*(W+10)+W, :] = img
plt.imshow(write_img, cmap=“gray”)
plt.show()
break

import megengine as mge
import megengine.functional as F
from megengine.autodiff import GradManager
import megengine.optimizer as optim
import numpy as np
import matplotlib.pyplot as plt
def two_layer_conv(x):
print(x.shape)
conv_w = mge.Parameter(np.random.randn(8,3,3,3).astype(np.float32))
conv_bias = mge.Parameter(np.zeros((1, 8, 1, 1), dtype=np.float32))
x = F.conv2d(x, conv_w, conv_bias)
print(x.shape)
x = F.relu(x)
conv_w = mge.Parameter(np.random.randn(16, 8, 3, 3).astype(np.float32))
conv_bias = mge.Parameter(np.zeros((1, 16, 1, 1), dtype=np.float32))
x = F.conv2d(x, conv_w, conv_bias)
print(x.shape)
x = F.relu(x)
print(x.shape)
return x
x = mge.tensor(np.random.randn(2, 3, 32, 32).astype(np.float32))
out = two_layer_conv(x)
print(out.shape)
def generate_random_exp(n=100, noise=5):
w = np.random.randint(5, 10)
b = np.random.randint(-10, 10)
print(“w:{}, b:{}”.format(w, b))
data = np.zeros((n,))
label = np.zeros((n,))
for i in range(n):
data[i] = np.random.uniform(-10, 10)
label[i] = w * data[i] + b + np.random.uniform(-noise, noise)
plt.scatter(data[i], label[i], marker=".")
plt.plot()
plt.show()
return data, label
ori_data, ori_label = generate_random_exp()
epochs = 10
lr = 0.01
data = mge.tensor(ori_data)
label = mge.tensor(ori_label)
w = mge.Parameter([0.0])
b = mge.Parameter([0.0])
def linear_model(x):
return w * x + b
gm = GradManager().attach([w, b])
optimizer = optim.SGD([w, b], lr=lr)
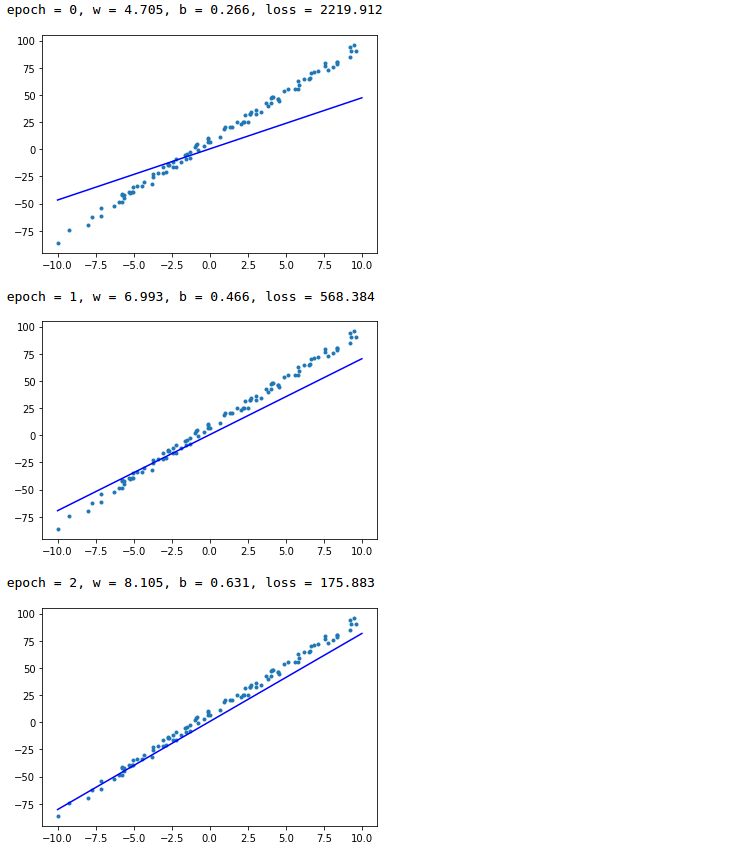
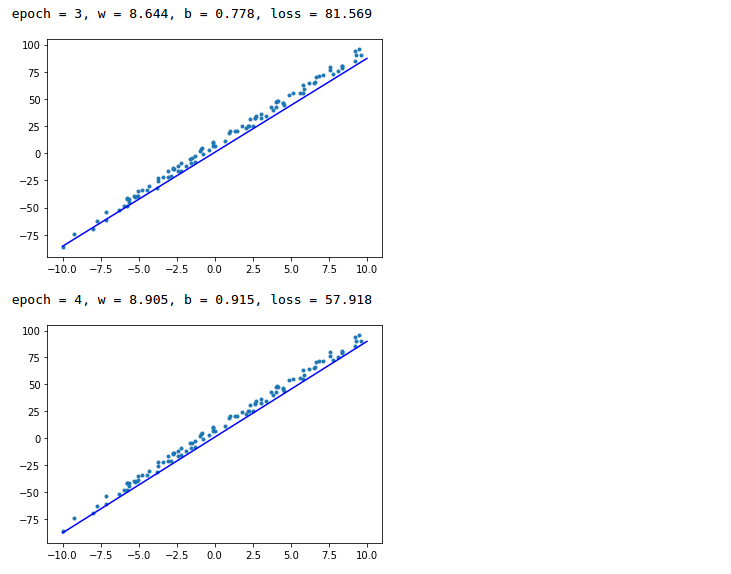
for epoch in range(epochs):
with gm:
pred = linear_model(data)
loss = F.loss.square_loss(pred, label)
gm.backward(loss)
optimizer.step().clear_grad()
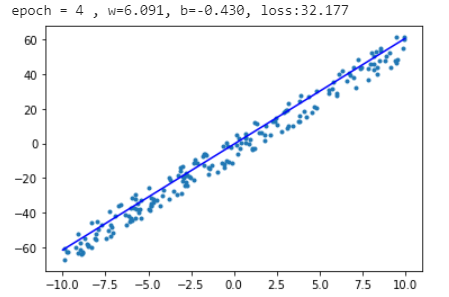
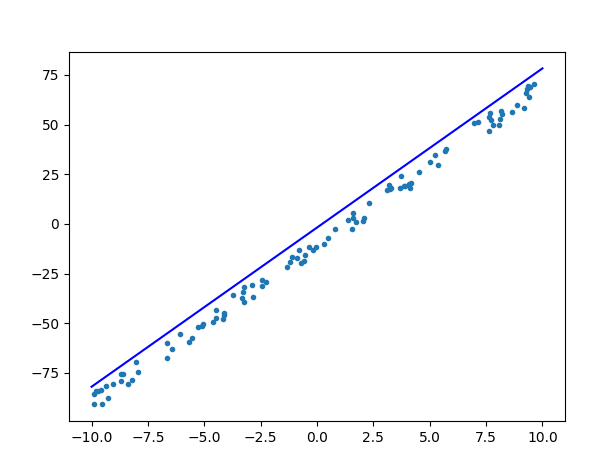
print(“epoch={}, w={:.3f}, b={:.3f}, loss={:.3f}”.format(epoch, w.item(), b.item(), loss.item()))
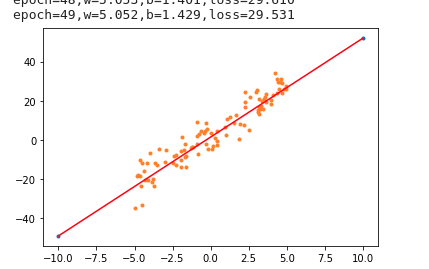
x = np.array([-10, 10])
y = w.numpy() * x + b.numpy()
plt.scatter(data, label, marker=".")
plt.plot(x,y,"-b")
plt.show()
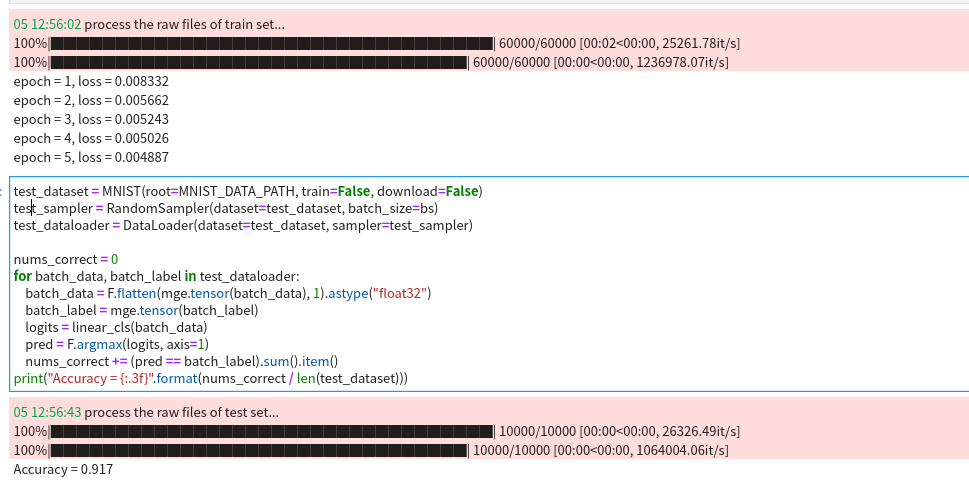
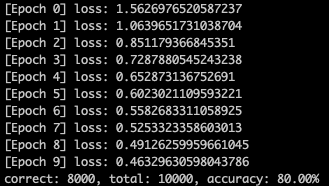
from megengine.data.dataset import MNIST
import megengine.module as M
import megengine.functional as F
import megengine as mge
import numpy as np
from megengine import optimizer
from megengine.autodiff import GradManager
from megengine.data import SequentialSampler, RandomSampler, DataLoader
from megengine.jit import trace
from megengine.data.transform import RandomResizedCrop, Normalize, ToMode, Pad, Compose
class LeNet(M.Module):
def init(self):
super().init()
self.conv1 = M.Conv2d(1, 6, kernel_size=5, bias=False)
self.relu1 = M.ReLU()
self.pool1 = M.MaxPool2d(2, 2)
self.conv2 = M.Conv2d(6, 16, kernel_size=5, bias=False)
self.relu2 = M.ReLU()
self.pool2 = M.MaxPool2d(2, 2)
# 两层全连接 + ReLU
self.fc1 = M.Linear(16 * 5 * 5, 120)
self.relu3 = M.ReLU()
self.fc2 = M.Linear(120, 84)
self.relu4 = M.ReLU()
# 分类器
self.classifier = M.Linear(84, 10)
def forward(self, x):
x = self.pool1(self.relu1(self.conv1(x)))
x = self.pool2(self.relu2(self.conv2(x)))
# F.flatten 将原本形状为 (N, C, H, W) 的张量x从第一个维度(即C)开始拉平成一个维度,
# 得到的新张量形状为 (N, C*H*W) 。 等价于 reshape 操作: x = x.reshape(x.shape[0], -1)
x = F.flatten(x, 1)
x = self.relu3(self.fc1(x))
x = self.relu4(self.fc2(x))
x = self.classifier(x)
return x
def pre_data_processing(mode):
“”"
根据不同的模式生成数据
:param mode: train or test
:return:
“”"
is_train = mode == ‘train’
mnist_dataset = MNIST(root="./dataset/MNIST", train=is_train, download=False)
dataloader = DataLoader(
mnist_dataset,
transform=Compose([
Normalize(mean=0.1307 * 255, std=0.3081 * 255),
Pad(2),
ToMode('CHW'),
]),
sampler=RandomSampler(dataset=mnist_dataset, batch_size=64, drop_last=True),
# 训练时一般使用RandomSampler来打乱数据顺序
)
return dataloader
def train():
train_dataloader = pre_data_processing(‘train’)
epochs = 15
le_net = LeNet()
gm = GradManager().attach(list(le_net.parameters()))
for epoch in range(epochs):
if epoch < 5:
lr = 0.05
elif epoch < 10:
lr = 0.02
else:
lr = 0.01
opt = optimizer.SGD(le_net.parameters(), lr=lr)
total_loss = 0
for step, (batch_data, batch_label) in enumerate(train_dataloader):
with gm:
logits = le_net(batch_data)
# logits 为网络的输出结果,label 是数据的真实标签即训练目标
loss = F.loss.cross_entropy(logits, batch_label) # 交叉熵损失函数
gm.backward(loss)
opt.step().clear_grad()
total_loss += loss.numpy().item()
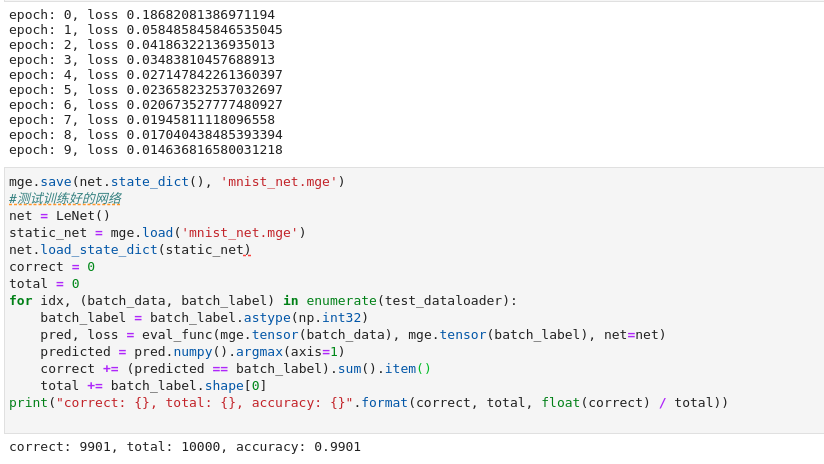
print("epoch: {}, loss {}".format(epoch, total_loss / len(train_dataloader)))
mge.save(le_net.state_dict(), "./lenet.mge")
return './lenet.mge'
def test(net):
test_dataloader = pre_data_processing(‘test’)
le_net = LeNet()
le_net.load_state_dict(mge.load(net))
le_net.eval() # 设置为测试模式
correct = 0
total = 0
for idx, (batch_data, batch_label) in enumerate(test_dataloader):
logits = le_net(batch_data)
predicted = logits.numpy().argmax(axis=1)
correct += (predicted == batch_label).sum()
total += batch_label.shape[0]
print(“correct: {}, total: {}, accuracy: {}”.format(correct, total, float(correct) / total))
程序
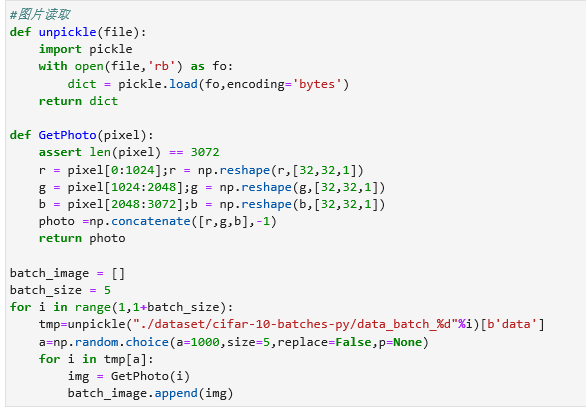

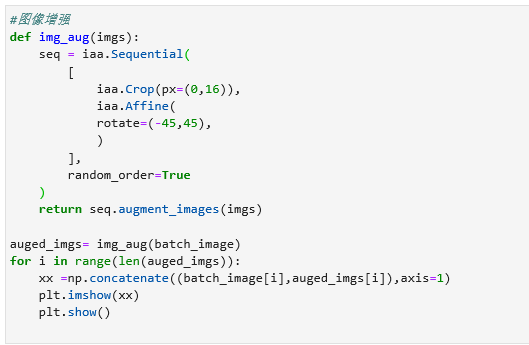
统计结果:
mean_h: 32,mean_w: 32
max_h: 32,max_w: 32
min_h: 32,min_w: 32
此本文本将被隐藏